

When faced with the task of creating a warehouse data model, you must understand that the ultimate goal is to create a strategic business tool – not just a simple database. Keep this in mind and read on to find out how to build a successful model for a data warehouse.
A data model for a data warehouse (DW) is a conceptual representation of the structure and relationships between the data elements that make up the DW. The model is used as a starting point for the creation of a data repository for business facts; it’s also a way to inform stakeholders how data will be organized, stored, and accessed.
The notation and elements of the entity-relationship diagram (ER diagram or ERD) are commonly used to model data warehouses, although ERDs are mostly used to design transactional databases.
Transactional vs. Dimensional Data Models
The main difference between a transactional and a warehouse data model is in the purpose of one and the other. Transactional models are designed to optimize the management of transactions in business applications. Their primary objective is to maintain the consistency and integrity of the information stored in the database. Another key objective is to guarantee efficiency and agility in the processing of operations originating in transactional applications, such as e-commerce or online banking.
Dimensional models, on the other hand, are designed to facilitate the analysis of large volumes of data for informed decision-making. Their primary objective is to provide summarized information to business intelligence and data science systems – and to do it at maximum speed.
Very often, dimensional databases are fed with historical and synthesized information from transactional databases. It is also common for these databases to combine information from different sources to establish correlations between facts that, at first glance, may seem unrelated. If you are new to the world of warehouse database design, I suggest you start your journey by reading these two articles: What Is Data Warehousing and What Is a Data Warehouse.
Designing a Data Model for a Warehouse
In transactional databases, the design is usually governed by normalization techniques. These techniques ensure that the database structure itself avoids data inconsistencies as a result of insertion, modification, or deletion. In warehouse data modeling, this is not as necessary.
The information that resides in a repository for data warehousing is not entered through individual transactions. It uses massive data ingestion processes that do not allow (at least in theory) inconsistencies to enter the warehouse. This is why the techniques for designing a data warehousing model vary from those used for a transactional database.
Creating a Data Model for a Data Warehouse
When faced with the task of creating a data model for a warehouse, you may be tempted to use your favorite SQL client and start creating tables right away. This may work for a very small data warehouse. But data warehouses are not exactly known for being small.
For this reason, using the “quick & dirty” methodology to create a data warehouse is decidedly a bad idea. This is mainly because, once the data warehouse is full of data, modifying its structure is quite a difficult task.
We must keep in mind that a data warehouse – even more than a database – is a strategic and critical tool for business. For this reason, we must minimize all possible risks during its construction. To do so, I recommend you follow the steps below. As a result you will have a data warehouse built to last.
Step 1: Understand Business Objectives and Processes
The first phase of creating a data model for a data warehouse involves requirements engineering work, in which you gain an overall understanding of the information and results you expect from using the data warehouse. As a result of this first phase, you should get a detailed description of data warehouse requirements; this serves as input for the next phase.
Step 2: Create a Conceptual Model
Using the detailed requirements obtained in the initial phase, start building a conceptual model that provides an overview of the two main types of tables in any data warehouse: fact tables and dimension tables. You can learn a lot about them by reading our article on facts and dimensions in a data warehouse.
The fact tables are central to the diagram. They contain two fundamental types of attributes: numerical measures and dimension identifiers. Numerical measures are aggregate values (totals, averages, etc.) for each combination of dimension identifiers.
Dimension identifiers are usually foreign keys to the dimension tables surrounding the fact tables. There are many different types of dimension tables, which types you use depends on how the tables are maintained and the kind of information they store. You can learn more about this by reading our article on the most common types of dimension tables.
For simplicity, you can think of dimension tables as lookup tables for identifiers that appear in fact tables, such as product SKUs, customer codes, vendor codes, etc.

The basic structure of a fact table consists of a set of dimensions and a set of measures containing aggregate values.
Step 3: Define the Shape of the Data Model
The conceptual model should show the shape that the data model will have. This shape will be determined by the distribution of the fact and dimension tables.
Three fundamental types of structures are recognized, named for the similarity of their shapes: star, snowflake, and constellation.
In a star data warehouse schema, a single fact table is placed in the center of the diagram. All dimension tables are related to the fact table by a foreign key in the fact table. In the diagram, the dimension tables surround the fact table, giving it a star-like shape. Find more information in this article on the star schema.
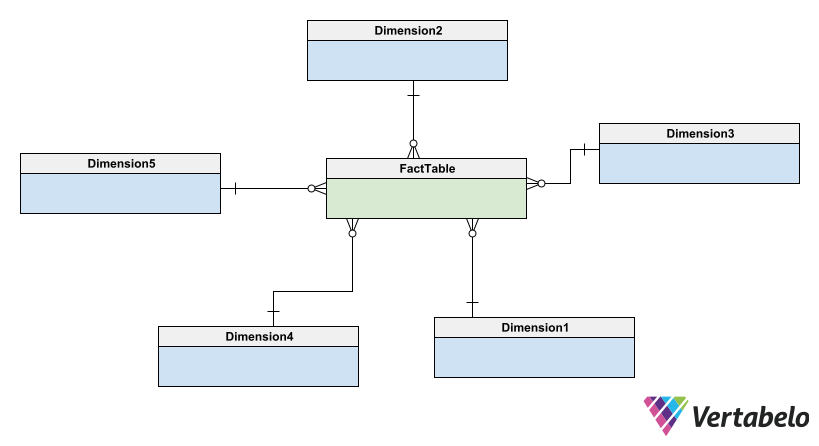
Basic form of a star schema with one fact table (green) and five dimension tables (blue).
In a snowflake schema, the fact table is surrounded by small clusters formed by hierarchies of tables. Each of these hierarchies is a normalized sub-schema that is associated with a dimension of the fact table. For more information you can read this article on snowflake schemas or this one on the differences between star and snowflake schemas.
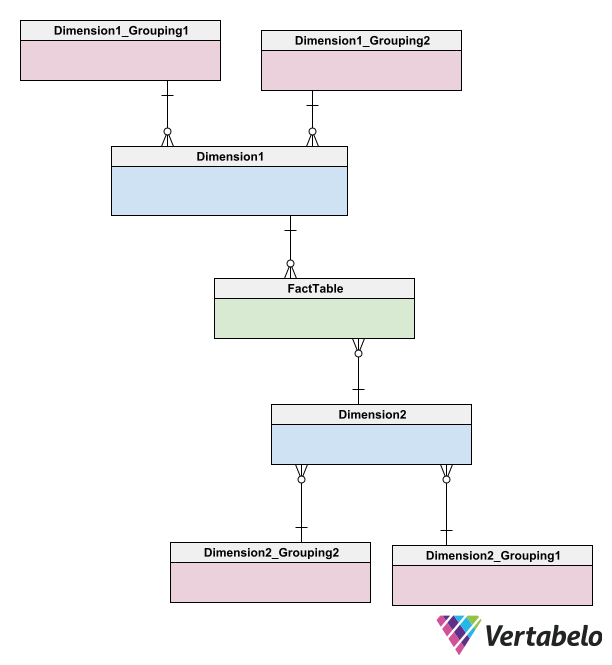
Basic form of a snowflake schema with one fact table (green) and two dimension tables (blue), each one related to two grouping tables (red).
In constellation schemas – also called galaxy schemas – several fact tables appear. Each of them responds to a different business information need and has a set of dimensions surrounding it. Some dimension tables may be shared between the different fact tables.
In the model we will build below, you will see an example of a constellation schema. It will have two fact tables: one for sales and one for procurement (i.e. purchases made by the company).
Step 4: Design the Conceptual Data Model
For the construction of the conceptual model, we do not need to define the diagram down to the smallest detail. It is enough to show the fact tables, the dimension tables, and the relationships between them. This diagram will help us explain the model to users and stakeholders. The goal is to obtain feedback and approval so that when the database is running there is no possibility of misunderstandings and complaints.
To illustrate the process, we will use the Vertabelo platform to create a conceptual model. The advantage of using Vertabelo is that it allows us to work in a top-down manner – i.e. starting with a conceptual model, then making a copy of it to create a logical model, and using the subsequent logical model to derive the physical model. Finally, Vertabelo allows us to generate the DDL scripts that will enable the creation of the data warehouse in any DBMS (Database Management System) or warehouse tool.
As mentioned above, our data model will have a galaxy or constellation shape:
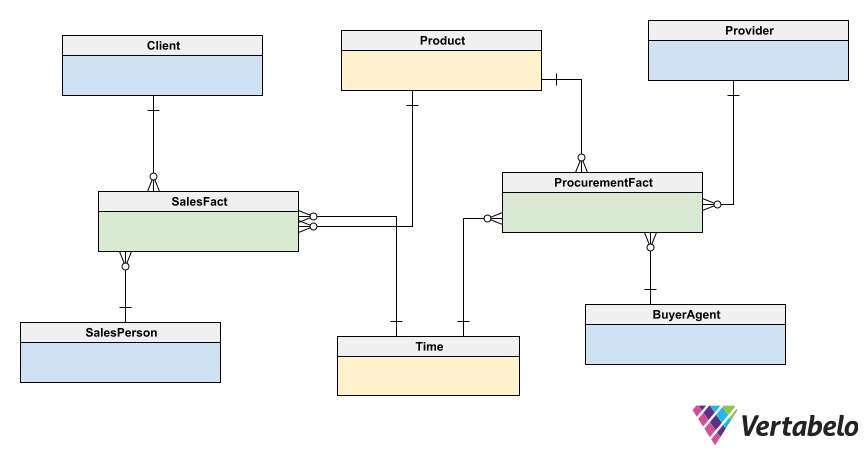
Vertabelo allows us to use different colors in our model to identify different types of tables. In this constellation schema, fact tables are green, shared dimension tables are yellow, and the rest of the dimension tables are blue.
Step 5: Create the Logical Data Model
The conceptual model allows everyone involved in the process to verify that the model meets the requirements and to give their approval for further development. Vertabelo allows you to share your model with different users and give each one the privileges they need (i.e. either to view the design or to make modifications to it). You can see the options for sharing your models here.
Using Vertabelo, we can create the logical model from the conceptual one. There are two ways to do this. We can create a replica of the conceptual model and extend that replica to build the logical model, or we can tag the version of the conceptual model and then continue working on it. By creating a tag, we can revert to the tagged version at any moment (e.g. if we need to revise the conceptual model). You will find more information about version control in Vertabelo here.
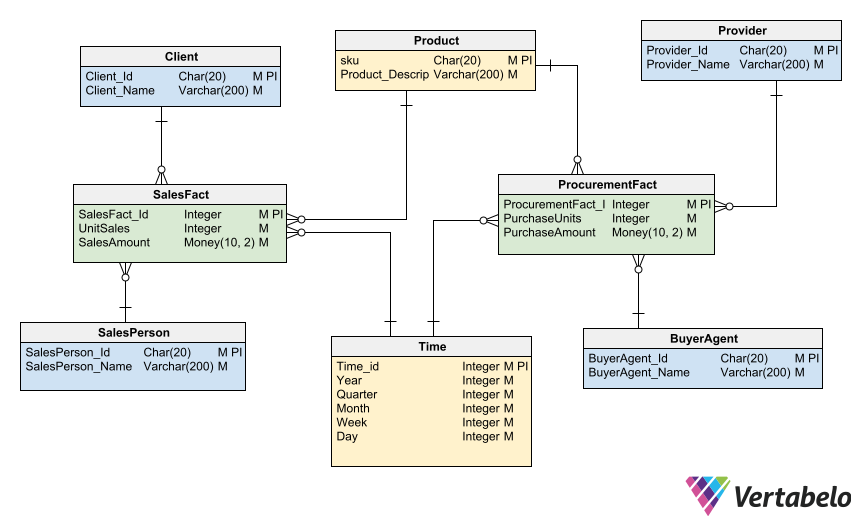
To complete the logical model for our data warehouse, we need an entity for each fact table and for each dimension table. Then we need to establish the corresponding relationships between them. In the logical model, we must include all the entities and all the attributes. Don’t overlook any of them!
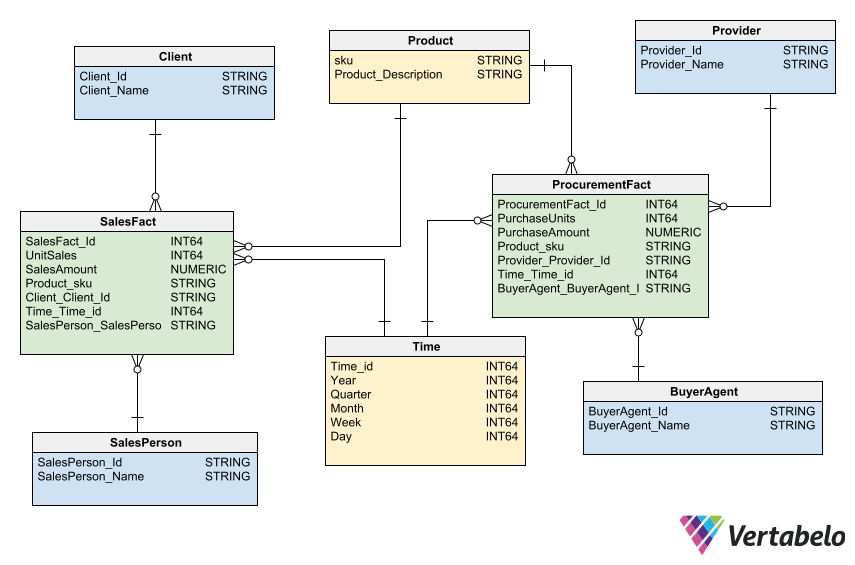
The logical model includes all the entities and all the attributes that make up our data warehouse.
Our data model for a warehouse includes two fact tables: one for Sales and one for Procurement. Both share the dimensions Time and Product, since the same data is used to characterize both sales and procurement facts.
Then, both fact tables are related to dimensions that are specific to each business process:
- The
Salesfact table relates to theSalesPersonandClientdimension tables. - The
Procurementfact table relates to theBuyerAgentandProviderdimension tables.
At this point, it is important to submit the data model to a validation process that will give us the greatest possible assurance that the database can be implemented without errors. This validation process will also minimize risks to information integrity. For this purpose, we can use the live model validation feature offered by Vertabelo. This functionality will allow us to automatically detect problems, such as:
- Entity name repetition.
- Attribute name repetition within the same entity.
- Entities without attributes.
- Entities without primary identifiers.
- Attributes with different data types involved in a relation.
- And many other possible errors that could cause future problems.
Live validation should also be applied to the physical model, since this model could be affected by errors of its own.
Step 6: Create the Physical Data Model
Having the logical model verified by Vertabelo’s live validation feature, the only missing step before implementing the model on a database engine is to generate a physical model from the logical one.
This task is performed automatically by Vertabelo. The only human intervention needed is to tell Vertabelo which database engine will be used to implement the database. Read this article about the main data warehouse tools to find out which option to choose when creating your physical data model.
The automatically generated physical model is almost ready to be implemented. In this case, we picked Google BigQuery as the target database engine.
The live validation feature can also be used on the physical model to detect (before it is too late) problems that may affect the integrity of the data or the database itself. An example is columns with data types that are incompatible with the warehouse tool on which the model will be implemented.
Step 7: Implement the Model
The last step required to build our data warehouse is to implement the physical model on the target DBMS. This step consists of generating the scripts that must be executed on the DBMS to create the database.
If you did not skip any step and your models were properly validated, the scripts to implement the database will run smoothly and your data warehouse will be ready to fill with information.
If you need more examples that illustrate the process of creating a data model for a warehouse, you can read Part 1 and Part 2 of our series on how to create a data warehouse for a subscription business model.
More on Database Schemas, Diagrams, and Warehouse Models
I hope this explanation of creating a data model for a data warehouse has helped you. If you'd like to learn more about data warehousing and example data models, check out the Vertabelo blog. You can also follow these links to read about database design, data warehouses, and more.
