

When you don't have a guide, certain tasks seem more difficult than they really are. In this article, I offer you a complete database design guide so you won’t get lost when trying to build a robust and effective database.
A database schema is basically an abstract concept. Even so, it’s better to think of it as a practical tool that helps you create structures to turn large amounts of data into something useful. In the process of designing a database, creating the diagrams and transforming them into a functional database is only the final step; the majority of the work starts much earlier.
The work of an SQL data modeler begins with a planning phase. In that phase, object discovery will shape the whole design. It will be the basis for all the necessary details to turn the design into a functional database.
The input elements for the planning stage are the results of the requirements engineering process. These results commonly take the form of narrative descriptions of how a system should behave. As the system analysis proceeds, other design artifacts – such as user stories, use cases, sequence diagrams, etc. – may emerge. Thus, our first step in database design is to find (in all this documentation) the objects for which information needs to be stored.
Wondering about all the steps in database design? Read this article on the 5 steps for an effective database model to get an overview of the whole process.
The Database Design Guide, Part 1: Planning
The most convenient and common way to create a data model is to go from general to particular while following the steps of database design. Following this path, you'll come across three different types of models: conceptual, logical, and physical data models.
Using the elements identified during the planning stage, you can outline a conceptual data model and use it to obtain initial validation from users and stakeholders. In the conceptual model, we normally include the main data entities and the main relationships between them. This is so that the usefulness of the data model can be broadly understood. You can think of entities, attributes, and relations as the necessary ingredients to prepare a database model.
According to our database design guide, once the conceptual model has been validated, we can expand the level of detail of the diagram and build the logical model with our data modeling tool. This model will show all the entities with all their attributes, and all the existing relationships between them. We also distinguish the different types of relationships (1-to-1, 1-to-many, many-to-many, inheritance or generalization/specialization) and the generic data type (i.e. integer, decimal, date, time, varchar, etc.) of each attribute.
The logical model should guide the development and evolution of the schema during the lifecycle of the software solution of which it is a part. Its independence from any particular RDBMS keeps it valid even when the data repository changes between different environments or technologies. That is why it is highly recommended to do all the design work on the logical schema using a database diagram tool and convert it into a physical schema only when it is necessary to “give life” to it. Then, you’ll be able to populate it with data and attach it to a software solution.
In the physical diagram, the schema structure is defined according to the peculiarities of a given relational database management system (RDBMS). This means that the data types of a table’s columns are no longer generic, but specific to the target RDBMS. In addition, relationships between entities become constraints between columns of the tables involved and inheritance or generalization/specialization relationships become sets of tables and constraints between fields in them.
Let’s check out some tips for better database design and see how this way of working is brought to reality with a practical example.
The Database Design Guide, Part 2: Design the Model
Suppose you need to create a database schema for a theatre ticket booking app. Since the app doesn’t exist yet, you must initially rely on a narrative description of its behavior. For example:
Customers select the play for which they wish to book a ticket. The app displays the show times for the selected play along with its synopsis, cast, director(s), ticket prices, and any other relevant information. Customers choose a date and time from the available show times. The app shows the availability of seats for the chosen date and time. Customers select the seats to book. The app shows the total price of the booked seats and refers the customer to the payment and check-out module.
1. Identify Entities
To build a schema design that fits the described system, you must pay attention to the objects mentioned in the previous description. A first reading allows you to identify the following objects:
- Customer
- Play
- Actor
- Director
- Synopsis
- Ticket
- Show Time
- Seat
- Price
With some knowledge of the app’s logic and the list of objects above, you can use a database diagram tool to outline a conceptual model. Remember, this model shows the main entities and the main relationships between them:
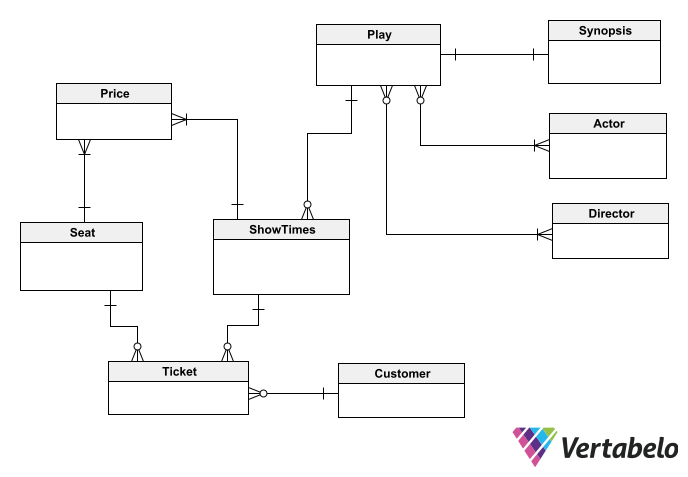
The conceptual model shows the main entities of our schema and the main relations between them.
This conceptual diagram will be used to discuss the model with customers and stakeholders to make sure it is correct. Having validated the conceptual model, you can convert it into a logical diagram. To do so, you must add attributes (and their respective data types) to each entity.
It is important not to expect your model to be perfect at this stage. It is very likely that you will have to make many changes to your logical diagram before you can convert it into a physical diagram – and, finally, into a database schema.
Modern development teams usually employ Agile development methodologies; these put adapting to change as a top priority. In database schema design, the principle of agility and adaptability to change goes hand-in-hand with the use of an intelligent database design tool like Vertabelo. Such tools give a lot of flexibility to the design process. This includes the ease of modifying a diagram as well as applying those modifications to a live database without the risk of losing data or breaking productive applications or processes.
2. Adding Attributes to Entities
To add attributes to entities, go through the objects in the conceptual diagram and think about what information you need for each of them. You can leverage the narrative descriptions of the system, your own knowledge of the app domain, and information provided by users and stakeholders.
In the ticket booking system, you can list the following objects to start outlining entities, attributes, and relations:
- Customer: Name, Telephone number.
- Play: Title, Duration, Genre, Synopsis, Director/s, Actors, Show Times, Prices.
- Ticket: Customer, Play, Show Time, Seats
The next step is to enter the attributes of each entity and assign a data type to each one. It is important to use a tool that provides enough flexibility and lets you easily move objects around, link/unlink them, add and remove attributes, etc. The right schema design might begin to take shape in your head as you draw it out. (At least, that’s the way it works for me.)
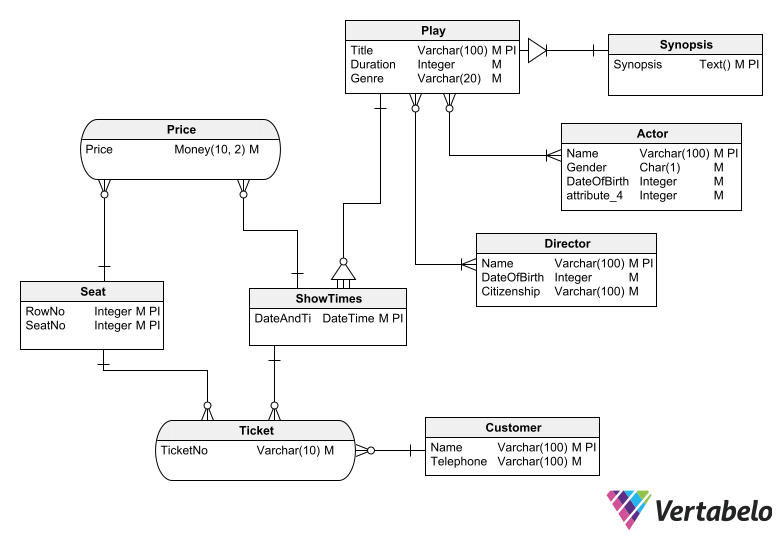
Don’t worry about your design being perfect on the first try. It’s better to have a tool that makes it easy to make as many changes as needed.
Remember that each entity must have a unique identifier – one or more attributes that will identify each row of the table univocally when the schema becomes a working database.
When defining a unique identifier for each entity, ask yourself if it could be useful to use a surrogate (or artificial) key to function as a unique identifier. To make this decision, consider if the identifying attributes are prone to frequent changes, if they are defined as complex data types, and so on.
3. Add Relationships Between Entities
Once all the entities with their attributes have been drawn, you can establish the relationships between them. These relationships should reflect the relationships that exist between the objects in the real world. Some entities may become attributes of other entities during this process, i.e. when you find out that a 1-to-1 relation doesn’t make sense between two tables. To clarify this concept, you can read about the difference between entities and attributes in a data model.
Normalization
Depending on the use you want to make of the data, the previous diagram can be improved. These improvements are achieved by normalizing the schema – that is, by modifying it according to the normal forms established by the relational model.
Normalization will save you from inconsistencies in the data, such as having a reservation for a play on a date or time when that play is not shown or having two reservations for the same seat at the same time.
In addition, applying normalization techniques can make your schema more versatile for querying – e.g. if you want your database to be able to inform a user of all the plays in which a certain actor is working, all the plays directed by a certain director, or all the plays that will be shown within a range of dates.
Once corrected, your schema might look like this:
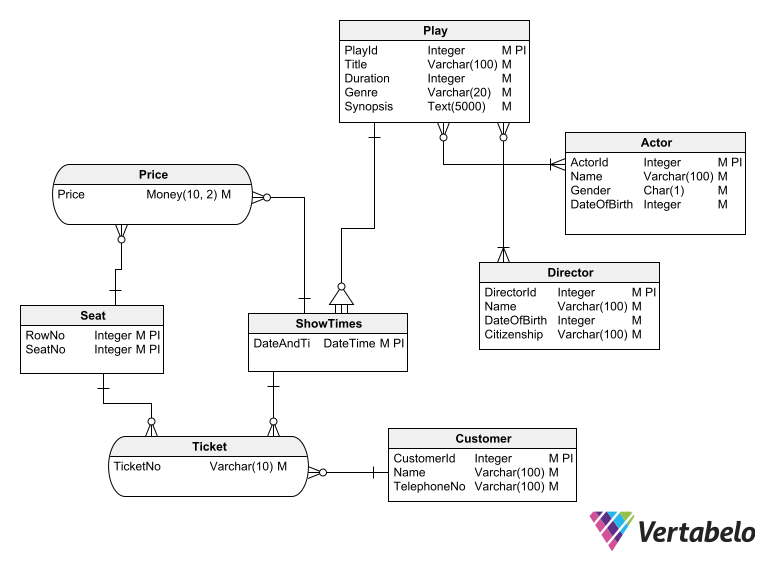
After a couple of design iterations, you should arrive at a schema design that will efficiently solve any requirements of the app.
Model Validation
When you use a drawing tool to design your database schema, you can make mistakes that will make it difficult to implement that design on a database management system (DBMS) later on. You might unknowingly assign the same name to two tables, create a table without a primary key, or have a foreign key relationship between two columns of different data types.
If you use Vertabelo to design your database schema, the risk of missing errors like these is reduced to zero. This is because Vertabelo validates your model as you work on it; if it finds any flaws, it shows them to you in a panel with a warning icon so that they don’t go unnoticed.
4. Preparing the Physical Schema
The step before implementing the schema design on a DBMS to get it up and running is to create a physical diagram. Using Vertabelo, you can derive the physical diagram from the logical schema automatically. In fact, the process of getting the physical diagram from a logical one takes only a few seconds. It is just a matter of choosing a logical diagram and giving Vertabelo the command to convert it into a physical diagram.
The conversion from logical to physical requires you to choose a target database engine and verify that there are no errors in the diagram (using the same validation tool). Vertabelo will then create a physical schema. To do this, entities and associations in the logical schema are converted into tables in the physical schema, and relationships between entities in the logical schema are converted into foreign key constraints in the physical schema. For more information, read this article on how to generate a physical diagram from a logical one in Vertabelo.
In a physical schema, all foreign key constraints should have an index that improves query performance. Vertabelo will issue a warning if you don’t. It’s also important to be clear about what a database index is and what it is used for.
Other elements of the physical schema – such as views and various SQL scripts – can be added in Vertabelo before implementing the schema on a DBMS. This ensures that all the elements needed to create the database are included with the schema.
To create the database, simply ask Vertabelo to generate the necessary SQL scripts and then run them on the chosen DBMS.
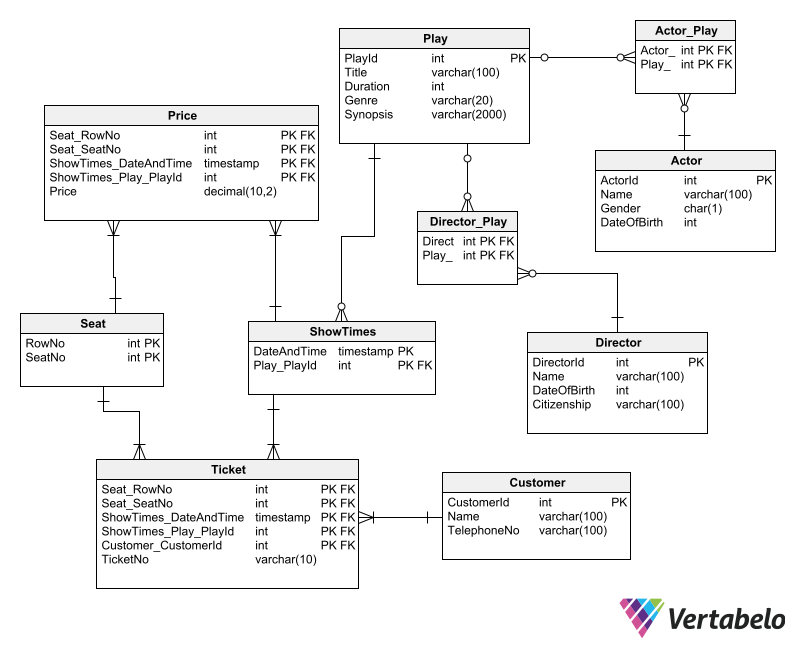
In Vertabelo, a physical schema is much more than meets the eye. It includes indexes and SQL statements that, once you convert it into a database, will require practically no tweaking under the hood.
Best Practices for Database Schema Design
The following set of best practices will help your database schema retain its usefulness throughout the whole lifecycle of the application it supports. To better organize your database diagrams, you may want to read about Vertabelo’s shortcut tables and how to use them effectively and how to add references to entity-relationship diagrams in Vertabelo.
Naming Conventions
It may seem trivial, but proper naming conventions are extremely important for an effective database schema. It’s less important which naming convention you use; what is critical is to choose one and stick to it at all times. Keep in mind that you will not be the only one creating objects in your database schema. It is vital to specify the naming convention used in your database schema and make it known to everyone who works with the database.
It is also critical to clearly establish the naming convention used in a database schema before you start populating it with objects – and especially before implementing the schema in a DBMS. Once the database is operational, any name change can be catastrophic.
Regarding object names, avoid using reserved words in table names, column names, indexes, etc. at all costs. Also avoid using special characters, spaces, inverted commas, hyphens, or language-specific letters. The use of such characters forces the use of delimiters when referring to those tables or columns in SQL statements, which adds yet another cumbersome task for the database programmer.
An important part of defining a naming convention is whether to use plural or singular for table names. Some argue that a table representing an entity should have a singular name – e.g. Customer instead of Customers. But this is just a matter of preference; what is really important is to adopt a criterion and always stick to it.
The use of prefixes or suffixes in table and column names is discouraged. It may seem useful to add (for example) a prefix denoting the data type of a column. But over time, the uselessness of this rule becomes apparent and everyone stops using it. This creates confusion due to the coexistence of names with and without prefixes.
The use of unnecessary descriptors in names is also discouraged. There is no need, for example, for a customer table to be called CustomerTable or CustomerList. It is sufficient if it is called Customer or Customers (depending on the plural/singular convention adopted).
Security Policies
As designers, we may fall into the error of believing that our databases will always be well protected from any risk of data loss or theft. However, a good security practice is based on always considering the possibility of a malicious user managing to circumvent all defense mechanisms and gaining free access to the data.
Database designers must apply mechanisms that serve as the last line of defense against unauthorized access to the information. A popular one is the encryption of sensitive data, such as passwords, credit card numbers, or personally identifiable information (such as a personal ID number). In your schema design, columns with sensitive information should be able to store encrypted information. You may also want to employ sub-schemas for proper user authentication.
Documentation
Once an application goes into production, its database schema can remain stable for a long time – and, for long periods of time, no one needs to view its schema. But sooner or later the need will arise to make some changes to the application or the data model. Then it will be necessary to revisit the design diagram to modify it and work on the changes to the data model. But the people who need to do this work may not be the same people who designed the database. Or even if they are the same people, they may not remember why they made certain design decisions.
In these situations, the documentation of a database schema becomes essential. The simplest and most effective way to document a data model is to accompany diagrams with annotations and explanatory text; they can guide the person who has to analyze it long after it has been created. Vertabelo allows you to add text notes to your diagrams in sticky-note style, which is a valuable aid to designers who need to understand why you related two tables or why you assigned a certain data type to a column.
You Can Design a Robust Database Schema!
If you carefully follow this guide to good database design, you will substantially improve the quality of your database schema. As a result, you will also contribute to improving the quality of the software that uses your schemas. The bottom line is that your database designs will be robust and durable, and that they will make life easier for everyone on the development team who has to work with them.
