

Applied for your dream job as a data modeler? You now need to get ready for the interview. We have a list of the most common data modeling questions, grouped into theoretical questions, basic technical questions, and advanced technical questions. Go to the interview well-prepared.
The need for organizations to collect and interpret large volumes of information is constantly growing. Meeting this need requires well-designed data models for agile and efficient databases. They need good data modelers.
The demand for data modeling professionals is on the rise among visionary companies looking to gain competitiveness and willing to pay good salaries. Want to know how good? Check out our article about database designer salaries!
All of this makes data modeling an attractive career option with future-proof, high-paying jobs. If you plan to pursue this career path, you need a significant background in database and data modeling, which you may obtain through courses, degrees, books, and other sources. Then, you need to demonstrate that knowledge at your job interview.
Below, I have prepared a list of the most common database modeling interview questions, along with their correct answers. These questions give you an idea of how to prepare for an interview.
But let me warn you first: while thoroughly studying this list of questions and answers helps you show confidence and assurance during an interview, that is not all the preparation you need to get through it successfully. In addition to knowing the questions and answers, you need the knowledge to back up each interview topic. Read our detailed guide to database schema design and our article on the database diagram to strengthen your basic database knowledge.
As a bonus, I recommend reading about common ER diagram mistakes and common database design errors. Interviewers want to test your abilities as a data modeler, and you do not want to make any of these common mistakes.
Companies do not choose their data modeling professionals lightly. You will not convince them that you are one just because you’ve memorized the list below. With that said, let’s get you ready for the interview.
The database modeling interview questions on this list are grouped into three sets:
- Theoretical and conceptual questions.
- Basic practical/technical questions.
- Advanced practical/technical questions.
Depending on the seniority level of the position for which you are applying, you need to pay attention to some questions more than others. For a junior modeler position, know the questions in the second group perfectly and a little bit from the first group. For a senior modeler job, know the questions in groups 2 and 3 perfectly and a little bit from the first group. For a position that requires decision making, such as a team leader in a database team, you need to know the database schema design interview questions in all three groups perfectly.
Theoretical and Conceptual Questions
The database modeling interview questions in this group are aimed at assessing the general knowledge an applicant has about data modeling. These are important for a position that requires decision making, such as a team leader.
The general knowledge questions may not be the most important in interviews for a junior or senior data modeler position. That said, every aspiring data modeler should know the answers to these questions, even if only at a basic level.
What is the role of the data modeler in a software development team?
The data modeler designs, implements, and documents data architecture and data modeling solutions, which may include the use of relational, dimensional, and NoSQL databases. These solutions support business-critical applications such as enterprise information management, business intelligence, machine learning, and data science, among others.
What are the deliverables a data modeler produces in a development team, and who takes those deliverables as input to their work?
The deliverables produced by a data modeler working in a development team vary from project to project. But the most common ones are:
- Data models: Diagrams or representations of the structure, relationships, and attributes of the data to be used in the project.
- Database schema: A detailed definition of the structure and organization of a database.
- Data dictionary: Documentation that describes the elements that make up a data model or schema, the function they serve, and how to use them.
Other members of the development team, such as developers, database administrators, and testers, often use the results of the data modeling work. For example, developers use the data models and schema to build the database and write the code that interacts with it. Database administrators use the data dictionary to manage the database and ensure the quality of the information.
What is the difference between a conceptual model, a logical model, and a physical model? What is the utility of each?
Conceptual, logical, and physical models are different levels of abstraction in the design of a data model. They represent different aspects of the model and serve different purposes:
- The conceptual model is used to capture the essential characteristics and relationships of the data model at a high level. Avoiding all implementation details, it has the highest degree of abstraction, providing a common language and understanding among the stakeholders of a project.
- The logical model is the detailed representation of the data model, except for the implementation details in a specific database system. It includes the entities, relationships, and attributes of the model as a whole, as well as the rules that govern its behavior.
- The physical model is the translation of the logical model into a representation that allows its direct implementation in a database system. It takes into account the physical limitations of the hardware (server, storage) and software (operating system, database engine) to be used.
For more information on these types of models, read our article on conceptual, logical, and physical data models.
In what situations is it appropriate to use each type of data model: relational, dimensional, and entity-relational? Provide examples.
The relational model is suitable for representing data in the form of tables when the relationships between those tables are clear and defined in advance. It is mainly used to implement databases that support transactional systems. An example is an e-commerce site, whose data model consists of tables such as Customers, Products, and Orders. Another example is an online banking system, with tables such as Store, Account, and Transaction.
The dimensional model is used for business intelligence applications that operate on large data repositories. It supports complex queries and reports whose main purpose is to analyze data based on a multiplicity of dimensions. Examples include a data model for analyzing sales information dimensioned by product, geographic region, time period, etc., and a hospital information data model that allows tracking patients’ health, taking as dimensions age, gender, diagnosis, type of treatment, etc.
The entity-relationship (ER) model is commonly used to represent complex real-world situations that do not fit into a pre-established data model. The ER model facilitates the abstraction of real-world entities and their relationships to solve business problems for which no data models exist. An example is a model for the data in a tracking system for vehicles transporting goods, or a model for production control in a textile manufacturing plant.
What value does a data modeler bring to a software development team?
A data modeler is responsible for designing and maintaining efficient and effective data models. They are responsible for the scalability and maintainability of data models, and for ensuring data integrity in development projects.
In addition, a data modeler helps to reduce data errors and improve data quality. It can identify inconsistencies, redundancies, and incoherencies in data. It also facilitates collaboration among team members, acting as a bridge between developers, designers, analysts, and testers.
Overall, a data modeler brings critical skills and knowledge to a software development team, leading to more efficient development processes, improved data quality, and better collaboration among team members.
Basic Technical Questions
Any aspiring data modeler should be able to answer the database schema design interview questions in this group without a lot of mental effort.
What is an ER diagram, and how is it used in data modeling?
An ER (entity-relationship) diagram is a graphical representation of the entities that make up a database and the relationships that exist between them.
ER diagrams use symbols, lines, and names to represent entities, relationships, and attributes. Entities are objects belonging to a database domain; relationships define the interactions between entities. Attributes are properties or characteristics that define each entity.
A data modeler uses the ER diagram as a tool for system developers to understand the structure of a database. They also use it to identify potential problems in a database design, such as redundancies or inconsistencies, and help developers optimize database performance.
What is the difference between a primary key and a foreign key?
Primary keys are used to identify unique records in a table, while foreign keys are used to establish a relationship between two tables.
A primary key is a column or a set of columns in a table that uniquely identifies each row of that table. It ensures that each row in the table has a unique identifier and that the data in that row is distinct from other rows in that same table. A primary key is typically used to ensure data integrity.
A foreign key is a column or set of columns in a table that references the primary key of another table. It establishes a relationship between two tables by ensuring that data in one table matches data in the other table. The values of the foreign key columns of one table must correspond to the values of the primary key columns of the other. This ensures that the data is consistent across the two tables.
What is cardinality in a database?
Cardinality refers to the count of unique values in a column or a set of columns of a table. It is a measure of the distinctiveness of a data set. For example, if a customer table has a column for nationality, the cardinality of that column is the count of distinct nationalities in the table.
The cardinality of the columns that form the primary key of a table is always equal to the count of rows in the table. This is also relevant to the primary key question above.
The word “cardinality” also applies to relationships between entities or between tables. See below for a specific question about cardinality in relationships.
For more information, read our article about the theory and practice of database cardinality.
What is normalization in relational databases?
Normalization is a process that reorganizes a database schema to reduce redundancy and improve data integrity. As a result of normalization, tables with repeated or redundant data are split into sets of related tables to store information without redundancy and with greater efficiency. The benefits include improved database performance and reduced storage space requirements.
What is the difference between the 1st, 2nd, and 3rd normal forms?
In a schema in the first normal form (1NF), all attributes of all tables must have atomic (indivisible) values.
To be in the second normal form (2NF), a schema must already be in 1NF, and each non-key attribute must depend on the entirety of the primary key. If the primary key is made up of several attributes, the non-key attributes must depend on the entirety of those that make up the primary key. In other words, the non-key attributes may not depend only on a subset of the primary key attributes; partial dependencies are not allowed.
To be in the third normal form (3NF), a schema must already be in 2NF, and each non-key attribute must depend on the primary key in a non-transitive way. That is, there may not be any dependencies between non-key attributes.
For more information, read our article about normalization and the first 3 normal forms.
What is a surrogate key?
It is a unique identifier added to the attributes of a table without having any intrinsic meaning or relationship to the other attributes of the same table.
Surrogate keys serve to replace natural keys that may not be suitable for use as primary keys, either because they are too large or complex or because they may change over time. Another use of surrogate keys is to protect sensitive data. If the data that makes up a natural key includes sensitive or personally identifiable information, the addition of a surrogate key prevents that information from being used as an identifier in the system, reducing privacy risks.
What is the cardinality of a relationship?
In data modeling, the cardinality of a relationship refers to the number of instances of an entity that may be associated with another entity through a particular relationship. It defines the nature of the relationship between two entities and how many instances of each entity may be associated with each other. Cardinality is usually expressed as a ratio or a range of values with the minimum and the maximum number of instances of each entity that may be associated with each other.
How are relationship types classified based on cardinality?
Relationships between entities or between tables may be one of the following three types based on their cardinality:
- One-to-one (1:1): Each instance of the entity at one end of the relationship may be associated with a single instance of the entity at the other end.
- One-to-many (1:N): Each instance of the entity at one end of the relationship may be associated with multiple instances of the entity at the other end. But each instance of the second entity may be associated with only one instance of the first.
- Many-to-many (N:M): Multiple instances of one of the entities may be associated with multiple instances of the other.
What is an inheritance or specialization hierarchy?
When there are different entities with attributes in common in a data model, an inheritance or specialization hierarchy may be created. It serves to simplify the model, make it more efficient, and reinforce the integrity and consistency of the information.
A “parent” entity or supertype is created with the attributes in common to the set of entities. The common attributes are removed from the entities that form the set. These entities become subtypes of the parent entity and are left with only the attributes that differentiate them (more about supertypes and subtypes in the next question).
What are supertypes and subtypes used for in data modeling?
Subtypes and supertypes are two special kinds of entities. They are used to model inheritance or specialization relationships between entities. A supertype is a generalization of one or more subtypes, while a subtype is a specialized entity that inherits properties and attributes from its supertype. The use of subtypes and supertypes in data modeling allows for eliminating redundancies and simplifying the design.
An example of a supertype is a Vehicle entity that contains attributes common to all kinds of vehicles, such as Make, Model, and Year. Subtypes of Vehicle may be Car, Truck, or Motorcycle. Each has attributes specific to the subtype.
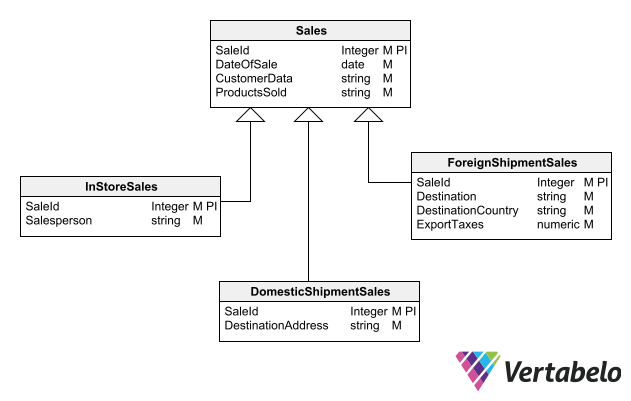
In this inheritance relationship, the Sales supertype has 3 subtypes: InStoreSales, DomesticShipmentSales, and ForeignShipmentSales.
Advanced Technical Questions
Finally, we come to the group of database design questions that usually appear in interviews for senior-level data modeling jobs. They deal with advanced topics such as modeling for data warehousing and design techniques for optimizing queries.
What are OLTP and OLAP, and how do they affect data modeling?
OLTP (online transaction processing) and OLAP (online analytical processing) are two different types of systems that use information stored in databases.
OLTP systems are designed to handle day-to-day business transactions in real time. These transactions usually consist of quick database queries or updates. Examples of OLTP systems include e-commerce platforms, banking systems, and airline ticket reservation systems.
OLAP systems, on the other hand, are designed for analytical processing and reporting of large volumes of data. Examples of OLAP include business intelligence tools, data mining software, and financial analysis systems.
A database schema designed for OLTP must ensure the integrity and consistency of the information. Another important design goal is to achieve efficiency in data entry, modification, and deletion. OLAP databases, in contrast, are designed to support large data volumes and complex queries that summarize data in multiple dimensions. The goal of an OLAP system is to provide fast and flexible access to summarized information for analysis and decision-making.
What is the difference between transactional and dimensional schemas?
Transactional database schemas are designed to support OLTP systems, while dimensional schemas are designed for OLAP systems (see the previous question for more information on OLTP and OLAP).
Transactional schemas emphasize data integrity and consistency. They are designed with normalization to avoid redundancies and anomalies in data entry, modification, and deletion operations. The tables of a transactional schema represent real-world entities, and the relationships between tables represent the existing links between entities.
Dimensional schemas, on the other hand, emphasize the rapid retrieval of summarized data for analysis tasks. Denormalization techniques are used in their design for this purpose (more on denormalization in the next question). In dimensional schemas, there are usually one or more fact tables containing numeric measures. These tables occupy the central part of the schema and are related to multiple dimension tables surrounding them, forming topologies such as star or snowflake (see below).
What does it mean to denormalize a schema?
To denormalize a schema is to intentionally add redundant columns to some of the tables to simplify data retrieval and improve query performance.
In a normalized schema (see the question on normalization, above), redundancies are avoided at all costs to avoid inconsistencies in transactional systems. But in dimensional schemas, normalization may make queries complex and slow, particularly when there are many tables and relationships.
Redundant columns from denormalizing the schema avoid the need for joining many tables, thus simplifying queries and making them more efficient for massive querying. For example, instead of joining a customer table with an order table to retrieve customer information along with order details, a denormalized schema may have customer information duplicated in the order table.
What is the difference between the star schema and the snowflake schema?
Star and snowflake are dimensional database schema topologies. The main difference between the two is the way dimension tables are organized around the central fact table of the schema.
In star schemas, the fact table is placed at the center of the schema. All dimension tables relate to this single fact table, giving the schema a star-like visual appearance.
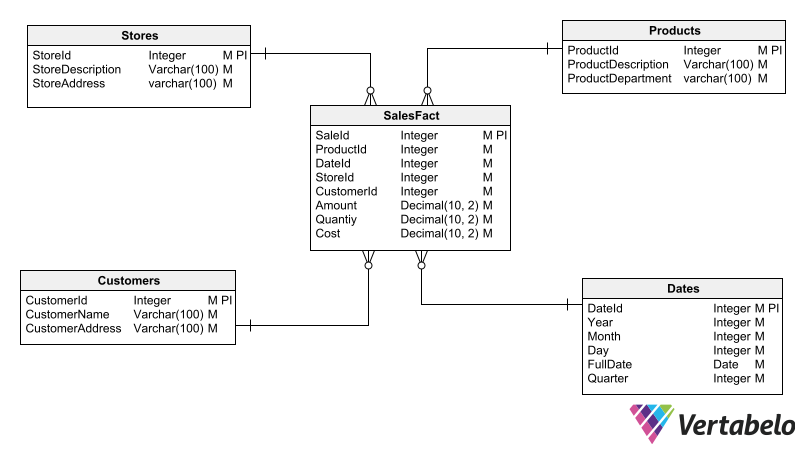
A typical star schema with a fact table in the center and dimension tables around it.
Snowflake diagrams are more complex than star diagrams in that they use several levels of dimension tables. There is a first level of dimension tables that relate directly to the fact table in the center of the schema. Then, there are sub-levels of dimension tables that, instead of relating to the fact table, relate to other dimension tables. The relationships between the dimension tables give the schema a visual appearance like that of a snowflake.
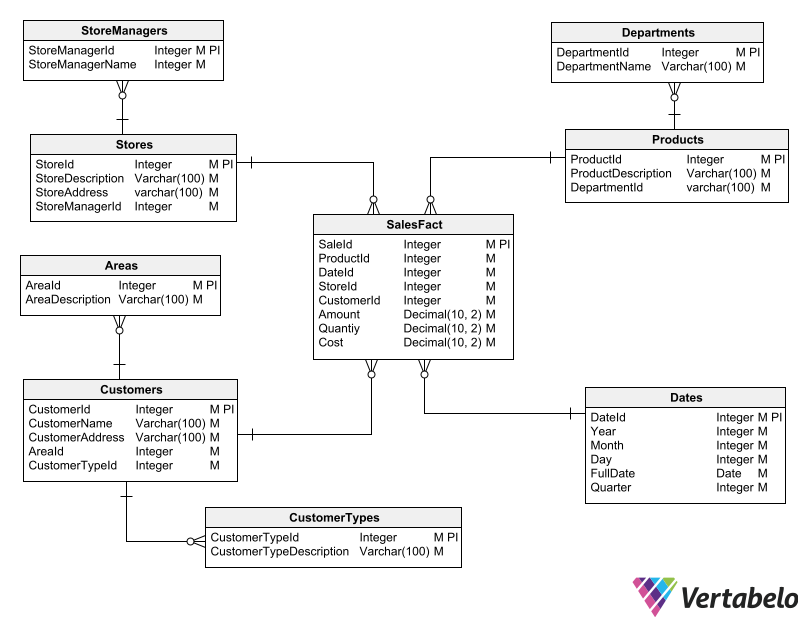
In a snowflake dimensional schema, some dimension tables are related to other dimension tables rather than to the fact table.
For more information, read our article about star schema versus snowflake schema in data warehouse modeling.
Name and describe the main types of dimensions in a data warehouse.
The dimensional schema has different types of dimension tables. The three most common types are:
- Conformed dimensions: They are used in multiple fact tables to maintain their meaning and values for all fact tables consistently. They are important for maintaining consistency and accuracy in a data warehouse.
- Junk dimensions: Used to group low cardinality attributes, such as flags and indicators, that may otherwise clutter the fact table. They are useful for simplifying queries and reducing storage requirements.
- Degenerate dimensions: They are derived from a fact table and do not have a dimension table of their own. They usually consist of unique identifiers or keys that are not useful as independent dimensions.
Other types of dimensions occasionally appear in dimensional schemas:
- Role dimensions: They take on different roles, even within a single fact table. A typical case is the time dimension, which may play the roles of an order date, a purchase date, a delivery date, etc.
- Slowly changing dimensions: These are dimensions that may change over time. An example is a customer dimension, whose address or other personal data may vary over time.
- Hierarchical dimensions: They group several hierarchically related dimensions. An example is a temporal dimension grouping the dimensions such as the year, the quarter, the month, or the day.
What is the difference between a data warehouse and a data mart?
The data warehouse is a global data repository for an entire enterprise. A data mart is a subset of a data warehouse, designed to serve the needs of one area of an enterprise such as a particular business unit.
A data mart focuses on a specific business area, such as sales, marketing, or finance. In contrast, a data warehouse supports the entire organization. The usefulness of data marts lies in providing a more focused view of the data needed by specific users, sparing them the task of browsing through the entire data warehouse that serves the whole enterprise.
Final Remarks on Database Modeling Interview Questions
I hope the database design interview questions in this article help prepare you for your interview. In addition, you can use a data modeling skills test. I wish you the best in landing a good job as a data modeler.
As a final comment, let me add that your skills assessment is not over once you get your job and start working. Instead, your evaluation goes on, only it is no longer based on questions for you to answer. You need to show results and good performance day by day.
