

Why are database modeling tools so important? What data modeling features should you look for? Get the answers here.
A database modeling tool helps users capture and explain a domain – i.e. the entities, attributes, relationships between entities, and any rules that apply to the entities and attributes. That, of course, is the most basic feature. Most data modeling tools provide many more features.
Imagine that you’ve joined a project where the database design process has just begun. A few entities/tables have been created. There are two ways of understanding the existing design.
- Use a command line tool like psql for PostgreSQL.
- Use a visual database modeling tool like Vertabelo.
Below we have an example of what each option looks like on a data model containing seven tables:
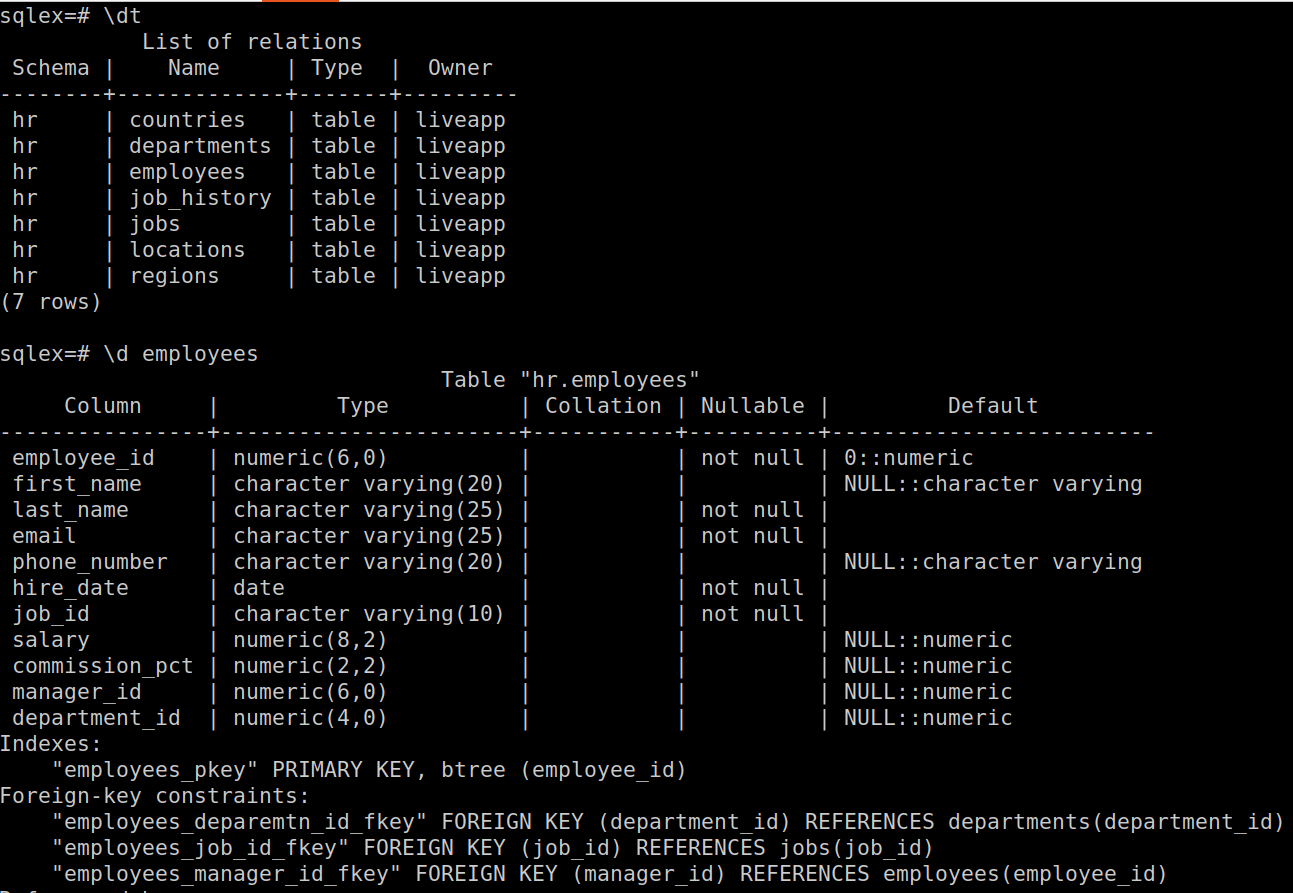
Command-line data modeling with psql
Visual data modeling with Vertabelo
The advantage of having a visual representation of a data model is evident. Even small systems will have many more than seven tables; trying to understand entity relationships and constraints from database metadata gets only more difficult as a system grows
So, we know that data modeling tools are used to design data models, which will later become databases. Let’s look at some of the features you might need in a data modeling tool.
Database Modeling Tool Features
The data modeling process involves multiple steps, i.e. moving from simple to detailed models. As you move from one model to the next, you can also go from defining basic data types to database-specific types.
Obviously, the ability to define data types is essential to data modeling. Data types describe the type of data stored in a column. If you’re new to this concept, start with the article Data Types in SQL for an overview.
A good database modeling tool will let you choose the database (MySQL, PostgreSQL, Oracle, etc.) and then give you an option to choose data types specific to that database. After this step is complete, the tool lets us generate a DDL (Data Definition Language) script that can be used to create the schema and the objects in the database.
Now let’s consider some specific features that data modelers find handy.
Share/Export Your Model
A data modeling tool will probably not be used just to create a basic data model so you can walk others through the domain. It will be used to develop full-featured entity-relationship diagrams and eventually to create databases.
In many cases, multiple people will need to work on the data model. Thus, sharing the model is a basic feature for data modeling tools. Depending on the tool, you may be able to publish the model to a URL and share the link with others or export the model in various formats (pdf, html, xml, image) and share the export output.
In Vertabelo, you can export a data model as an image, a PDF, a shareable URL, or an SQL file.
Import/Reverse Engineer a Database
Database designers may start off by creating a few tables directly in the database. Then they realize that explaining the schema to others without a diagram will be difficult, so they switch to a database modeling tool. In such situations, the ability to generate models using reverse engineering (or importing the data model from a database) saves a lot of time.
The exact import or reverse engineering mechanism depends on the tool. Some tools let you connect to the database and generate the model directly from the tool. Others require you to first generate an SQL or XML dump of the database, which the tool will use to reverse engineer the data model.
In Vertabelo, you can reverse engineer or import an existing data model to the tool.
Diff/Delta Scripts
A database model is never static; users request features and changes, and the data model keeps evolving. Database changes are deployed as DDL scripts, which create new tables, alter existing tables, modify constraints and so on. These changes are first applied to the logical and physical data model using the database modeling tool. Once this activity is complete, a good database modeling tool will let the database designer connect to the production database and generate “diff” or “delta” scripts. These scripts will contain the necessary SQL commands to modify the production database so that it is in sync with the physical data model.
Once in a while, something may go wrong with the production deployment. In such situations, a rollback of the database changes is necessary. Some database modeling tools let us generate a rollback script along with the deployment script. Vertabelo lets you automatically and easily generate diff/delta scripts.
Version Control
Source control (or version control) is an essential activity for both front-end and back-end development teams. Typically, the tools dev teams use (Git, CVS, SVN, Mercurial, etc.) are very sophisticated. They provide basic features like rolling back and merging changes as well as advanced features like automated continuous integration and continuous deployment.
Database-centric tools have mostly lacked such sophistication. You could generate the DDL scripts, check them in the back-end version control system, and tag them to the corresponding branches. If a database modeling tool provides a version control system, with functionality similar to the above-mentioned tools, that is great. Vertabelo’s built-in version control system uses text files that are easy to add to Git repositories.
Comment/Annotate
Document management software usually lets users comment and annotate – a very useful feature. At one level, database models are documents (we use them to explain the domain); and at another level, they’re source (we deploy the DDL scripts in production). So it’s very useful if a database modeling tool supports both levels.
For example, I once was on a project where there was an issue that took a long time to resolve: Should we use the TIMESTAMP WITH TIMEZONE data type or the TIMESTAMP WITHOUT TIMEZONE data type? Both sides had compelling arguments as well as reference URLs and material to present. Adding all the relevant parts of the discussion as data model notes would have helped a lot. Unfortunately, the tool used had no such feature – unlike Vertabelo, which lets you add notes to your data model.
Sub-Models
The number of tables and entities in a data model can grow rather quickly. If proper normalization techniques have been applied, it’s rare to have a system with less than 30-40 tables. Visually presenting that many tables on a screen is impossible. The ability to carve out a section of the model (i.e. a subject area) or to select multiple objects using the menu and publish those as a sub-model is a must-have feature for database modeling tools. Vertabelo supports creating and exporting subject areas.
Object Search
When you need to find a specific entity or table quickly, the ability to search for patterns (e.g. when following a naming convention with object prefixes) and see only matching objects on your screen is a very useful feature. Thus, Vertabelo provides multiple ways to look for tables and other database objects.
Data Model Validation
Databases usually have a list of reserved and non-reserved keywords; for example, here is the documentation for PostgreSQL keywords. It is considered bad practice to use these words as database object names. A validation option – which scans object names and lets the designer know about potential issues – is a very helpful data model feature. Here is how Vertabelo validates a data model.
Test Data Generation
If a database modeling tool can generate test data to populate the tables (after it generates the DDL script to create the objects), that’s another very useful feature. Databases need to be tested before going into production. Usually, data generation and population are necessary for sizing-related tasks – e.g. if we have 10,000 users and they carry out n transactions, what will be the database storage size? What will be the memory requirements for the server?
Regular Updates
Database vendors release new versions frequently, and each release usually adds a few new features (e.g. PostgreSQL added default partitions in version 11). Thus, any database modeling tool should also get updated frequently and add support for the new database features.
Support for Custom Data Types
Some databases allow developers to create custom data types. Thus, database modeling tools should let users create custom data types (i.e. when dealing with a database that allows custom data types). If the users could also publish their custom types to a repository for others to use, even better.
Documentation
A good tool is effective only if its developers provide good documentation. Regularly updated documentation, maybe a few getting-started video tutorials, and similar help matter a lot.
Learn More About Data Modeling
Now that you know what a data modeling tool is and what it does, are you interested in learning more about the data modeling process? Check out the data modeling posts on our blog. If you’d like hands-on experience in getting to know the components of a database, try the Creating Database Structure track on our sister site, LearnSQL.com.
