

Welcome to a new series that shows you the practical side of the data warehouse (DWH)! In the first article, we’ll tackle a data model for a subscription business.
In previous data warehouse articles (The Star Schema, The Snowflake Schema, Star Schema vs. Snowflake Schema) we focused more on the theory. In this series, we’ll show you how you could create a data warehouse for a real-life application, such as a database model. Today, we’ll take a look at the data model behind a subscription-based business. In upcoming articles, we’ll build a DWH and the code that makes the magic work.
What Is a Data Warehouse?
A data warehouse (DWH) is a relational database, with a significant difference in the way it’s created and used. For a start, a DWH is an OLAP (On-Line Analytical Processing) system. OLTP (On-Line Transaction Processing) databases work with and store real-time operational data; OLAP databases are used mainly for reporting and use stored data. This improves the performance of the OLAP database (and that of the OLTP, too) and keeps reporting data consistent (i.e. it doesn’t change as much as real-time data changes). There are reporting systems that use real-time data, which are called Operational Data Stores, or ODS. We won’t be discussing them in today’s article, though.
So, for a start, we’ll need a way to select the data we need and migrate it to the DWH. To do that, we’ll use the ETL (extract, transform, load) process. We’ll select the data we need from OLTP (the extract part of the process), transform it into the structures appropriate for the DWH, and load the data into the DWH. This action will repeat at regular intervals, such as the close of business (COB), the end of the day (EOD), the end of the month (EOM), or the end of period (EOP).
The result will be two databases: one is operational and used only for operational tasks, and the other is the DWH, which is used for reporting. Of course, the data in DWH will be as old as whatever interval used in the ETL process; we can define the interval according to business needs. If we need daily reporting, we’ll perform the ETL daily.
In this article, we’ll start with the OLTP data model. In the next article, we’ll create the OLAP DWH, and we’ll tackle the procedures needed to perform the ETL process in the article after that.
I hope you’ll find this series very useful. Let’s get started!
The Data Model
Our model is meant to cover a simple subscription-based business and all its related specifics. We’ll need to store products, customers, and subscription details, and we’ll also need to track deliveries.
Our model is composed of four subject areas:
LocationsProducts & documentsCustomers & servicesDeliveries
We’ll present each of these subject areas individually, in the order they are listed.
Section 1: Locations

The Locations subject area is not specific to this model, but we’ll definitely need it later when referencing locations related to customers and deliveries.
We’ll store cities and countries in our model. For each country, we’ll store only the UNIQUE country_name, while for each city, we’ll store the UNIQUE combination of city_name, postal_code, and country_id.
Section 2: Products and Documents

Our customers are interested in the products we have on offer. Depending on our business model, these could be newspapers, cosmetics, groceries, gift boxes, or any combination of these.
A list of all products we have or ever have had is maintained in the product table. For each product we’ll store:
product_name– The UNIQUE name for that product.current_price– The current price for that product.description– An unstructured textual product description.active– A flag denoting if this product is currently on offer or not.
Besides the simple description of each product, we’ll probably need to store a few related documents. We can expect that most of them would be pictures, but text documents with a more detailed product description are also common. A list of all such documents is stored in the document table. For each record here, we’ll store a unique id, the relevant product_id and a link to that document.
Section 3: Customers and Subscriptions
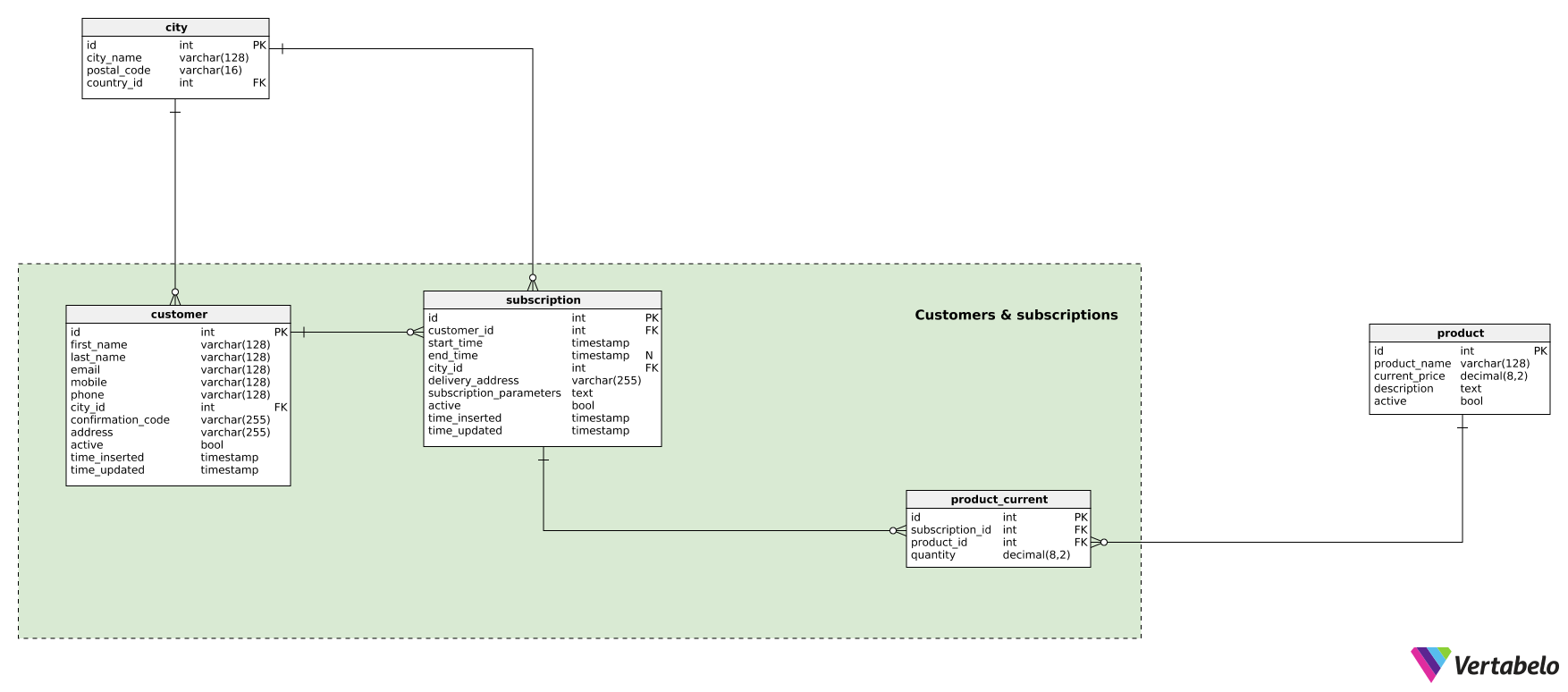
Now we’re ready to move to the heart of our model: customers and subscriptions.
First, we’ll need to keep records for all the customers registered in our application. For each customer, we’ll store:
first_nameandlast_name– The first and last name of that customer.email,mobile, andphone– The customer’s contact details. We can expect that the customer’s email and mobile information will be confirmed during the registration process.confirmation_code– A code we’ll use during the registration process to confirm email or phone information.city_id– References thecitywhere the customer is located.address– The customer’s delivery address, including postal code.active– A flag denoting if this customer is still active in our system. A customer could become inactive by their choice (i.e. they stop using our platform) or if we ban them for any reason.
Any customer could have one or more subscriptions. These could be previous subscriptions that are now inactive, but customers could also have several active subscriptions at one time. Maybe they want to receive deliveries at different intervals or at different addresses. Or maybe we offer more than one subscription service (e.g. daily newspaper, weekly magazines). All subscriptions customers have or ever have had are kept in the subscription table. For each subscription, we’ll store:
customer_id– The ID of the relevantcustomer.start_date– When this subscription became valid. This could be the date when this record was inserted.- end_date – When the subscription was canceled. It will be set when the customer
decidesto end this subscription. city_id– References to thecitywhere the customer wants the subscription to be delivered.delivery_address– The full address where this subscription will be delivered.subscription_parameters– All parameters needed for the subscription. We can expect that parameters will be stored as a list of key-value pairs.active– A flag denoting if this subscription is still active in our system. The subscription will become inactive when the customer cancels it. In that case, we’ll also set theend_datevalue.
The last table in this subject area is the product_current table. This table contains a list of current products that customers can select for their subscription service. We won’t store any history here – only current values. We’ll need to keep the IDs of the related subscription and product, as well as the quantity of each product included in that subscription. There is no need to have more than one line for each product and subscription, so the pair subscription_id – product_id is the alternate key of this table.
Section 4: Deliveries
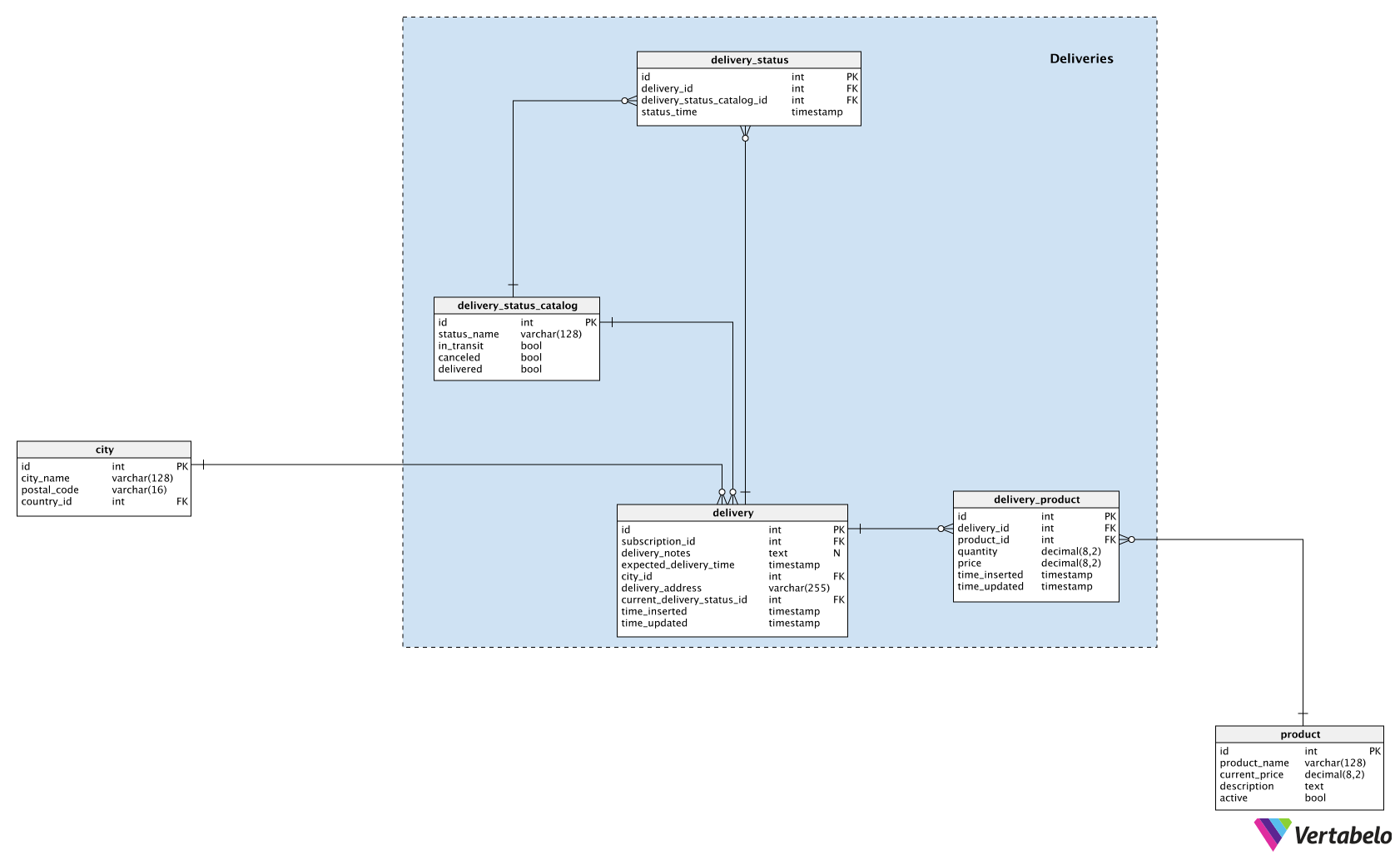
Deliveries are the next step in our business process. After a customer has selected the parameters for their subscription, deliveries can be started. We can expect that the subscription.subscription_parameters field will provide info on when to generate the next delivery for that subscription. We’ll go through all active subscriptions on a regular basis and generate deliveries accordingly.
Information about all newly-generated deliveries is stored in the delivery table. For each delivery, we’ll have:
subscription_id– The ID of the related subscription.delivery_notes– Any notes generated automatically in the system, or notes a customer inserted after the record was created.expected_delivery_time– A TIMESTAMP when we expect products will be delivered to the address provided.city_idanddelivery_address– Contain values copied from thesubscriptiontable at the time this record was created. Please note that either of these details could be changed over time, so we need to store the most current values here.current_delivery_status_id– References a dictionary with a list of all possible delivery statuses. We can expect that the first status will be “delivery created” and others will be assigned according to how the delivery progresses.
Each delivery will contain one or more products. All related delivery and product IDs are stored in the delivery_product table. This table will also store the quantity of each product included in that delivery (the product_current.quantity attribute) and the product’s current price (the product.current_price attribute).
The last two tables in the model are related to delivery statuses.
The delivery_status_catalog table holds a list of UNIQUE status_name values. Each status denotes exactly one of the following: delivery_created, in_transit, canceled, or delivered.
To keep a complete history of statuses assigned to any delivery, we’ll need an additional table. This is the delivery_status table. It contains references to the related delivery and status, as well as the time when this status was assigned.
Taking the Next Steps: The DWH
Now we’ll take a brief look into the future – what we can expect in the upcoming articles.
We’ve just discussed a “normal” relational model, one that we’d expect in the background of a web application. Up next, we’ll see some DWH-related stuff.
Creating a DWH is desirable when we want to separate our reporting and operational database ( e.g. for performance, data quality, etc). This will be even more important if our operational database is growing quickly. In this subscription business data model, we can expect to have a lot of data entries in the customer, subscription, and product_current tables. But we’ll have even more data in tables related to deliveries, especially for delivery statuses.
These tables are good candidates for data aggregation. For example, it would be great to know how many active subscriptions and customers we have on every single day, how many products are included in these active subscriptions, etc. This is the reason we have two attributes, the time_inserted timestamp and the time_updated timestamp, in several tables in our model. We’ll use these values to find any new or updated entries we need to include in our DWH.
If you’re interested in data warehouses, stay tuned! New articles are coming soon. Also, feel free to share your experiences about working with a DWH. What approach would you use? What would be your fact and dimension tables? Tell us in the comments section!
