

Would you like to have all the essential data modeling techniques in one place? Look no further than this comprehensive guide! You’ll find everything you need to build efficient, robust, and scalable databases.
Data modeling techniques are used to carry out data modeling in a methodical and organized manner. But what exactly is data modeling?
The data modeling process is about building data models – an activity that we could compare to building housing complexes (with a little bit of imagination). The difference is that instead of building houses where people will live, data modeling builds structures that will house information. A good basis in math can be helpful when trying to comprehend data modeling. So, if you are still a college student, you should order your math homework on DoMyEssay to boost your understanding and prepare you for more complex concepts.
To build a housing complex, the architect begins by making a sketch of it, showing the shape of the buildings, the location of each one, and the communication between them. Then they move on to designing the floor plans. This establishes the structure of each building: what its functional units will look like, how many rooms they will have, and what those rooms will look like. Once the design is complete, the project can proceed with the construction of the buildings. And once the buildings are finished, the gates of the complex are opened and the inhabitants can enter.
When you apply common data modeling methods, you start by making a sketch or conceptual diagram of the data model, detailing the entities that will shape it and the relationships between them. Then you move to the logical design, which defines the structures of the entities. Logical diagrams show which attributes will give shape to each entity.
Once the logical design has been completed, the physical design proceeds. This transforms the entities into tables and their attributes into columns; it also adds keys, indexes, restrictions, and other elements. Once the physical design is finished, it becomes a database ready to start receiving its inhabitants: the information.
Architects do not always work on new housing developments. Occasionally, they have to remodel an existing complex to adapt it to change and growth in the population. Any changes they make must be done without negatively affecting the complex’s habitability.
Similarly, data modelers must often adapt their models to support the input of new information and new volumes. Whenever they make changes, they must ensure that the model maintains its data integrity, scalability, and efficiency.
When it’s done correctly, data modeling has many benefits. However, some people think that you can directly create or modify a database without doing any prior design work. If you are one of those people, read why you need data modeling before continuing.
Database Schema Modeling Techniques
In describing data modeling work, we mentioned some key elements of this discipline, such as entities, relationships and attributes. This brings us to the most common data modeling methodology: entity-relationship modeling. Read about what an entity-relationship diagram is if you’ve never heard about this methodology. If it seems complicated, don’t panic. Once you master all the database modeling techniques, you’ll realize that database modeling is actually fun.
In ER data modeling, there are several important techniques for database modeling. These techniques help capture and represent the relationships between entities and their attributes using different types of data models (conceptual, logical, and physical). We’ll discuss each of those techniques next.
#1 Creating a Conceptual Model
The creation of a conceptual entity-relationship diagram (often shortened to ER diagram or ERD) is the first of the database modeling techniques applied in the top-down approach to data modeling. The conceptual ERD is generated from the results of a systems analysis. To create it, you must read use cases, user stories, process specifications, and any other information resulting from a systems analysis. This allows you to identify all the entities that will make up the data model. For example:
The salesperson registers a new order, indicating who the customer is, what product was purchased and to which address the order is to be shipped.
To build the conceptual model, you must create an entity-relationship diagram that includes the main entities you have identified. (In the example above, the highlighted words indicate the main candidates for becoming entities). Then you must determine the relationships between them, establishing connections and dependencies.
In a conceptual model, you do not need to go into the detail of attributes, primary keys, foreign keys, indexes, etc. This model is not to be used as a technical document for developers; it is a tool to explain ideas to users, developers, and stakeholders. You can use it to collect feedback and make known the general aspects of the database to be built.
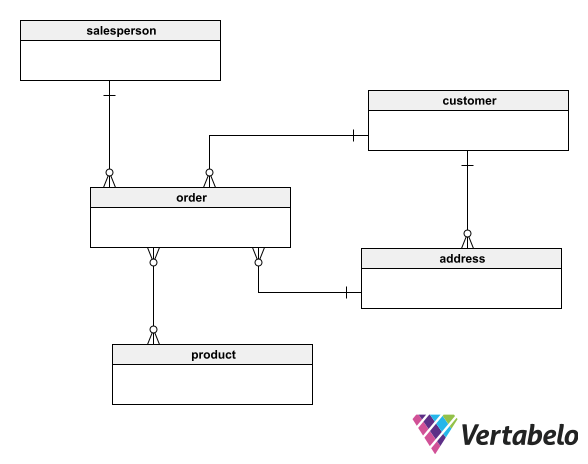
A conceptual database model built from a requirements specification.
#2 Creating a Logical Model
Once the conceptual model you created according to the previous technique has the approval of users, developers, and project stakeholders, you can use it to derive the logical ERD. The logical diagram includes all the same elements as the conceptual model (the main entities and the relationships between them), plus any other entities you need to complete your database. In the logical model, you should detail the attributes that make up each entity.
The results of the analysis stage are also used as input information for this technique. You should review the specification documents and user interviews. You should also use your knowledge of the problem domain to determine the attributes and characteristics that make up the model.
When you have completed this modeling technique, you will have a first approach to the logical diagram of your database. To get to the final logical model, you still need to refine it with the techniques explained below.
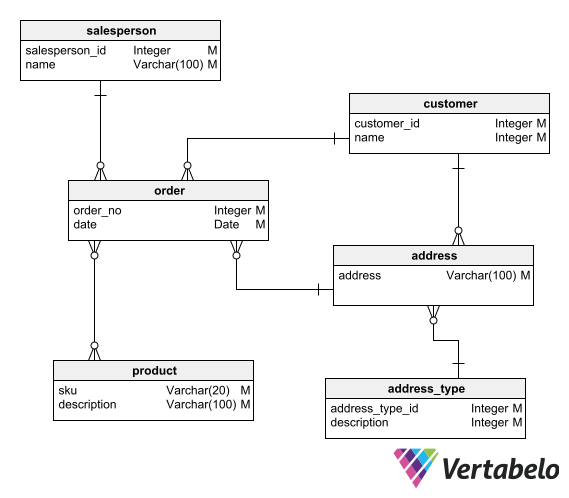
A first approach to the logical model.
#3 Defining Primary Identifiers
To complete a logical data model, it is necessary for each entity to have a primary identifier. The technique of assigning primary identifiers to entities is essential to ensure that each data element is unique and that there are no repetitions that would impair the integrity or consistency of the information.
The primary identifier of an entity is the smallest set of attributes that uniquely identifies each of its data elements. When the logical model is converted to a physical model, the entities become tables and the unique identifiers become the tables’ primary keys.
Every table must have a primary key to allow the unique identification of each row. In turn, the primary keys allow us to establish relationships between tables. We also need them when we apply normalization techniques on schemas.
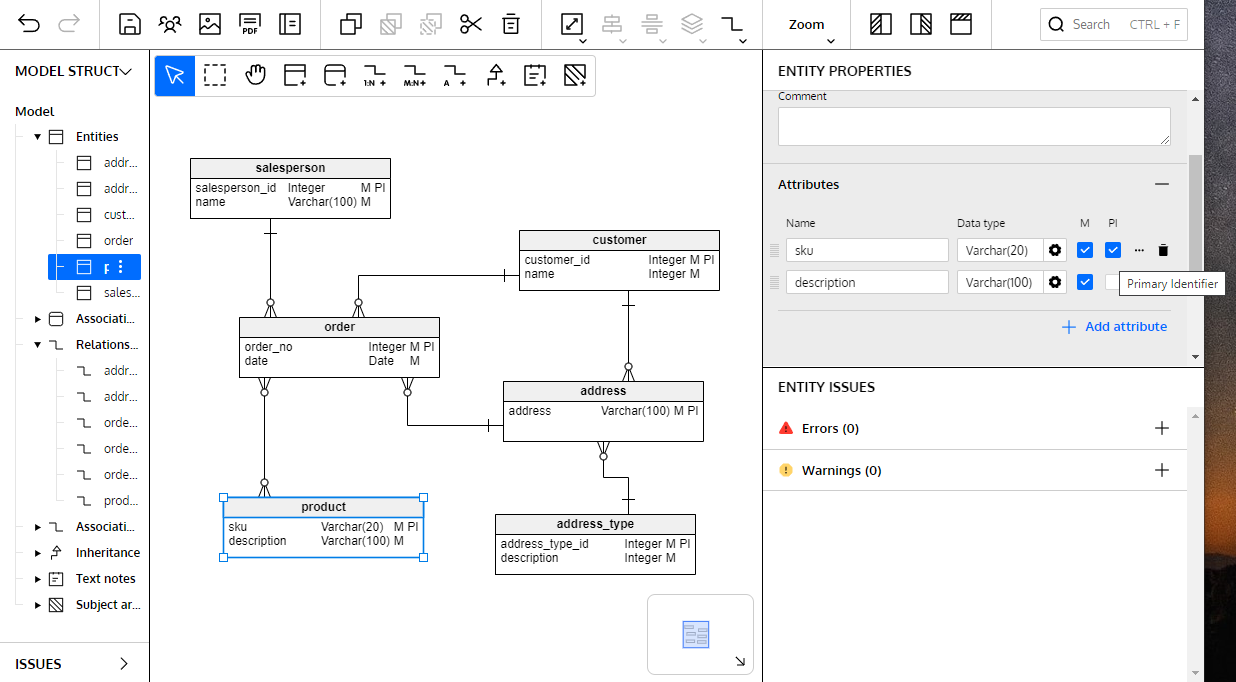
To ensure that each data element in each entity is unique, you must define a primary identifier for each entity.
#4 Normalization
The normalization technique is applied to eliminate redundancies and to ensure the integrity of information in database schemas used for transactional processing. Normalization involves splitting the tables of a schema and reorganizing their attributes, improving their structure to prevent inconsistencies from being generated after insertion, modification, or deletion operations.
Applying normalization to a schema implies incrementally adapting it to the normal forms of database design. There are five normal forms, although in practice only the first three are needed to achieve a sufficient degree of data integrity and consistency. These three normal forms are as follows:
- First normal form (1NF): Each attribute must contain a single indivisible value. If an attribute contains compound data, such as an address consisting of street, city, and country, it must be subdivided into separate attributes: street, city, and country.
- Second normal form (2NF): To bring a schema to 2NF, you must first make sure it is in 1NF. Then, you must eliminate partial dependencies by splitting tables with non-key attributes that depend on part of the primary key. For example, if you have a table with a primary key composed of two attributes and a non-key attribute depends on only one of the attributes of the primary key, then for the schema to be in 2NF you must take the non-key attribute along with the attribute it depends on to a separate table.
- Third normal form (3NF): To take a schema from 2NF to 3NF you must remove transitive dependencies: If an attribute depends on another attribute that in turn depends on the primary key, then you must take that attribute (with its dependent attributes) to a separate table.
For more information, read this article on the first three normal forms.
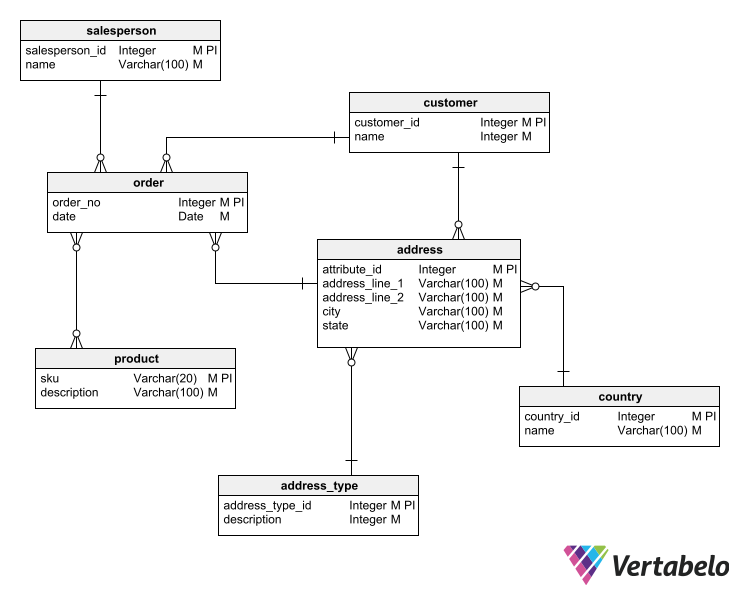
The logical model after normalization techniques are applied.
#5 Denormalization
In schemas that are primarily used for querying and reporting – such as data warehouses where insert, modify or delete operations are automated – normalization rules can be “relaxed” to optimize query performance. For more information, read about when, why, and how you should denormalize a database schema.
Despite its name, denormalizing does not mean completely reversing normalization. It means introducing a certain level of redundancy in the schema to simplify queries and increase their performance. Basically, denormalization seeks to prevent queries on tables with large numbers of rows from having to perform joins with other tables to obtain related data.
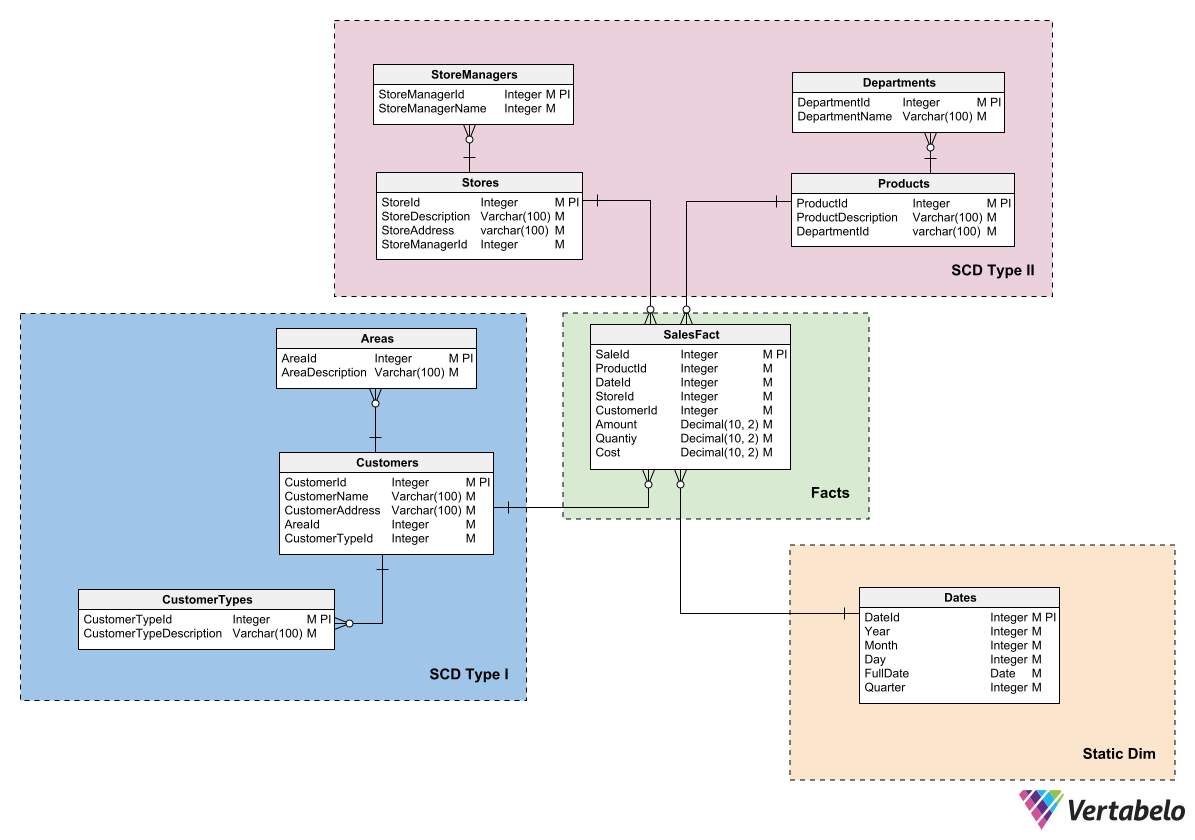
Joining tables during queries is laborious for the database engine. If joins can be avoided, queries become more efficient. For example, if you include a CustomerName column in a fact table that holds sales summary information, you will avoid the need to join it with a Customers table to perform queries. This saves work for the database engine.
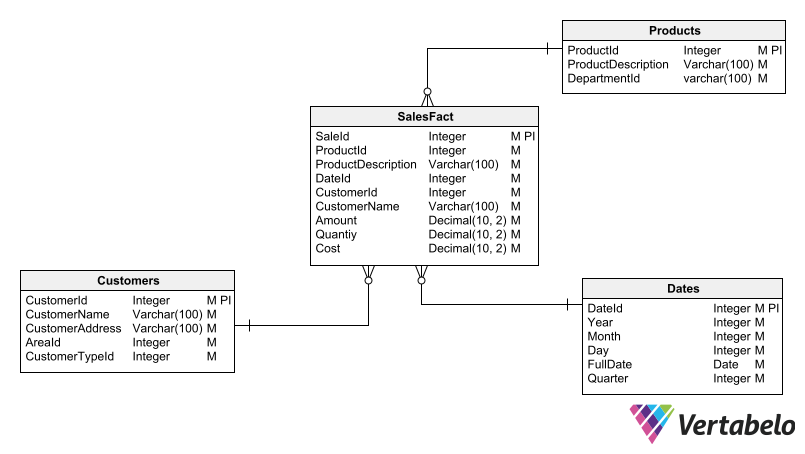
The SalesFact table contains some columns that duplicate information from other tables. These columns remove the need to join the fact table during certain queries.
Note that denormalization carries the risk of creating anomalies in the data update. For example, if you update the customer name in the Customers table but not in the SalesFact table, you run the risk that a sales report will show outdated information. That is why denormalization should be applied with caution and only in situations where you have mitigated its impact on data integrity.
#6 Creating a Physical Model
In the previous techniques, we have seen how to work on a conceptual data model and how to convert it into a logical model. To effectively convert this model into a functional database, you must first convert it into a physical model.
The techniques used to convert a logical model into a physical model require first defining the target database management system, or DBMS. In other words, you choose the specific database engine on which your database will run. This can be Oracle, SQL Server, MySQL, PostgreSQL, or another DBMS.
Then you must convert each entity in the logical model to a table in the physical model. Each entity’s attributes become columns in the corresponding tables. To do this, you will have to adapt the data types of each attribute to a specific data type of the target DBMS. And although most DBMSs use similar data types, not all of them support the same ones.
In addition to defining the data type of each column, you will need to set its integrity constraints – e.g. whether or not it supports null values – and whether it’s the table’s primary key or a foreign key in a relationship with another table.
If you use a specific database design tool like Vertabelo, the conversion from the logical model to the physical model is reduced only to choosing the target DBMS; the rest of the work is done automatically by the platform.
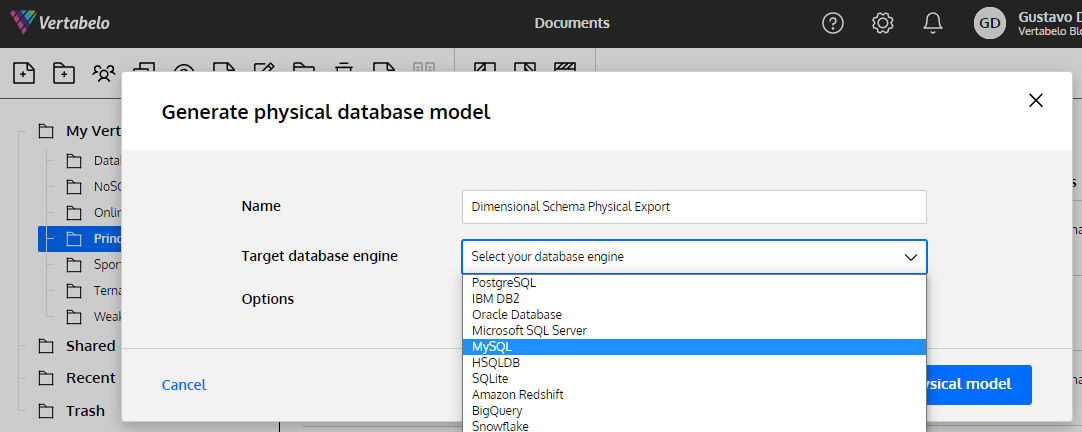
You can let Vertabelo take care of all the details needed to convert any logical model into a physical model.
#7 Optimizing the Physical Model
If you have applied the normalization or denormalization techniques (depending on the type of database) seen above, then your physical model is already pretty much optimized. However, there are other things you can do to make your physical model even more efficient in terms of database operation response times and server resource usage. Some of these things are index creation, view creation, and schema partitioning.
Creating Indexes
Index creation is often used in the maintenance of operational databases. However, it can also be done proactively, anticipating the needs of users and applications in terms of the queries they will need to make. By analyzing requirements documents (such as use cases and user stories), you can infer the need to create indexes on columns used as filters in queries or in search or grouping criteria.
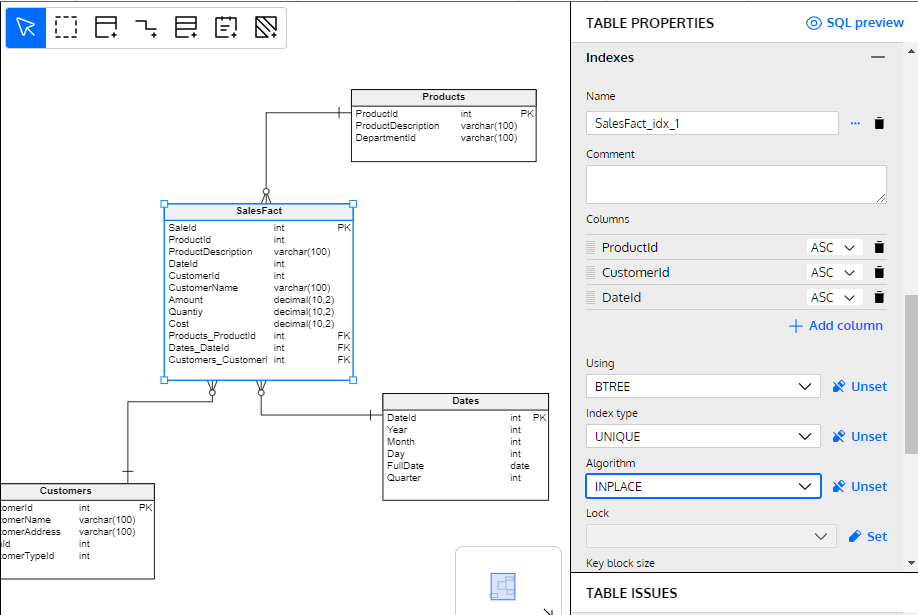
While working on the design of your physical schema, you can proactively create indexes that ensure good query performance from the start.
Creating Views
Another way to optimize your database design is to create views that simplify the task of writing queries. Views are one way to do this; they are virtual representations of one or more tables that encapsulate complex queries so that these queries can be used as if they were tables.
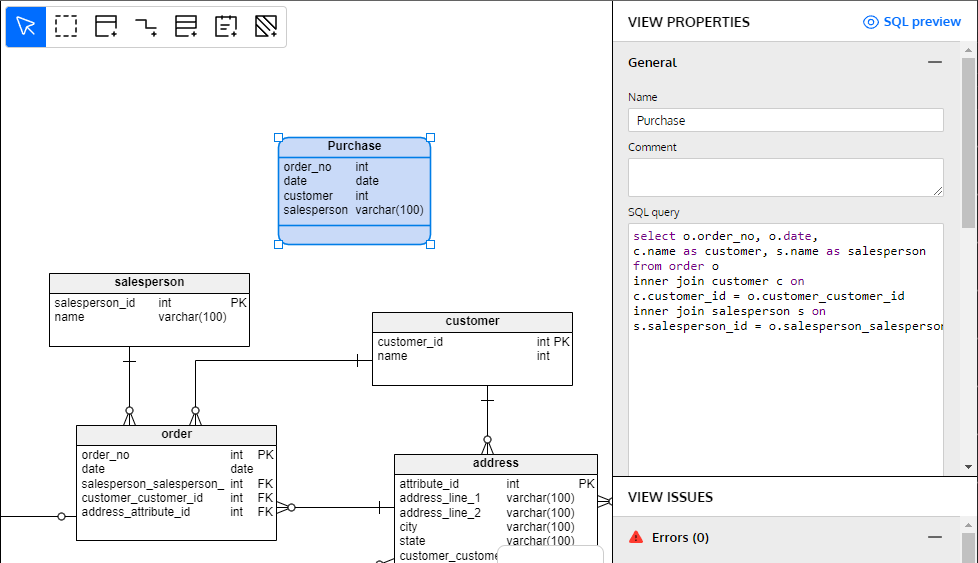
When you design a database model, you can add views to it to proactively simplify database users’ work.
Views provide multiple advantages, such as abstraction and simplification, hiding sensitive data, data unification, and performance improvement. It is very useful to have a view editor integrated into your data modeling tool so you won’t need to switch tools when creating views during the design process.
Schema Partitioning
Schemas can have a large number of tables or have tables that differ greatly in terms of their usage. For example, some tables may be constantly updated, while others are never updated. In both of these cases, partitioning is a valid technique for schema optimization.
A partitioned schema can be distributed among different storage media or even among different servers, making optimization techniques such as parallelism or load sharing possible. In addition, a partitioned schema is more scalable and improves database availability; if one partition fails, the others can continue to provide service.
In a data warehouse schema, partitions can separate different types of tables to better manage server resources and give a clearer view of schema design.
The ability to distribute the elements of a database model among different partitions is a desirable feature in a database design tool, since it allows partitioning schemas graphically on an ERD. In the same way that creating views makes work easier for database users, defining partitions makes the job easier for database administrators (DBAs).
#8 Modeling Techniques for Non-Relational Databases
The techniques listed so far apply primarily to relational databases. But there are other database modeling approaches besides entity-relationship data modeling. If you must build a non-relational (or NoSQL) database, your approach and modeling techniques will vary. Let’s see a very high-level summary of the modeling techniques applicable to different types of databases.
Dimensional Databases
These are a special case of relational databases, since they use the same table structures, attributes, relationships, keys, and indexes as relational databases. However, their intention is to optimize analytical queries on large volumes of data. Dimensional databases are oriented to business intelligence applications, data analysis, and analytical dashboards.
The modeling techniques of dimensional databases produce data models based on two basic types of tables: fact tables and dimension tables. Fact tables contain the numerical metrics (called measures) that you want to analyze – e.g. sales volumes, quantities sold, employee salaries, and check stubs for detailed payroll information. Fact tables also include foreign keys to dimension tables, which contain descriptive attributes that give context to the metrics in the fact tables. Some common dimensions include time, product, product family, customer, geographical area, etc.
For more information on dimensional databases, read about the 5 common mistakes in dimensional modeling and how to solve them.
Hierarchical Databases
In hierarchical databases, data is organized in a tree-like structure, where each record has a single parent record and may have several child records. Relationships between records are established by pointers and are generally similar to the one-to-many relationships of relational databases. There may also be one-to-one relationships in particular cases, using direct pointers between related records.
Access and navigation techniques are essential in hierarchical databases to traverse and access records in the data structure. Special commands and operations are used to navigate to the root or leaves of the tree.
Hierarchical data structures are less flexible than other database models; their use is particularly prominent in document-oriented database management. Table indexes in relational databases are often implemented as hierarchical structures (each index is a hierarchical tree), taking advantage of their versatility for searching and navigation.
Network Databases
The modeling techniques used to build network databases represent complex relationships between records. Commonly, these databases are modeled as networks, where each record is a node and the relationships with other nodes are represented by links or arcs. These links can have properties. For example, a link between a Customer record and a Product record may have a Quantity property that indicates the number of products purchased by a customer.
As in hierarchical databases, pointers are used in network data models to link related records and to allow navigation through them. Navigational queries access and retrieve data, using operations such as “next” and “skip” to traverse network-like structures in search of specific records.
Document Databases
These databases aim to store data elements that do not have a common structure; that’s why each data element takes the form of a document. Generally, JSON or XML standards are used to store information in semi-structured documents; these can be key-value pairs or have more complex formats, such as lists, arrays, or even nested documents. This lack of a fixed structure gives document databases greater flexibility than relational databases, as each record can contain a different set of attributes.
A particular technique of document databases is selective denormalization to improve query performance. This technique is based on including redundant data in a single document, thus avoiding the need to join multiple documents in frequent queries.
Indexes are also used to gain efficiency in searching and retrieving data. These can be based on keys, specific attributes, or textual content.
Each different document database implementation offers its own query and search languages, such as MongoDB Query Language or Elasticsearch Query DSL.
Wide-Column Databases
In column-oriented databases, denormalized schema design techniques are used. Under this approach, data is stored in individual columns instead of occupying entire rows. This allows greater flexibility in data structure and results in greater efficiency in analytical queries; data can be partitioned into distributed nodes that enable parallelism and horizontal scalability.
Two other important techniques employed in columnar database modeling are the creation of columnar indexes and the use of projections and materialized views. Columnar indexes are optimized to perform searches on specific columns, improving performance in analytical and filtering queries. The use of projections and materialized views allows users to precompute and store the result of frequent queries. This significantly speeds up the processing time on these queries and reduces the load on the database engine.
Object-Oriented Databases
Object-oriented database modeling employs the techniques of object-oriented design, such as inheritance, polymorphism and the encapsulation of data and methods. This type of database mitigates the need to perform object-relational mappings (ORM) to provide data persistence, since it supports direct persistence of objects in the database. Objects can be stored, retrieved, and modified in the database without the need for conversions or transformations.
Queries and operations with object-oriented databases can be done directly from object-oriented languages such as Java or C#. No translation to traditional query languages like SQL is necessary; with these databases, object-oriented programming languages acquire the ability to manipulate persistent objects. Among the most popular object-oriented NoSQL databases are MongoDB and CouchDB.
Wrapping Up Database Modeling Techniques
We have explored a wide range of database modeling techniques and approaches, from conceptual modeling to physical database design. We have learned the importance of understanding business requirements, identifying key entities and relationships, and applying sound methodologies to structure and organize data in a consistent manner. In addition, we have examined advanced modeling techniques (such as normalization and denormalization) and query performance optimization.
By adopting the practices and strategies covered in this article, you will be able to create robust and flexible databases that can adapt to the changing demands of organizations and enable informed decision-making. If you’d like to learn more about database modeling techniques and tools, I suggest the following articles:
- The 9 Most Common Database Design Errors
- What Is a Database Modeling Tool?
- What Is the Best Online Database Diagram Tool?
And don’t forget to check the database modeling techniques section of our blog to keep your information current!
