

The relational database management system is the backbone of every database. No matter what relational database you work with, you’ll be using its RDBMS to interact with its data.
What Does RDBMS Stand for?
The acronym “RDBMS” stands for “relational database management system,” which is the part of the database that allows you to interact with the data.
Sometimes alternate acronyms are used, especially “DBMS” in relation to a database that is not necessarily relational. If you’re not familiar with why relational tables are “relational,” then we have a short article to clear that up for you.
What Is an RDBMS?
A relational database management system (RDBMS) is, as the name suggests, software that manages a relational database. It is a set of smaller programs designed to work together, allowing the developer to store, access, and modify data in tables, transparently and without having to know where the data is physically stored on disk.
You can interact with any relational database management system by using the SQL programming language. SQL stands for “Structured Query Language”, which allows you to interrogate structured data stored in tables.
Once you finish reading this article, we recommend looking at one of our courses that teach you the basics of SQL, since practice is the first step to database mastery.
What Does an RDBMS Actually Do?
As mentioned earlier, a relational database management system allows developers to store and handle data in relational tables.
There are many components that build the core functionality of an RDBMS, each of which executes specific actions on a database. The diagram below shows some of the main functionalities an RDBMS provides when you interact with a database.
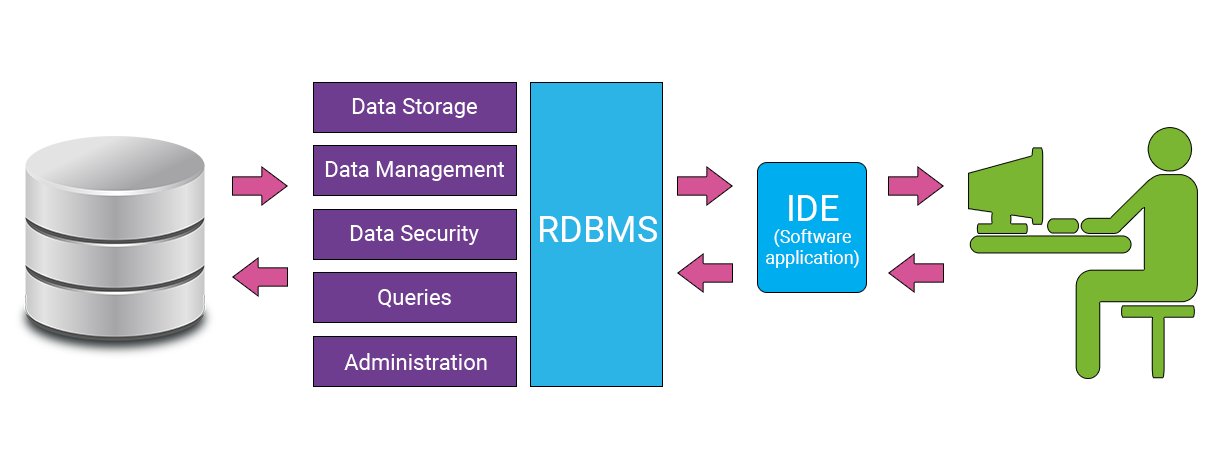
Next, we will go into a bit more detail about the main components that make up an RDBMS.
Data Storage
A relational database management system allows the user to create relational tables, which are the structure for storing and retrieving data.
The storage module works at the lowest level of the database. It takes care of how the data is organized on disk, where the data is actually stored on disk, how the data moves when you make an update to some values, and how and when empty spaces are handled when you delete data.
In a relational database, all the data and tables are stored into what are called “database files.” These are the files with which the storage module works.
Data Management
Once we have created our database and our initial tables, we can insert data into them. For that, we interact with the data management module. The data management module manages the physical storage of data and works closely with the data storage module.
The module allows the developer to do data lookup operations through SELECT statements, data modifications through UPDATE statements, and data removal through DELETE statements, among other things.
An RDBMS actually has a more extended API that allows the developer to interact with it and perform multiple types of operations. These operations for interacting with the data are split into four major categories: DDL, DCL, DML, and DQL.
DDL Operations
DDL operations are the first type of operations you will execute on your database through the RDBMS once it is installed.
DDL stands for “data definition language.” It is a list of SQL commands you can use not only to create your first objects in a database (such as tables) but also to make changes (such as adding new columns). They are not limited to creating tables; they can create other objects in a database as well.
The DDL statements begin with the same common keywords:
CREATEis used to create any type of database object, for example, tables.DROPis used to delete any database object including tables, users, functions, etc.ALTERis used to modify any object in a database.TRUNCATEis used to remove all the data from a table.
DQL Operations
DQL operations are executed to query the data from the tables. DQL stands for “data query language.” There is only one keyword used for DQL operations: SELECT.
Most of the queries you will write when interacting with a database will be SELECT queries. They take data from the tables and return it to the application from which the database was queried, be it your IDE or a website.
When an RDBMS executes an SQL query, it tries to return the data in the most efficient way possible by minimizing the resources used by the database to find the data on disk. It then retrieves it into memory and finally sends it back to your application.
But DQL operations aren’t limited to just returning data. You can also ask to do computations, like calculating the average hours worked by an employee per month or even multiplying the values between two or more columns and return the result.
DML Operations
DML stands for “data manipulation language.” DML operations in an RDBMS are used to modify the data already stored in tables and use the following types of commands:
INSERTis a command used to insert data into tables.UPDATEis a command executed on a table to allow the user to modify values in columns.DELETEis a command that allows the user to delete entire rows from a table.
DCL Operations
DCL stands for “data control language.” DCL operations in an RDBMS are specifically targeted for the administrator of the database. They provide user management features, allowing the administrator to set different combinations of permissions for each user who accesses the database. The DCL commands are the following.
GRANTis a command that allows the administrator to grant privileges to a user for accessing or even modifying database objects.REVOKEis a command that allows the administrator to remove privileges from a user, thus restricting the types of operations the user can perform.
Through different combinations of GRANT and REVOKE commands, the administrator can set privileges for reading or modifying data, or even both, for any user with access to the database.
The administrator can allow a user to add data to a table and even update it, like a salesperson might add information about a new customer or update the customer’s order status; in this case, the salesperson might be eligible for a finder’s fee based on successful customer conversions. Alternatively, the administrator can deny privilege for inserting or modifying data into a table but allow access to read that data, like a manager reading a report with data about sales and number of customers.
Through DCL operations, the administrator can control which user has access to each table and even prevent some users from authenticating on the database or accessing certain tables.
Data Concurrency
An RDBMS provides data concurrency, which allows the administrator as well as other users to concurrently use the same database and perform different operations. It provides concurrent access not only to multiple users but also to applications and reports that might be connected to them. For example, an online reservation system that allows you to book your hotel and vacation supports hundreds of users at any given point.
Users can read and modify data in the database at the same time. The RDBMS offers different mechanisms that allow users to work at the same level of information concurrently, provided they are not making changes to the same row and the same column of the same table. We will go into more detail about these mechanisms next.
Data Consistency in RDBMS
Two or more users making changes at the same time on the same piece of data can cause conflicts and inconsistencies in the database. This is avoided by a set of mechanisms implemented by an RDBMS: transactions and locks.
Transactions
A database transaction executed by an RDBMS can be considered as a unit of work on the data the user sends back to the database to be applied. Each transaction consists of the entire set of changes the user makes, up to the point where either the user presses a button or runs a command to apply that transaction.
For example, imagine you’re purchasing something online using your credit card. When you pay at the checkout, the process consists of successfully taking the amount out of your account and adding it to the merchant’s account. These are two separate tasks, but they must be treated as one operation. If there is any error during the process, everything must be reverted to the original state. For example, if there is an error after it takes the money out of your account, your money needs to go back into your account and the merchant does not receive the money. This is the role of a transaction – either everything runs successfully, or everything is returned back to its original state.
Locks
A database lock is used to “lock” a table or a row of data or even just a column of data in a single row, so that only one user can modify it at any given moment.
Through locks and transactions, the RDBMS prevents two users from applying their changes at the same time or accidentally overwriting each other with unwanted changes.
ACID Principles
All modern relational database management systems run modifications on data stored in tables as transactions. There are logical principles so that the transactions work correctly.
The ACID principles are a foundation for all RDBMSs. They are composed of the following rules.
- “A” stands for “atomicity.” It guarantees that either all the changes made by a user are applied to the table or no changes are applied at all.
- “C” stands for “consistency.” It guarantees that the execution of a transaction keeps the database and its data in a consistent state.
- “I” stands for “isolation.” It allows for multiple transactions to execute at the same time with transparency to other users, provided they do not change the same data.
- “D” stands for “durability.” It ensures that once a transaction is committed and applied, it will remain committed even if the database shuts down.
Basic Data Internals in an RDBMS
Constraints
In addition to preventing users from making changes to the same piece of information at the same time, transactions can also deny users from inserting incorrect data into certain columns. For example, you can prevent a user from accidentally inserting an order for a client that does not exist in the database.
This kind of action is performed through a database constraint, either at the table level or at the column level. A constraint will verify that the data the user is trying to insert is consistent with what is expected to be stored in that column.
Indexes
Having all the correct data inserted in our database is only half of the job. Data is useful only if you can also access it, so a database must allow a user to query the data and return the results as fast as possible.
One of the mechanisms through which the querying performance is ensured is the table indexes. As a general rule, when you have a slow query, you should create an appropriate index to speed up the retrieval of data.
When running a query to return data from a database, the RDBMS uses indexes to build the right query execution plan. When a query is executed, the database will look at the indexes it has available, some statistics about the data stored into tables, and other metadata information. Using all of these, it will try to estimate the best plan of how it is best to execute the query and bring back the data, so that the resources used are minimal and the query execution time is the shortest.
Basic Administration Capabilities
In addition to allowing administrators to grant and revoke access to tables and data in a database, a relational database management system provides the administrator with an extra set of tools.
These tools and commands let the administrator backup the database, so that there is a copy of the database in case anything goes wrong with the database system. Once a backup is created, the RDBMS also allows the administrator to restore the database and bring it back online.
The RDBMS also provides the commands to allow the administrator to look at the metadata about the tables. For example, the administrator can find out the column names of each table in a database and the types of data stored in each column (such as numeric or text). The administrator can also see how many rows are in each table in the database and monitor this number, in case some proactive work is needed to prevent the database from having problems.
Basic Security Capabilities
When a user needs to have access to data from multiple tables but only to specific rows, the RDBMS allows the administrator to create a restricted view of the data and give the user access only to that view.
If the change a user needs to make is more complex, but if the administrator does not want to give the user access to the tables, the administrator can create a stored procedure.
A stored procedure is a piece of SQL code which encapsulates some business logic. It is similar to a function or method in any programming logic, and you can pass parameters to it. It will then execute a piece of code with that data and apply changes to the database.
In some cases, organizations need their data to be even more secure even if it is stored in tables to which no users have been granted access. Preventing maliciously intended people from gaining access to the data is one such scenario. The RDBMS provides the administrators with capabilities to further encrypt the data in the database, so that even if access to the data is obtained, it won’t be usable.
RDBMS Performance Capabilities
For mission-critical systems, access to data needs to be uninterrupted and with very quick response time. An RDBMS allows creating copies of the same database to work together in a distributed architecture.
These copies can be distributed on multiple servers where they can communicate, synchronize, and exchange data with each other.
Most Popular RDBMSs
Most modern relational database management systems provide all of the functionality mentioned in this article and more. The most popular and widely used RDBMSs around the world include:
Almost all of these allow you to interact with them using basic SQL queries. However, they all have their own, slightly adapted version of the general SQL language, so more complex queries do not always have the same syntax in two different systems. For example, a query to return the 10 most recent orders from the orders table in MySQL is different from how you would write it in SQL Server.
The MySQL version:
SELECT * FROM ORDERS ORDER BY ORDER_DATE DESCENDING LIMIT 10;
The SQL Server version:
SELECT TOP 10 * FROM ORDERS ORDER BY ORDER_DATE DESCENDING;
Real World Use Cases of an RDBMS
Almost all of the data in the world is stored in databases or otherwise passes through an RDBMS in order to get queried and accessed by a user or an application.
The most popular use cases for the relational database management system can be found in the banking sector, where banks need to keep track of financial transactions in a customer’s account. Whenever you ask for a statement from your bank, the data is queried through an RDBMS and returned to you. All of your account transactions are stored in relational tables inside a database so that they are easily found any time you search for them.
When you go online and shop on Amazon or other retail companies, you log into your account, browse the list of available items, and put them in your shopping cart. You are querying an RDBMS behind the scenes.
Essentially, whenever you want to store data in a structured and organized way and you need to know where the data is so that you can query it, it is recommended to implement it in a relational database.
Designing Your own Application
When you want to build your own database with an RDBMS, it is helpful to break your problem into logical entities. To lay out all of the entities to solve your problem, it’s a good idea to start out by building an entity-relationship diagram or an ER diagram. If you aren’t sure why this is a good idea, we at Vertabelo have an article that might help you.
If we’ve convinced you about drawing an ER diagram before creating your database, but you’re unsure where to start or how to use an ER diagram, Vertabelo has both the tools to help you with designing your ER diagrams and a tutorial on how to use our tools.
Keep Learning About RDBMS!
Did you enjoy our article? We hope that you learned a lot of new things or that we clarified some things you already knew but didn’t understand well about the relational database management systems. We invite you to continue browsing our blog and learn more about the world of RDBMS!
