

Find out how to design an Amazon Redshift schema in Vertabelo.
Thanks to increasing volumes of data, analytical databases like Amazon Redshift are gaining market. We introduced Redshift support at the end of 2019; in this article, we will explain how to design a Redshift data model using Vertabelo.
How to Create a Model
Let's start with the data model creation process. To create a Redshift schema, please:
- Log into Vertabelo and click on Create new document.
- Select Physical data model.
- Select the Amazon Redshift database engine.
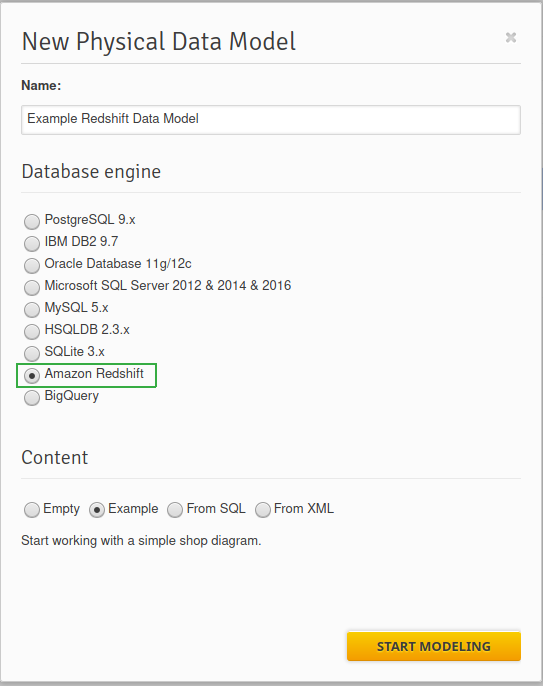
In the Content section, you can choose to begin with one of the following models:
- Empty – An empty diagram with no tables and views.
- Example – A simple shop diagram.
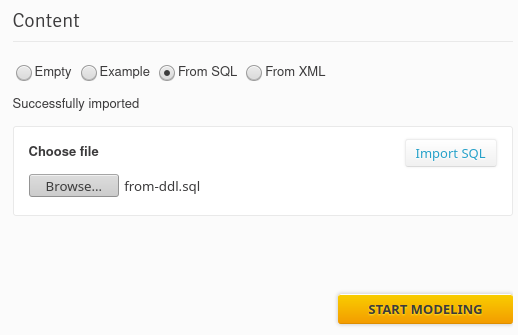
- From SQL – You provide an existing DDL file, which will be processed to extract tables and views. This is a useful option for those who migrate to our tool with an existing schema.
Here, I will cover only the simplest way to create a table. I recommend reading our table documentation before completing this step. It covers all the details required to use our tool efficiently.
To create a table, click on the Add new table icon. Click anywhere on the diagram to take an action.
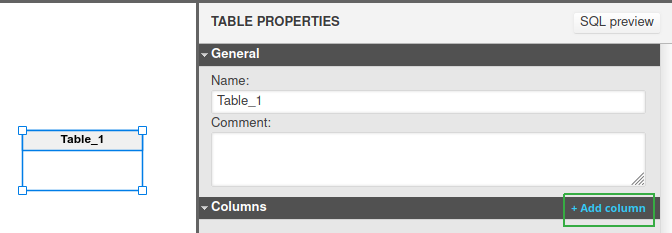
To add columns, click the Add column section in the right pane.
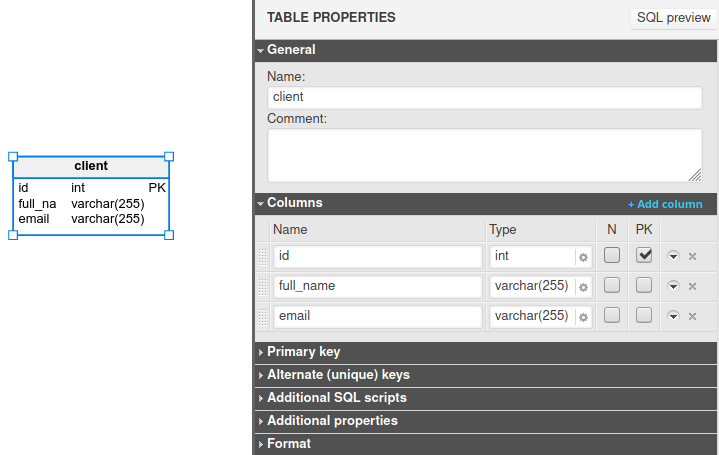
For example, a client table with three columns (id, full_name, and email) will look like this:
Data Types
In the above example, the columns have different types. To set a data type, click on the gear icon ![]() . Data types are grouped into four categories:
. Data types are grouped into four categories:
- Numeric (int, smallint, bigint, decimal, real, double precision).
- String (char, varchar).
- Date and time (date, timestamp, timestamptz).
- Other (boolean).
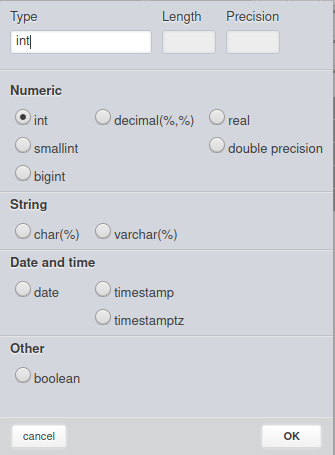
The image above presents all Redshift types (except Geometry). Please note there are no bytea or text types. This is behavior specific to Redshift, which we described in the article What is Amazon Redshift?.
Table Properties
To see table properties:
- Select a table.
- Expand the Additional properties section in the right-hand pane.
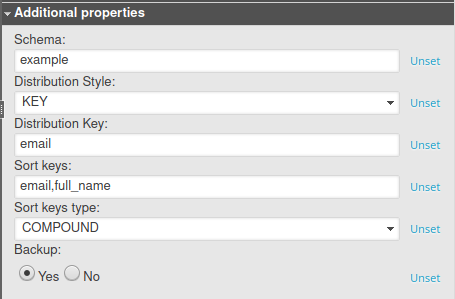
Redshift’s table properties are very limited. They are:
- Schema
- Distribution style
- Sort keys
- Backup
We’ll describe each one individually.
Schema
Like other databases, Redshift's schema is a way to group objects into a common namespace. Schemas can help organize database objects in many ways. For example, they allow many users to work on the same database, but on different schemas.
The default schema in Redshift is public.

If a schema property is set, the DDL creating that table will contain the provided value.
Distribution Style and Key

Redshift uses multiple nodes to store and process data. The way data is stored on nodes can have a huge impact on performance. Sometimes it is worth storing a copy of the table on each node; sometimes storing the whole table on one node is the better choice, and sometimes records need to be split between nodes.
Developers can indicate how to store records by setting the distribution style, which can greatly speed up query processing times. Redshift has four distribution styles:
- AUTO – The engine will set the distribution key on its own. (Redshift built-in heuristics are applied.)
- EVEN – Divides data into database nodes equally.
- KEY – Splits data on database nodes based on a group column (a distribution key).
- ALL – All nodes store a copy of the table.
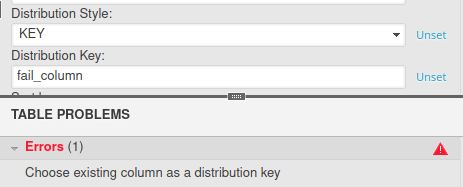
If you choose the KEY distribution style, you’ll also need to input a distribution key. It can’t be selected from a set of columns; it needs to be typed by hand. If you enter an invalid column name as the distribution key, you’ll get an error:
Sort Keys

A sort key is a group of columns (or one column) that determines the order of stored rows on a disk. A table can have up to one sort key. Possible sort key types are:
- Compound – The engine arranges data based on sort key columns order. The first column is the most important, the last one is the least important. A compound key is useful when WHERE and JOIN statements use columns which are a prefix of the sort key.
- Interleaved – Sort key columns have the same weight (importance). An interleaved key is advantageous when column’s data can’t be ordered and filter conditions use different columns.
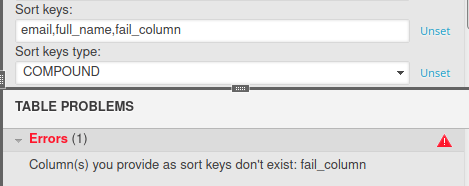
Sort key columns need to be entered manually and (if there is more than one) separated by commas. If you provide an incorrect set of columns, the problem section will send up a warning:
Backup

Tables with this option set to No will be excluded from the backup.
Primary and Foreign keys
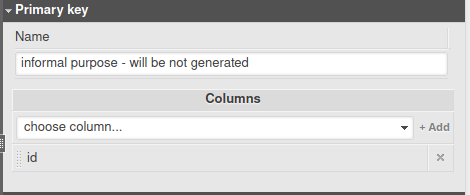
You can define primary and foreign keys for an Amazon Redshift database in the same way as for other database engines. However, constraint keys (primary and foreign keys) are not checked in a Redshift database. They are only a suggestion to the engine on how to optimize queries. Moreover, Amazon Redshift doesn't allow constraints to have names. In Vertabelo, users are allowed to enter them for informal purposes; they won’t be included in the final DDL.
Column Properties

To open column properties, click on the ![]() icon.
icon.
Comment and Default Value
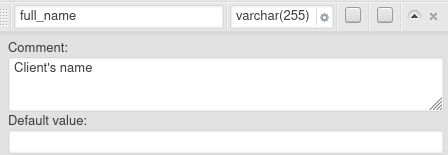
These two properties have the same role as in other database engines. Comment properties are not included in the generated SQL.
Check Expression

There is no check expression in Redshift’s DDL. This property will be ignored.
Compression Encoding

Setting the right compression encoding is a crucial part of the database optimization process. The following compression encodings are supported by Vertabelo:
- RAW
- BYTEDICT
- DELTA
- DELTA32K
- LZO
- MOSTLY8
- MOSTLY16
- MOSTLY32
- RUNLENGTH
- TEXT255
- TEXT32K
- ZSTD
- AZ64
Not every compression type is allowed for all types. Check our compression encoding compatibility list for more details.
Identity
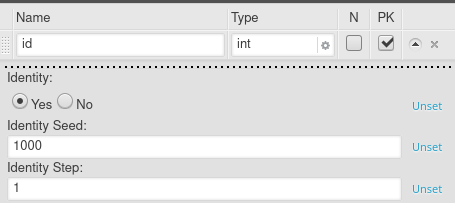
The identity property allows us to create int or bigint columns with automatically generated values. When a row is inserted, the column set as Identity will be automatically filled with the current counter value. The Identity seed is the start value of the counter. The Identity step tells the database engine how much to increase the counter value when a new row is inserted.
Other Redshift Entities
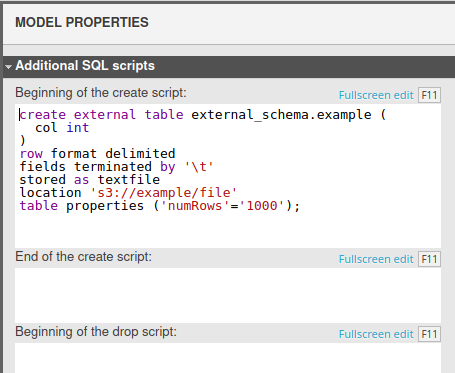
External tables
Redshifts’ external tables feature allows users to map data from other data sources into the database’s external schema. We have decided to not implement this feature at the current time. If you need to use an external table, please use the Addition SQL Script section in the model properties.
If you plan to use external tables in views, make sure to set the No Schema Binding option to “Yes” in the view’s properties (check the Views section for more details).
Views
Please refer to our comprehensive tutorial on views in Vertabelo for full details; in this article, we’ll simply add a view.
To add a view, select Add new view and click on the diagram.
After the view is added, fill in its name and SQL properties. After writing your SQL query, click Update columns, which fills the Columns section with the appropriate values.
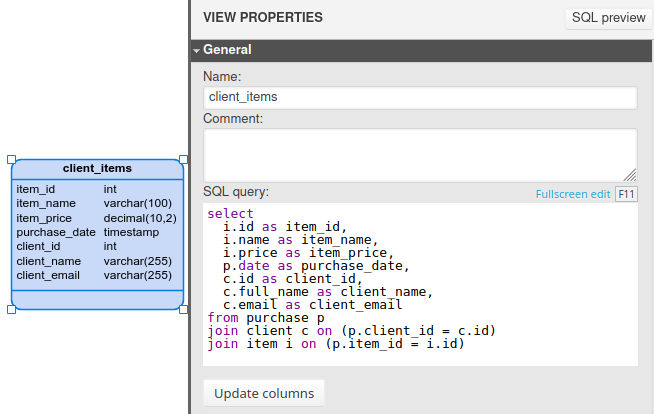
No Schema Binding

To be able to access external tables in a view’s query, you must set No Schema Binding to “Yes”.
Documentation and Migration Scripts
Generate Documentation

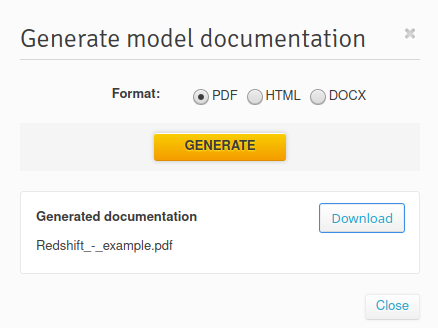
To generate documentation for an Amazon Redshift database, click on the ![]() icon and choose one of the three available formats:
icon and choose one of the three available formats:
- HTML
- DOCX
Redshift documentation contains lists of the following database objects:
- Tables and their columns
- Views
- References
Generate a Migration Script
Vertabelo can generate migration scripts for Redshift databases. You can read the comprehensive process details here.
For example, let's assume we have added the age column to the table person.
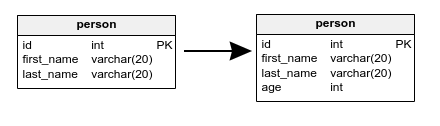
The SQL migration result would look like this:
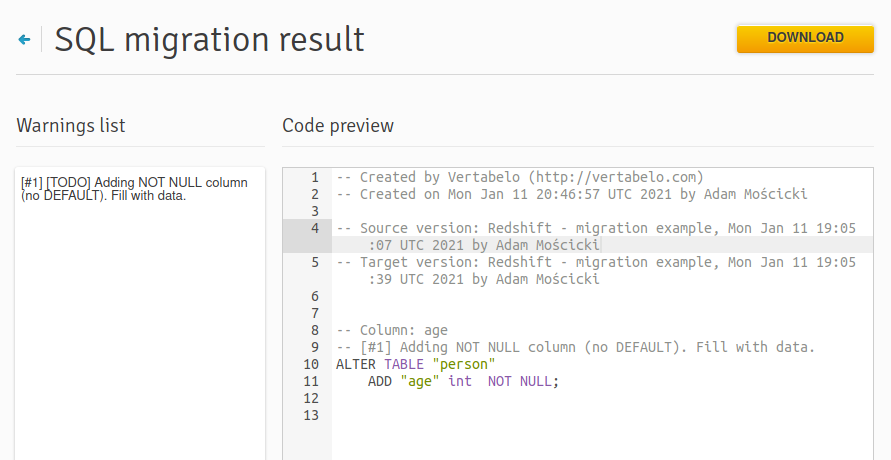
Please note that migration scripts may require further improvements or even a different approach and shouldn't be taken for granted. In such cases, the Vertabelo tool will generate a warning (as we see above). In our example, adding the age column may require setting a DEFAULT value or declaring the column NOT NULL.
Design Your Own Redshift Schema with Vertabelo
In this article, we detailed all Redshift features supported in Vertabelo. These features make designing a Redshift schema much easier.
Do you have any experience designing Redshift data models? Share your thoughts below!
