

Databases are designed in different ways. Most of the time we can use “school examples”: normalize the database and everything will work just fine. But there are situations that will require another approach. We can remove references to gain more flexibility. But what if we have to improve performance when everything was done by the book? In that case, denormalization is a technique that we should consider. In this article, we’ll discuss the benefits and disadvantages of denormalization and what situations may warrant it.
What Is Denormalization?
Denormalization is a strategy used on a previously-normalized database to increase performance. The idea behind it is to add redundant data where we think it will help us the most. We can use extra attributes in an existing table, add new tables, or even create instances of existing tables. The usual goal is to decrease the running time of select queries by making data more accessible to the queries or by generating summarized reports in separate tables. This process can bring some new problems, and we’ll discuss them later.
A normalized database is the starting point for the denormalization process. It’s important to differentiate from the database that has not been normalized and the database that was normalized first and then denormalized later. The second one is okay; the first is often the result of bad database design or a lack of knowledge.
Example: A Normalized Model for a Very Simple CRM
The model below will serve as our example:
Let’s take a quick look at the tables:
- The
user_accounttable stores data about users who login into our application (simplifying the model, roles, and user rights are excluded from it). - The
clienttable contains some basic data about our clients. - The
producttable lists products offered to our clients. - The
tasktable contains all the tasks we have created. You can think of each task as a set of related actions towards clients. Each task has its related calls, meetings, and lists of offered and sold products. - The
callandmeetingtables store data about all calls and meetings and relates them with tasks and users. - The dictionaries
task_outcome,meeting_outcomeandcall_outcomecontain all possible options for the final state of a task, meeting or call. - The
product_offeredstores a list of all products that were offered to clients on certain tasks whileproduct_soldcontains a list of all the products that client actually bought. - The
supply_ordertable stores data about all orders we’ve placed and theproducts_on_ordertable lists products and their quantity for specific orders. - The
writeofftable is a list of products that were written off due to accidents or similar (e.g. broken mirrors).
The database is simplified but it’s perfectly normalized. You won’t find any redundancies and it should do the job. We shouldn’t experience any performance problems in any case, so long as we work with a relatively small amount of data.
When and Why to Use Denormalization
As with almost anything, you must be sure why you want to apply denormalization. You need to also be sure that the profit from using it outweighs any harm. There are a few situations when you definitely should think of denormalization:
- Maintaining history: Data can change during time, and we need to store values that were valid when a record was created. What kind of changes do we mean? Well, a person’s first and last name can change; a client also can change their business name or any other data. Task details should contain values that were actual at the moment a task was generated. We wouldn’t be able to recreate past data correctly if this didn’t happen. We could solve this problem by adding a table containing the history of these changes. In that case, a select query returning the task and a valid client name would become more complicated. Maybe an extra table isn’t the best solution.
- Improving query performance: Some of the queries may use multiple tables to access data that we frequently need. Think of a situation where we’d need to join 10 tables to return the client’s name and the products that were sold to them. Some tables along the path could also contain large amounts of data. In that case, maybe it would be wise to add a
client_idattribute directly to theproducts_soldtable. - Speeding up reporting: We need certain statistics very frequently. Creating them from live data is quite time-consuming and can affect overall system performance. Let’s say that we want to track client sales over certain years for some or all clients. Generating such reports out of live data would “dig” almost throughout the whole database and slow it down a lot. And what happens if we use that statistic often?
- Computing commonly-needed values up front: We want to have some values ready-computed so we don’t have to generate them in real time.
It’s important to point out that you don’t need to use denormalization if there are no performance issues in the application. But if you notice the system is slowing down – or if you’re aware that this could happen – then you should think about applying this technique. Before going with it, though, consider other options, like query optimization and proper indexing. You can also use denormalization if you’re already in production but it is better to solve issues in the development phase.
What Are the Disadvantages of Denormalization?
Obviously, the biggest advantage of the denormalization process is increased performance. But we have to pay a price for it, and that price can consist of:
- Disk space: This is expected, as we’ll have duplicate data.
- Data anomalies: We have to be very aware of the fact that data now can be changed in more than one place. We must adjust every piece of duplicate data accordingly. That also applies to computed values and reports. We can achieve this by using triggers, transactions and/or procedures for all operations that must be completed together.
- Documentation: We must properly document every denormalization rule that we have applied. If we modify database design later, we’ll have to look at all our exceptions and take them into consideration once again. Maybe we don’t need them anymore because we’ve solved the issue. Or maybe we need to add to existing denormalization rules. (For example: We added a new attribute to the client table and we want to store its history value together with everything we already store. We’ll have to change existing denormalization rules to achieve that).
- Slowing other operations: We can expect that we’ll slow down data insert, modification, and deletion operations. If these operations happen relatively rarely, this could be a benefit. Basically, we would divide one slow select into a larger number of slower insert/update/delete queries. While a very complex select query technically could noticeably slow down the entire system, slowing down multiple “smaller” operations should not damage the usability of our application.
- More coding: Rules 2 and 3 will require additional coding, but at the same time they will simplify some select queries a lot. If we’re denormalizing an existing database we’ll have to modify these select queries to get the benefits of our work. We’ll also have to update values in newly-added attributes for existing records. This too will require a bit more coding.
The Example Model, Denormalized
In the model below, I applied some of the aforementioned denormalization rules. The pink tables have been modified, while the light-blue table is completely new.
What changes are applied and why?
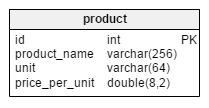
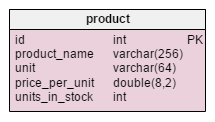
The only change in the product table is the addition of the units_in_stock attribute. In a normalized model we could compute this data as units ordered – units sold – (units offered) – units written off. We would repeat the calculation each time a client asks for that product, which would be extremely time consuming. Instead, we’ll compute the value up front; when a customer asks us, we’ll have it ready. Of course, this simplifies the select query a lot. On the other hand, the units_in_stock attribute must be adjusted after every insert, update, or delete in the products_on_order, writeoff, product_offered and product_sold tables.
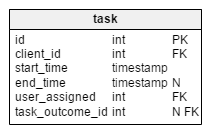
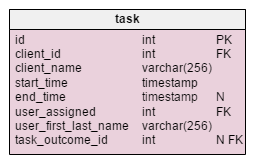
In the modified task table, we find two new attributes: client_name and user_first_last_name. Both of them store values when the task was created. The reason is that both of these values can change during time. We’ll also keep a foreign key that relates them to the original client and user ID. There are more values that we would like to store, like client address, VAT ID, etc.




The denormalized product_offered table has two new attributes, price_per_unit and price. The price_per_unit attribute is stored because we need to store the actual price when the product was offered. The normalized model would only show its current state, so when the product price changes our ‘history’ prices would also change. Our change doesn’t just make the database run faster: it also makes it work better. The price attribute is the computed value units_sold * price_per_unit. I added it here to avoid making that calculation each time we want to take a look at a list of offered products. It’s a small cost, but it improves performance.
The changes made on the product_sold table are very similar. The table structure is the same, but it stores a list of sold items.
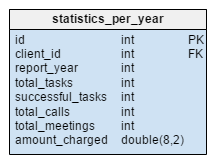
The statistics_per_year table is completely new to our model. We should look at it as a denormalized table because all its data can be computed from the other tables. The idea behind this table is to store the number of tasks, successful tasks, meetings and calls related to any given client. It also handles the sum total charged per each year. After inserting, updating, or deleting anything in the task, meeting, call and product_sold tables, we should recalculate this table’s data for that client and corresponding year. We can expect that we’ll mostly have changes only for the current year. Reports for previous years shouldn’t need to change.
Values in this table are computed up front, so we’ll spend less time and resources at the moment we need the calculation result. Think about the values you’ll need often. Maybe you won’t regularly need them all and can risk computing some of them live.
Denormalization is a very interesting and powerful concept. Though it’s not the first you should have in mind to improve performance, in some situations it can be the best or even the only solution.
Before you choose to use denormalization, be sure you want it. Do some analysis and track performance. You’ll probably decide to go with denormalization after you’ve already gone live. Don’t be afraid to use it, but track changes and you shouldn’t experience any problems (i.e., the dreaded data anomalies).
