

Amazon Redshift is one of the most popular cloud databases. Could it be your data-warehouse solution? Read on to find out if Amazon Redshift meets your needs.
In 2012, Amazon announced its new cloud database system called Redshift. Basically, it is a data-warehouse solution intended for analytical systems, which can handle huge volumes of data—up to 1 petabyte (1024 TB). Amazon Redshift is available as a service (Database as a Service) and is a part of a bigger cloud ecosystem called Amazon Web Services (AWS).
Why “Redshift”?
In physics, electromagnetic radiation shifts toward red when the source of radiation moves away. This phenomenon is called redshift. So, when we heard the name of Amazon’s database for the first time, we wondered if it's somehow connected to this physics term.
We later learned that indeed it is. One of the reasons for creating Redshift was to move away from the solutions provided by a company with a red logo (Oracle). And of course, Redshift extends the AWS cloud migration offer and earns money.
Business Intelligence and Analytical Systems
The motto “Knowledge is the Key to Success” also found its meaning in the IT world. Nowadays, computer systems have enough capacity and computing power to store a large load of data. Sometimes somewhere within the data are hidden insights to gain an advantage over the competition.
Technologies and algorithms used by companies to perform analytical processing on data are part of Business Intelligence (BI). Amazon Redshift is a perfect example of BI technology. Typical BI tasks include:
- Gathering data from many sources and combining them into one source (all applications following ETL pattern).
- Creating data reports (e.g., how customers spend their money).
- Conducting event analysis, like finding patterns of user behavior.
- Much more.
Analytical systems differ from traditional applications (e.g., an online shop). Traditional applications find use in online transaction processing (OLTP) systems, which are focused on data consistency and fast response. However, in analytical systems, different solutions are needed for storing and querying many records, and typical OLTP systems have no great use.
Later on, we will explain how Amazon Redshift deals with analytical processing. Experienced engineers may recall the term OLAP (Online Analytical Processing). OLAP was created in response to OLTP and grouped analytical technologies. In recent years, the OLAP acronym has been replaced by the simple phrase analytical system.
Cloud vs. On-Premises
After explaining the nature of analytical processing, we will describe what cloud means. The simplest way is to define a traditional on-premises application:
- An on-premises data warehouse is a handcrafted solution where we need to provide almost everything on our own:
- space, electricity, and hardware,
- an engineering team to develop and maintain a solution,
- budget, time, and effort for the initial setup.
On-premises can be the only choice because where the data is stored is somehow restricted (e.g., by the law). Well-fitted on-premises solutions can produce better query performance than the cloud. An example of an on-premises data warehouse tool is the Teradata database.
- A cloud data warehouse is a solution in which all of the requirements mentioned in the previous point are provided by the cloud provider (like Amazon). Users choose already configured computing nodes that fit their needs. There is no initial investment required. Users are charged accordingly for the hardware they use. It is also possible to use a warehouse for a certain period of time (pay as you go). Cloud providers offer multiple geographic locations. Amazon Redshift is an example of a cloud data warehouse.
Some solutions, like Oracle’s, are eligible for both warehousing solutions. However, Amazon Redshift cannot be deployed on on-premises machines.
Redshift Is Based on Postgres 8.0.2
The Redshift project started as a fork of another database, Postgres 8.0.2, released in 2005. It may sound suspicious that Amazon announced its product 7 years later in 2012. Why fork an older version?
Well, Redshift is not a ground-up project. Instead, it is a result of investments in ParAccel's technology, which was based on Postgres 8.0.2.
The final product is significantly different from its origin. The way the database works was greatly redesigned to make processing big volumes of data possible.
Despite these modifications, the Data Definition Language barely changed. Thanks to this, Redshift’s syntax is very similar to Postgres, making Redshift easier for those who have used Postgres before.
Important Aspects of Redshift’s Architecture
To get a better understanding of the crucial parts of Redshift’s database design and its features, we will outline how the query processing works. Because of the limited capacity (memory- and computing-wise) of hardware devices, querying big data is based on distributed processing run on many machines.
Hadoop is the first broadly known analytical tool using distributed processing. Hadoop uses a Map Reduce approach, which has its own limits. There is no SQL support by default, and the requirement to use a Hive extension for SQL.
However, Amazon Redshift uses Massively Parallel Processing (MPP). In this approach, fast processing is achieved by keeping the data optimized.
For instance, a typical relational database is row-oriented, while an MPP database like Amazon Redshift stores data in a column-oriented manner. Computing nodes can exchange the data. As a result, Amazon Redshift uses SQL as the main query language in every computing state.
One of the most important features of an analytical solution is the time needed to query many records, sometimes even the whole database. To make it efficient, Redshift’s developers changed many aspects of its design.
Most Notable Changes To PostgreSQL’s DDL
- The data types were limited to:
- numbers,
- text types up to 64KB,
- date types, and
- boolean type.
There are not any types for binary objects or unlimited text. Why? Binary objects can't be easily queried, so they have no analytical use. If a user needs to store binary objects, the solution is to add an anchor to an S3 bucket. Similarly, unlimited text should be processed and split somehow first in order to be easily analyzed.
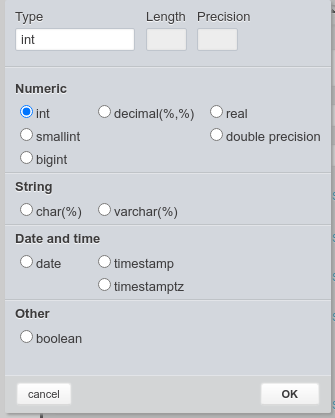
Type selector for Redshift, available in the Vertabelo database modeler.
- Referential integrity constraints are not checked. They still exist in the DDL, but they only have an informal meaning for the query planner. As stated before, constraints are not very important in an analytical system.
- Indexes were removed. Instead, sort keys were introduced. In a column oriented database creating an index makes less sense compared to normal RDBMS. Instead, Redshift’s developers added sort and distribution keys to help optimize query processing. A sort key is a group of columns (or one column) that determines the order of stored rows on a disk. Tables can have only one sort key.
- Distribution styles were added. Distribution styles tell the database how to store records on multiple nodes. Users can leave a decision to be done by the engine (AUTO distribution style) or can set it by hand with the following styles:
- EVEN - divides data into nodes equally.
- KEY - splits data based on a group column (a distribution key).
- ALL - all nodes store a copy of the table.
-- Created by Vertabelo (http://vertabelo.com) -- Last modification date: 2020-11-29 20:18:28.736 -- tables -- Table: example_table CREATE TABLE example_table ( primary_column int NOT NULL, second_column int NOT NULL, PRIMARY KEY (primary_column)) DISTKEY (primary_column) SORTKEY (second_column); -- End of file.
An example of a DDL with sort and distribution keys.
- Sequences were removed. In Postgres DB, sequences are used to generate unique identities. In Amazon Redshift, they were removed. As a replacement, an identity column type was added.
- Compression encoding types were introduced. To store data more efficiently, many compression encoding types were introduced. Choosing the right data compression can speed up query time. The thinking behind that feature is very simple: the slowest part in processing is reading from disk, so less data to read means less time is required to process. There are encodings designed for specific data types. In my opinion, the reason to limit data types was driven by introducing compression encoding types. It is much simpler to encode fewer data types.
- External tables were added. It is possible to create a table that is a mapping to data stored in S3. Details about how it can be used will be described later.
Important Postgres Features Still in Amazon Redshift
- Transaction Support: Despite its analytical character, Amazon Redshift still supports database transactions. The only isolation level supported is read-committed, which means that queries see the last committed version of the data.
- Procedure Support: The support for stored procedures remains in Amazon Redshift. The procedural language supported is the same as in PostgreSQL: PL/pgSQL. Each procedure is run as a separate database transaction.
How To Design a Redshift Database
Database architects need to know the limits and features of a tool to use it well. Amazon Redshift is destined for analytical processing, which means that typical design patterns can’t or even shouldn’t be applied.
Instead, more practical, optimized processing purposes need to be chosen. Some analytical (OLAP) design patterns abandon database normal forms. Others allow data to be duplicated. An example of a design pattern for OLAP is a STAR schema.
The other side of the same coin is to design a schema so that the full capabilities of the hardware are used. To achieve full Redshift power, it is important to set sort keys and distribution styles properly. Well-chosen keys and column encoding types can significantly speed up query execution.
Is Redshift Still RDMS?
There are strict definitions of relational databases, like Codd’s 12 rules, which have no direct use. In practice, however, a database that stores data in a structured manner as a group of tabular data sets (with rows and columns) can be labeled as relational.
Sometimes, databases with an SQL interface are regarded as relational. Either way, both definitions are achieved by Redshift, and we believe we can call it an RDBMS system. Nonetheless, however we define a relational database, our Vertabelo database tool fully supports Amazon Redshift.
Creating a database model in Vertabelo.
Redshift & AWS: A Perfect ETL Environment
Amazon Redshift gains full power when combined with other Amazon solutions. As mentioned before, Redshift supports the external tables feature allowing users to query S3 storage.
This feature has its own name: Redshift Spectrum. Redshift Spectrum works as an add-on to the Redshift cluster and requires additional computing resources.
Amazon Redshift can be combined with other data sources by AWS Glue. As you can maybe guess, AWS Glue allows users to set one database as a source from which data will be loaded to another.
This makes Amazon Web Services a top-notch tool for Extract Transform Load processing. Also, Redshift is the perfect destination for a Load step and, frankly, all ETL steps.
Redshift’s Snapshots in S3
Sometimes, one of the system requirements is to provide a way to restore data to a particular point in time, or simply, to restore a database from a snapshot or backup. There is a little difference in meaning between snapshots and backups. However, backups have a broader usage because they can be restored anywhere.
For a closed-cloud data warehouse system like Redshift, making snapshots is more appropriate and is sometimes the only option. Snapshots are stored in Amazon’s S3 service, and users are allowed to:
- choose a very flexible schedule format, in a similar fashion to a Unix’s cron solution,
- transfer snapshots to other service regions,
- exclude tables from being snapshotted, and
- restore particular tables from a snapshot.
Encryption Support in Redshift
Many engineers are worried that cloud solutions are vulnerable to data leakage. Amazon Redshift is equipped with encryption support on many levels. All data transfers are done in a secured network layer. Not only are data blocks encrypted but also system metadata and all snapshots.
Amazon designed a hierarchical system grounded on symmetrical AES-256 encryption, allowing each data block to be encrypted by different cipher keys. Those keys are encrypted by another AES-256 key called a database key and then a cluster key. At the top, a cluster key is encrypted by a master key chosen by the end-user.
A master key can be symmetric or asymmetric. Amazon has a special service to manage keys: Key Management Service. Users are even allowed to set up remote hardware security modules. We believe that all security needs will be satisfied by the protection measurements provided.
Creating a Redshift Cluster
To create an Amazon Redshift cluster, users need to have an account on the AWS platform first. The UI is very intuitive compared to the Google Cloud Platform and Microsoft’s Azure. After selecting the region where the database will be run, users need to choose:
- Node types on which Redshift will be run (nodes have different CPU power, RAM and disk type, and capacity).
- Database name, username, and master password.
- Network group and access policies.
- Encryption type (optional).
- Snapshots policy.
- Maintenance hours.
The AWS Command Line Interface also supports creating a Redshift cluster. The CLI tool is useful when a more automatic way of managing clusters is required.
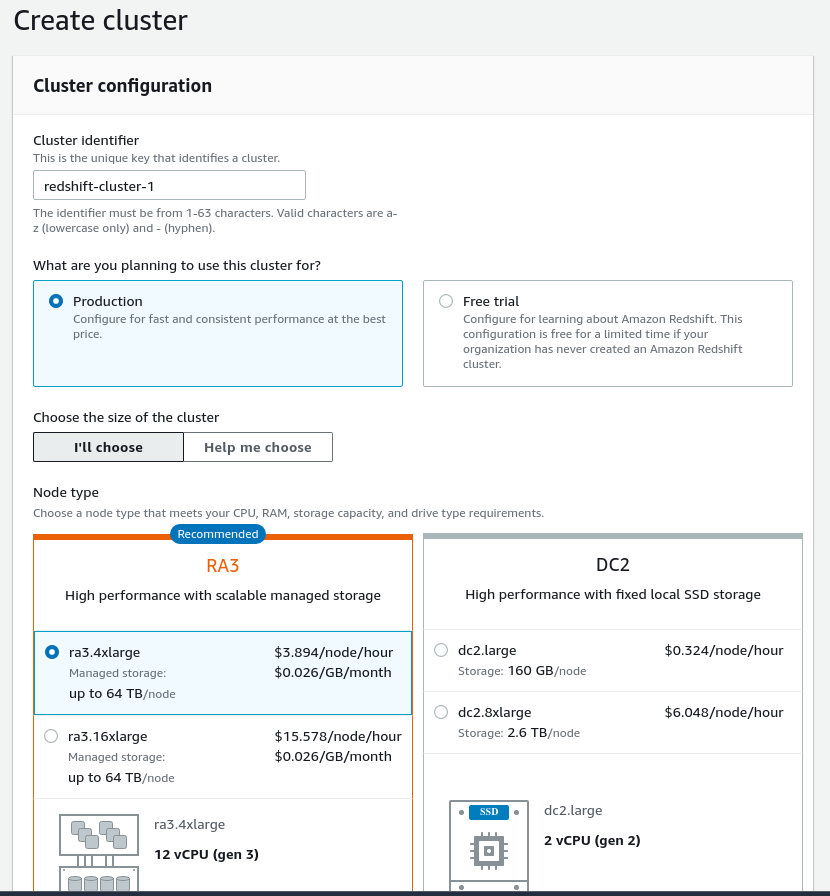
Creating a Redshift cluster in Amazon Web Services.
Amazon Redshift Pricing
Price is one of the most important, and at the same time not very technical, aspects of choosing the right tool for a problem. Unfortunately, it is the most complicated part of Amazon Redshift, and cloud services overall.
Firstly, Redshift nodes are available in two payment schemas:
- On-demand, where we pay for each hour a database is running, and we can stop using it at any time. This is an adequate schema for building a proof-of-concept application. Another usage scenario is when we need to run tasks on a few days per month. This is a more expensive payment schema when used longer.
- Reserved-instance, where we commit to using nodes for an extended period, at least one year. With the commitment, there is a discount, which makes the final price much lower. This is a cheaper schema, and if we pay upfront, even more of a discount is applied.
Secondly, the types of nodes we choose have different prices. The more powerful and efficient nodes we need, the more price we pay.
Finally, some additional features like Redshift Spectrum require additional computing nodes. If our solution uses it, we need to pay an additional fee. For example, each TeraByte located in S3 scanned by the Spectrum engine costs $5.
Fortunately, Amazon created a calculator that helps to estimate the final price. For instance, a cluster built on the two cheapest nodes costs $179 per month in the on-demand schema. If we reserve the same cluster for one year and pay upfront, the final price per month is $100. It is worth noting that Amazon gives a free trial for new users.
Summary
Amazon Redshift is a user-friendly data warehouse that should satisfy any analytical need. It is especially a good choice for those who already use the AWS platform.
It requires some additional knowledge in terms of schema designing but at the same time keeps it as simple as possible. Also, Postgres' roots make Redshift’s DDL very easy to understand and follow.
If you choose Amazon Redshift as a database, please remember that you can use Vertabelo to design a schema.
