

Why Talk About Errors?
The art of designing a good database is like swimming. It is relatively easy to start and difficult to master. If you want to learn to design databases, you should for sure have some theoretic background, like knowledge about database normal forms and transaction isolation levels. But you should also practice as much as possible, because the sad truth is that we learn most… by making errors.
In this article we will try to make learning database design a little simpler, by showing some common errors people make when designing their databases.
Note that we will not talk about database normalization – we assume the reader knows database normal forms and has a basic knowledge of relational databases. Whenever possible, covered topics will be illustrated by models generated using Vertabelo and practical examples.
This article covers designing databases in general, but with emphasis on web applications, so some examples may be web application-specific.
Model Setup
Let’s assume we want to design a database for an online bookstore. The system should allow customers to perform the following activity:
- browse and search books by book title, description and author information,
- comment on books and rate them after reading,
- order books,
- view status of order processing.
So the initial database model could look like this:
To test the model, we will generate SQL for the model using Vertabelo and create a new database in PostgreSQL RDBMS.
The database has eight tables and no data in it. We have populated the database with some manually created test data. Now the database contains some exemplary data and we are ready to start the model inspection, including identifying potential problems that are invisible now but can arise in the future, when the system will be used by real customers.

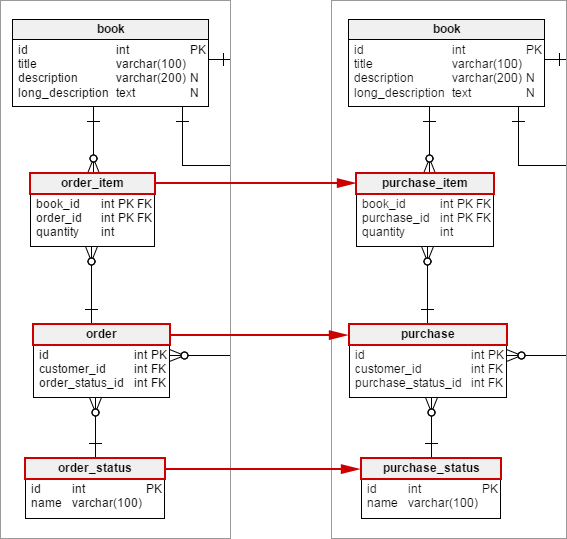
1 – Using Invalid Names
Here you can see that we named a table with a word “order”. However, as you probably remember, “order” is a reserved word in SQL! So if you try to issue a SQL query:
SELECT * FROM ORDER ORDER BY ID
the database management system will complain. Luckily enough, in PostgreSQL it is sufficient to wrap the table name in double quotes, and it will work:
SELECT * FROM "order" ORDER BY ID
Wait, but “order” here is lowercase!
That’s right, and it is worth digging deeper. If you wrap something in double quotes in SQL, it becomes a delimited identifier and most databases will interpret it in a case-sensitive way. As “order” is a reserved word in SQL, Vertabelo generated SQL which wrapped it automatically in double quotes:
CREATE TABLE "order" (
id int NOT NULL,
customer_id int NOT NULL,
order_status_id int NOT NULL,
CONSTRAINT order_pk PRIMARY KEY (id)
);
But as an identifier wrapped in double quotes and written in lower case, the table name remained lower case. Now, if I wanted to complicate things even more, I can create another table, this time named ORDER (in uppercase), and PostgreSQL will not detect a naming conflict:
CREATE TABLE "ORDER" (
id int NOT NULL,
customer_id int NOT NULL,
order_status_id int NOT NULL,
CONSTRAINT order_pk2 PRIMARY KEY (id)
);
The magic behind that is that if an identifier is not wrapped in double quotes, it is called “ordinary identifier” and automatically converted to upper case before use – it is required by SQL 92 standard. But identifiers wrapped in double quotes – so called “delimited identifiers” – are required to stay unchanged.
The bottom line is – don’t use keywords as object names. Ever.
 Did you know that maximum name length in Oracle is 30 chars?
Did you know that maximum name length in Oracle is 30 chars?
The topic of giving good names to tables and other elements of a database – and by good names I mean not only “not conflicting with SQL keywords”, but also possibly self-explanatory and easy to remember – is often heavily underestimated. In a small database, like ours, it is not a very important matter indeed. But when your database reaches 100, 200 or 500 tables, you will know that consistent and intuitive naming is crucial to keep the model maintainable during the lifetime of the project.
Remember that you name not only tables and their columns, but also indexes, constraints and foreign keys. You should establish naming conventions to name these database objects. Remember that there are limits on the length of their names. The database will complain if you give your index a name which is too long.
Hints:
- keep names in your database:
- possibly short,
- intuitive and as correct and descriptive as possible,
- consistent;
- avoid using SQL and database engine-specific keywords as names;
- establish naming conventions (read more about planning and setting up a naming convention for your database)
Here is the model with order table renamed to purchase:
Changes in the model were as follows:
2 – Insufficient Column Width
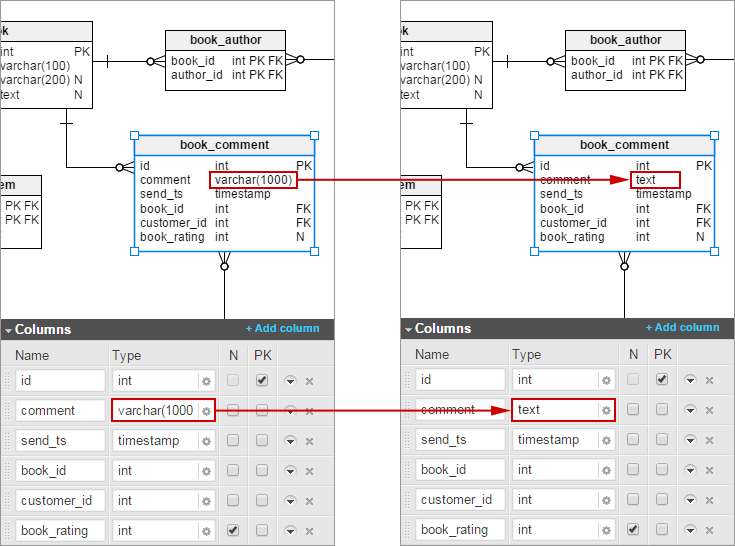
Let’s inspect our model further. As we can see in book_comment table, the comment column’s type is character varying (1000). What does this mean?
If the field will be plain-text in the GUI (customers can enter only unformatted comments) then it simply means that the field can store up to 1000 characters of text. And if it is so – there is no error here.
But if the field allows some formatting, like bbcode or HTML, then the exact amount of characters a customer can enter is in fact unknown. If they enter a simple comment, like this:
I like that book!
then it will take only 17 characters. But if they format it using bold font, like this:
I like that book!
then it will take 24 characters to store while the user will see only 17 in the GUI.
So if the bookstore customer can format the comment using some kind of WYSIWYG editor then limiting the size of the “comment” field can be potentially harmful because when the customer exceeds the maximum comment length (1000 characters in raw HTML) then the number of characters they see in the GUI can still be much below 1000. In such a situation just change the type to text and don’t bother limiting length in the database.
However, when setting text field limits, you should always remember about text encoding.
Type varchar(100) means 100 characters in PostgreSQL but 100 bytes in Oracle!
Instead of explaining it in general, let’s see an example. In Oracle, the varchar column type is limited to 4000 bytes. And it is a hard limit – there is no way you can exceed that. So if you define a column with type varchar(3000 char), then it means that you can store 3000 characters in that column, but only if it does not use more than 4000 bytes on disk. If it exceeds the limit, Oracle will throw an error when attempting to save the data to the database. And why could a 3000-character text exceed 4000 bytes on disk? If it is in English it cannot. But in other languages it may be possible. For example, if you try to save the word “mother” in Chinese – 母親 – and your database encoding is UTF-8, then such a string will have 2 characters but 6 bytes on disk.
Note that different databases can have different limitations for varying character and text fields. Some examples:
BMP (Basic Multilingual Plane, Unicode Plane 0) is a set of characters that can be encoded using 2 bytes per character in UTF-16. Luckily, it covers most characters used in all the world.
- Oracle has the aforementioned limit of 4000 bytes for
varcharcolumn, - Oracle will store CLOBs of size below 4 KB directly in the table, and such data will be accessible as quickly as any
varcharcolumn, while bigger CLOBs will take longer to read as they are stored outside of the table, - PostgreSQL will allow an unlimited
varcharcolumn to store even a gigabyte-long string, silently storing longer strings in background tables to not decrease performance of the whole table.
Hints:
- limiting length of text columns in the database is good in general, for security and performance reasons,
- but sometimes it may be unnecessary or inconvenient to do;
- different databases may treat text limits differently;
- always remember about encoding if using language other than English.
Here is the model with book_comment type changed to text:
The change in the model was as follows:

3 – Not Indexing Properly
There is a saying that “greatness is achieved, not given”. It is the same for performance – it is achieved by careful design of the database model, tuning of database parameters, and by optimizing queries run by the application on the database. Here we will focus on the model design, of course.
In our example let’s assume that the GUI designer of our bookstore decided that 30 newest comments will be shown in the home screen. So to select these comments, we will use the following query:
select comment, send_ts from book_comment order by send_ts desc limit 30;
How fast does this query run? It takes less than 70 milliseconds on my laptop. But if we want our application to scale (work fast under heavy load) we need to check it on bigger data. So let’s insert significantly more records into the book_comment table. To do so, I will use a very long word list, and turn it into SQL using a simple Perl command.
Now I will import this SQL into the PostgreSQL database. And while it is importing, I will check time of execution of the previous query. The results are summarized in the table below:
| Rows in “book_comment” | Time of query execution [s] |
|---|---|
| 10 | 0,067 |
| 160,000 | 0,140 |
| 200,000 | 0,200 |
| 430,000 | 0,286 |
| 500,000 | 0,327 |
| 600,000 | 0,362 |
As you can see, with increasing number of rows in book_comment table it takes proportionally longer to return the newest 30 rows. Why does it take longer? Let’s see the query plan:
db=# explain select comment, send_ts from book_comment order by send_ts desc limit 30;
QUERY PLAN
-------------------------------------------------------------------
Limit (cost=28244.01..28244.09 rows=30 width=17)
-> Sort (cost=28244.01..29751.62 rows=603044 width=17)
Sort Key: send_ts
-> Seq Scan on book_comment (cost=0.00..10433.44 rows=603044 width=17)
The query plan tells us how the database is going to process the query and what the possible time cost of computing its results will be. And here PostgreSQL tells us it is going to do a “Seq Scan on book_comment” which means that it will check all records of book_comment table, one by one, to sort them by value of send_ts column. It seems PostgreSQL is not wise enough to select 30 newest records without sorting all 600,000 of them.
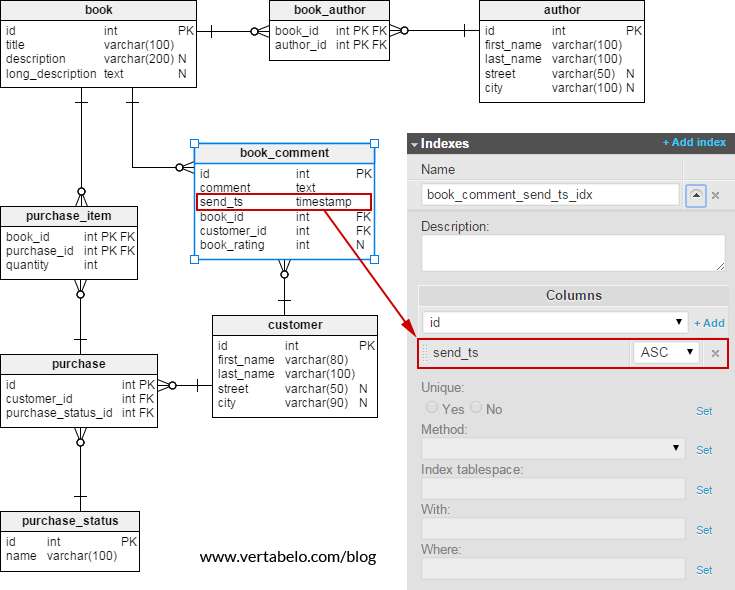
Luckily, we can help it by telling PostgreSQL to sort this table by send_ts, and save the results. To do so, let’s create an index on this column:
create index book_comment_send_ts_idx on book_comment(send_ts);
Now our query to select the newest 30 out of 600,000 records takes 67 milliseconds again. The query plan now is quite different:
db=# explain select comment, send_ts from book_comment order by send_ts desc limit 30;
QUERY PLAN
--------------------------------------------------------------------
Limit (cost=0.42..1.43 rows=30 width=17)
-> Index Scan Backward using book_comment_send_ts_idx on book_comment (cost=0.42..20465.77 rows=610667 width=17)
“Index Scan” means that instead of browsing the table, row by row, the database will browse the index we’ve just created. And estimated query cost is less than 1.43 here, 28 thousand times lower than before.
You have a performance problem? The first attempt to solve it should be to find long running queries, ask your database to explain them, and look for sequential scans. If you find them, probably adding some indexes will speed things up a lot.
Yet, database performance design is a huge topic and it exceeds the scope of this article.
Let’s just mark some important aspects of it in the hints below.
Hints:
- always check long running queries, possibly using the
EXPLAINfeature; most modern databases have it; - when creating indexes:
- remember they will not always be used; the database may decide not to use an index if it estimates the cost of using it will be bigger that doing a sequential scan or some other operation,
- remember that using indexes comes at a cost –
INSERTs andDELETEs on indexed tables are slower - consider non-default types of indexes if needed; consult your database manual if your index does not seem to be working well
- sometimes you need to optimize the query, and not the model;
- not every performance problem can be solved by creating an index; there are other possible ways of solving performance problems:
- caches in various application layers,
- tuning your database parameters and buffer sizes,
- tuning your database connection pool size and/or thread pool size,
- adjusting your database transaction isolation level,
- scheduling bulk deletes at night, to avoid unnecessary table locks,
- and many others.
The model with an index on book_comment.send_ts column:
4 – Not Considering Possible Volume or Traffic
You often have additional information about the possible volume of data. If the system you’re building is another iteration of an existing project, you can estimate the expected size of the data in your system by looking at the data volume in the old system. You can use this information when you design a model for a new system.
If your bookstore is very successful, the volume of data in the purchase table can be very high. The more you sell the more rows there will be in the purchase table. If you know this in advance, you can separate current, processed purchases from completed purchases. Instead of a single table called purchase, you can have two tables: purchase, for current purchases, and archived_purchase, for completed orders. Current purchases are retrieved all the time: their status is updated, the customers often check info on their order. On the other hand, completed purchases are only kept as historical data. They are rarely updated or retrieved, so you can deal with longer access time to this table. With separation, we keep the frequently used table small, but we still keep the data.
You should similarly optimize data which are frequently updated. Imagine a system where parts of user info are frequently updated by an external system (for example, the external system computes bonus points of a kind). Then there are also other information in the user table, for example their basic info like login, password and full name. The basic info is retrieved very often. The frequent updates slow down getting basic info of the user. The simplest solution is to split data into two tables: one for basic info (often read), the other for bonus points info (frequently updated). This way update operations don’t slow down read operations.
Separating frequently and infrequently used data into multiple tables is not the only way of dealing with high volume data. For example, if you expect the book description to be very long, you can use application-level caching so that you don’t have to retrieve this heavyweight data often. Book description is likely to remain unchanged, so it is a good candidate to be cached.
Hints:
- Use business, domain-specific knowledge your customer has to estimate the expected volume of the data you will process in your database.
- Separate frequently updated data from frequently read data
- Consider using application-level caching for heavyweight, infrequently updated data.
Here is our bookstore model after the changes:

5 – Ignoring Time Zones
What if the bookstore runs internationally? Customers come from all over the world and use different time zones. Managing time zones in date and datetime fields can be a serious issue in a multinational system.
The system must always present the correct date and time to users, preferably in their own time zone.
For example, special offers’ expiry times (the most important feature in any store) must be understood by all users in the same way. If you just say “the promotion ends on December 24”, they will assume it ends on midnight of December 24 in their own time zone. If you mean Christmas Eve midnight in your own time zone, you must say “December 24, 23.59 UTC” (or whatever your time zone is). For some users, it will be “December 24, 19.59”, for others it will be “December 25, 4.49”. The users must see the promotion date in their own time zone.
In a multi-time zone system date column type efficiently does not exist. It should always be a timestamp type.
A similar approach should be taken when logging events in a multi-time zone system. Time of events should always be logged in a standardized way, in one selected time zone, for example UTC, so that you could be able to order events from oldest to newest with no doubt.
In case of handling time zones the database must cooperate with application code. Databases have different data types to store date and time. Some types store time with time zone information, some store time without time zone. Programmers should develop standardized components in the system to handle time zone issues automatically.
Hints:
- Check the details of date and time data types in your database. Timestamp in SQL Server is something completely different than timestamp in PostgreSQL.
- Store date and time in UTC.
- Handling time zones properly requires cooperation between database and code of the application. Make sure you understand the details of your database driver. There are quite a lot of catches there.
6 – Missing Audit Trail
What happens if someone deletes or modifies some important data in our bookstore and we notice it after three months? In my opinion, we have a serious problem.
Perhaps we have a backup from three months ago, so we can restore the backup to some new database and access the data. Then we will have a good chance to restore it and avert the loss. But to do that, several factors must contribute:
- we need to have the proper backup – which one is proper?
- we must succeed in finding the data,
- we must be able to restore the data without too much work.
And when we eventually restore the data (but is it the correct version for sure?), there comes the second question – who did it? Who damaged the data three months ago? What is their IP/username? How do we check that? To determine this, we need to:
- keep access logs for our system for three months at least – and this is unlikely, they are probably already rotated,
- be able to associate the fact of deleting the data with some URL in our access log.
This will for sure take a lot of time and it does not have a big chance of success.
What our model is missing, is some kind of audit trail. There are multiple ways of achieving this goal:
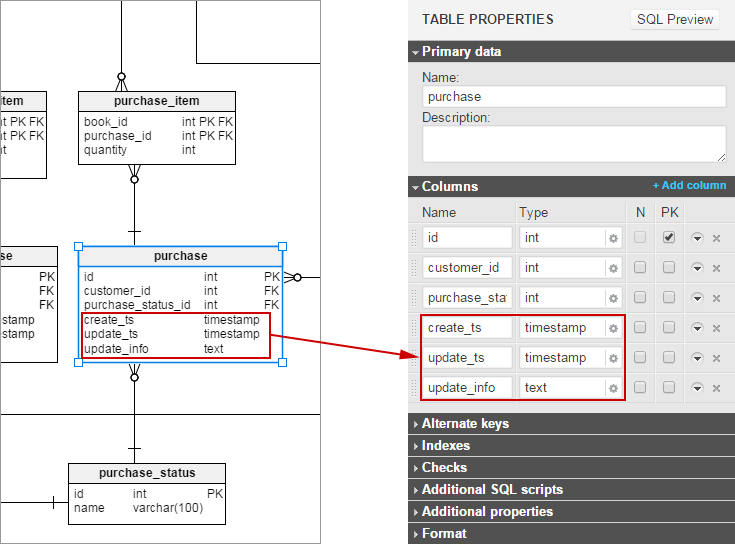
- tables in the database can have creation, and update timestamps, together with indication of users who created / modified rows,
- full audit logging can be implemented using triggers or other mechanisms available to the database management system being used; such audit logs can be stored in separate schemas to make altering and deleting impossible,
- data can be protected against data loss, by:
- not deleting it, but marking as deleted instead,
- versioning changes.
As usual, it is best to keep the proverbial golden mean. You should find balance between security of data and simplicity of the model. Keeping versions and logging events makes your database more complex. Ignoring data safety may lead to unexpected data loss or high costs of recovery of lost data.
Hints:
- consider which data is important to be tracked for changes/versioned,
- consider the balance between risk and costs; remember the Pareto principle stating that roughly 80% of the effects come from 20% of the causes; don’t protect your data from unlikely accidents, focus on the likely ones.
Here is our bookstore model with very basic audit trail for purchase and archived_purchase tables.
Changes in the model were as follows (on the example of the purchase table):
7 – Ignoring Collation
The last error is a tricky one as it appears only in some systems, mostly in multi-lingual ones. We add it here because we encounter it quite often, and it does not seem to be widely known.
Most often we assume that sorting words in a language is as simple as sorting them letter by letter, according to the order of letters in the alphabet. But there are two traps here:
- first, which alphabet? If we have content in one language only, it is clear, but if we have content in 15 or 30 languages, which alphabet should determine the order?
- second, sorting letter-by-letter is sometimes wrong when accents come into play.
We will illustrate this with a simple SQL query on French words:
db=# select title from book where id between 1 and 4 order by title collate "POSIX"; title ------- cote coté côte côté
This is a result of sorting words letter-by-letter, left to right.
But these words are French, so this is correct:
db=# select title from book where id between 1 and 4 order by title collate "en_GB"; title ------- cote côte coté côté
The results differ, because the correct order of words is determined by collation – and for French the collation rules say that the last accent in a given word determines the order. It is a feature of this particular language. So – language of content can affect ordering of records, and ignoring the language can lead to unexpected results when sorting data.

Hints:
- in single-language applications, always initialize the database with a proper locale,
- in multi-language applications, initialize the database with some default locale, and for every place when sorting is available, decide which collation should be used in SQL queries:
- probably you should use collation specific to the language of the current user,
- sometimes you may want to use language specific to data being browsed.
- if applicable, apply collation to columns and tables – see article for more details.
Here is the final version of our bookstore model:
