

We help you understand the data warehouse and its concepts.
Data and analytics have become indispensable for businesses to remain competitive. Business users rely on reports, dashboards, and analytics to extract insights from data, monitor business performance, and support decision-making.
Data warehouses are used to feed these reports, dashboards, and analysis tools. It does so by efficiently storing data to minimize input and output (I/O) and deliver query results quickly to hundreds and thousands of users simultaneously.
We use the abbreviation DWH for “data warehouse” in this article.
Purpose of a Data Warehouse
A DWH is a central repository of information that can be analyzed to make better decisions. Data flows from transactional systems, relational databases, and other sources into a data warehouse, usually at a regular pace. Business analysts, data engineers, data scientists, and decision-makers access data through business intelligence (BI) tools, SQL clients, and other analytics applications.
Effective data warehouse management is key to maintaining the accuracy, performance, and reliability of the data stored within the system. A DWH is a data management system designed to enable and support BI activities and advanced analytics. It is intended exclusively for performing advanced queries and analysis and often contains large amounts of historical data. Data in a data warehouse is usually derived from various sources, such as application log files and transaction applications (this article provides more details about this subject if you want more information).
In this article, we explain the basic principles of a DWH, its architecture, purpose, and advantages.
The Basic Architecture
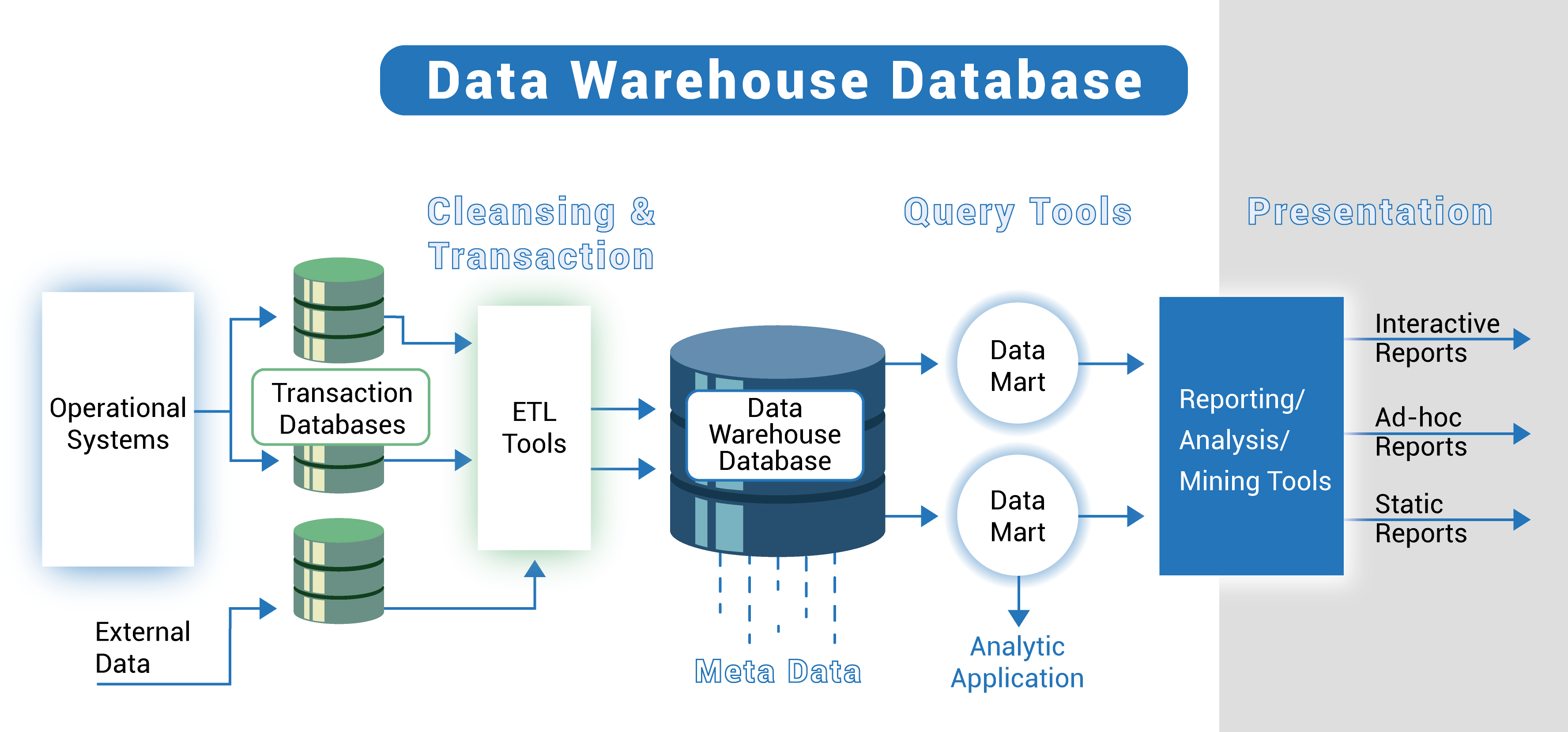
The DWH architecture is made up of layers. The top tier is the front-end client, which presents results through reporting, analytics, and data mining tools. The middle layer consists of analytics engines used to access and analyze data. The lower layer of the architecture is the database server, where data is loaded and stored.
There are two ways to store data:
- Frequently accessed data is stored in high-speed storage (such as SSD drives).
- Infrequently accessed data is stored in an inexpensive object store.
The DWH will automatically ensure frequently accessed data is moved to the "on-the-fly" storage to optimize query speed.
A DWH architecture defines how data is organized in different databases, as data must be organized and clean to be of value. The modern DWH structure focuses on identifying the most effective technique to support this. This includes extracting information from raw data in a staging area and converting it into a simple consumable storage structure using a dimensional model to deliver valuable business intelligence. Also, unlike a cloud data warehouse, a traditional data warehouse requires on-premises servers for all warehouse components to function.
When designing an enterprise DWH, there are three types of models to consider:
- Single-tier data warehouse architecture.
- Two-tier data warehouse architecture.
- Three-tier data storage architecture.
A single-tier DWH architecture framework focuses on producing a dense set of data and reducing the deposited volume. While beneficial for eliminating redundancies, this type of warehouse architecture is not suitable for organizations with complex data requirements and numerous data streams. This is where multi-tier data warehouse architectures come in since they deal with more complex data flows.
In contrast, the structure of a two-tier DWH architecture divides the warehouse's own tangible data sources. Unlike the single-tier architecture, the two-tier architecture has a system and a database server. This is most commonly used in small organizations where a server is used as a data mart. While more efficient at storing and organizing data, the two-tier architecture is not scalable. Also, it can support only a nominal number of users.
The three-tier architecture is the most common, as it produces a well-organized data stream from raw information to valuable insights. The lower layer in this architecture usually includes the database server, which creates an abstraction layer on data from various sources such as transactional databases for front-end uses.
The middle tier includes an online analytical processing (OLAP) server. From the user’s perspective, this layer arranges the data to best suit multi-faceted analysis and probing. Since the architecture includes a pre-built OLAP server, we can also call it an OLAP-focused DWH.
The third and highest tier is the client tier, which includes the tools and the application programming interface (API) used for high-level data analysis, queries, and reporting. Tier 4 is rarely included in the data warehouse architecture since it is often not considered as integral as the other three types of DWH architecture.
Architecture Components of the Data Warehouse
A data warehouse design consists of six main components:
- Data Warehouse Database
- Extract, Transform, and Load (ETL) Tools
- Metadata
- Data Warehouse Access Tools
- Data Warehouse Bus
- Data Warehouse Reporting Layer
The central component of a data warehousing architecture is the database that stores all the data and makes it manageable for reporting. This means you need to choose the type of database you will use to store data in your warehouse.
You can use the following four types of database:
- Typical relational databases are row-centric databases you might use daily. Examples include Microsoft SQL Server, PostgreSQL, Oracle, and IBM DB2.
- Analytics databases are designed for data storage to support and manage analytics. Examples include Teradata and Greenplum.
- DWH appliances are not exactly a type of warehousing database, but several providers now offer appliances that combine data management software and data warehousing hardware. Examples include SAP Hana, Oracle Exadata, and IBM Netezza.
- Cloud-based databases are hosted in the cloud, so you don't need to purchase any hardware to set up your DWH. Examples include Amazon Redshift, Google BigQuery, and Microsoft Azure SQL.
ETL tools are core components of an enterprise DWH architecture. These tools help extract data from different sources, transform it into a suitable array, and load it into a data warehouse.
The ETL tool you choose will determine:
- Time spent extracting data.
- Approaches to extracting data.
- Type of transformations applied and the complexity of its execution.
- Business rules for validating and cleansing the data to improve analysis.
- How missing data should be handled.
- Distribution of information that is critical to your BI applications.
Before we delve into the third component, the metadata, we need to understand its different types in data mining. In data warehouse architecture, metadata describes the data warehouse and provides a framework for the data. It helps in the construction, preservation, handling, and use of the data warehouse.
There are two types of metadata in data mining:
- Technical metadata, which includes information used by developers and managers when performing warehouse development and administration tasks.
- Business metadata, which provides an easily understandable view of the data stored in the warehouse.
Metadata plays an important role for organizations and technical teams to understand the data in the warehouse and convert it into information.
Finally, the DWH bus and the reporting layer: the first defines the data flow in a data warehouse bus architecture and includes a data mart. A data mart is an access level used to transfer data to users and partition data produced for a certain group of users.
The reporting layer in the DWH allows the end users to access the BI interface or the BI database architecture. The purpose of the reporting layer is to act as a dashboard for viewing data, creating reports, and pulling all necessary information.
The History of the Data Warehouse
When data warehouses first entered the scene in the late 1980s, the goal was to help data flow from operating systems into decision support systems (DSSs). These early data warehouses required an enormous amount of redundancy. Most organizations had multiple DSS environments that served their numerous users. Although DSS environments used much of the same data, data collection, cleansing, and integration were often replicated in each domain.
As the DWH became more efficient, they evolved from information stores that supported traditional BI platforms to broad analytics infrastructures supporting a wide range of applications such as advanced operational analytics and performance management.
DWH iterations have progressed over time to provide additional incremental value to the organization, getting the following resources over time:
| Transactional Report | Provides relational information to create business performance snapshots. |
| Division and organization, ad hoc consultation, BI tools | Expands the capabilities for more detailed information and more robust analytics. |
| Forecasting future performance (data mining) | Develops visions and future-oriented business intelligence. |
| Tactical analysis (spatial, statistical) | Develops visions and future-oriented business intelligence. |
| Storage | Stores many months or years of data. |
Supporting each of these five items requires an increasing variety of datasets. The last three items in particular have created the imperative for an even wider range of advanced data and analytics capabilities.
Today, AI and machine learning are transforming nearly every industry, service, and business asset, and DWH is no exception. The expansion of Big Data and new digital technologies are driving changes in data warehouse requirements and capabilities.
The standalone DWH is the latest step in this evolution, giving organizations the ability to derive even more value from their data while reducing costs and improving data warehouse reliability and performance.
Understanding OLTP and OLAP
OLTP stands for "online transaction processing" and refers to transactional systems, that is, the operational systems of organizations. They are used to process routine data generated daily through the organization’s information systems to support the business execution functions.
OLAP, or "online analytical processing," enables analyzing large volumes of information from the most diverse perspectives within a DWH. OLAP references analytical tools used in BI to visualize management information and supports the analysis functions within the enterprise.
| OLAP | OLTP | |
|---|---|---|
| Focus | Aimed at business analysis and decision-making. | Aimed at the operational execution of the business. |
| Performance | Optimized for reading and generating analysis and management reports. | Fast in handling operational data, but inefficient for management analysis. |
| Data Structure | Data is structured in dimensional modeling. Highly summarized data. | The data is structured by a normalized relational model optimized for relational use. High level of detail. |
| Storage | Storage in data warehouse structures, with optimized performance for large volumes of data. | Storage in conventional database systems through the organization's information systems. |
| Target Users | Used by managers and analysts in decision-making. | Used by technicians and analysts, and encompasses various users of the organization. |
| Update Frequency | Information updated in the data loading process. Low update frequency (daily, weekly, monthly, or yearly). | Data update performed at the time of the transaction. Very high update frequency. |
| Volatility | Historical and non-volatile data. The data does not change except for specific needs or errors/inconsistencies. | Volatile data, subject to modification and deletion. |
| Data Permission Types | Insertion and read-only allowed, with read-only users. | Data can be read, inserted, modified, and deleted. |
The big difference lies in the fact that OLTP has an operational focus while OLAP has a management focus. Therefore, they are complementary and support different goals. You can access a detailed article about this topic here.
Modeling Data Warehouses
There are different types of database modeling techniques optimized for different applications. For example, normalized entity-relationship models (ER models) are designed to eliminate data redundancy, quickly perform insert/update/delete operations, and get data into a database.
In contrast, dimensional models – based on the technique introduced by Ralph Kimball – are denormalized structures designed to retrieve data from a data warehouse. They are optimized for performing the select operation and are used in the basic design framework for building highly optimized and functional data warehouses. To enhance your understanding with examples, the article here talks about the star schema, while this one here explains the snowflake schema.
Dimensional modeling is still the most commonly used database modeling technique for designing an enterprise DWH because of its benefits, which include:
- Faster data recovery.
- A better understanding of business processes.
- Flexibility for change.
Dimensional modeling merges tables into the model itself, allowing users to retrieve data faster than other approaches by running join queries. In addition, the denormalized schema of a dimensional model is optimized for running ad hoc queries, which supports the BI goals of the organization.
In a dimensional model, information is stored in fact and dimension tables. This categorization of data into facts and dimensions along with the entity-relationship structure presents complex business processes in a way that is easy for analysts to understand.
Dimensional modeling makes a DWH design extensible. The design can be modified easily to incorporate any new business requirements or to make adjustments. New entities can be added to a model, or the layout of an existing entity can be modified to reflect changes in business processes. This article here compares some database modeling schemas with their differences.
Data Warehouses Create Business Advantages
In this article, we have briefly presented the data warehouse, which creates a significant business advantage for an organization despite its complex structures and concepts.
