

Denormalization in databases is an optimization technique for improving the performance of certain queries. We may need to apply denormalization when the usual normalization incurs some performance penalties. This is often the case when the data volume has changed but we cannot extend the database resources anymore.
Denormalization aims to improve query performance in a database. When data volume grows, we may not be able to extend the database resources anymore. In these cases, we may need to apply denormalization techniques.
Before we start, let’s clarify normalization and denormalization in SQL. We briefly explain what these concepts are. We then go through an example of a normalized database with performance problems, apply denormalization, and explain how this improves performance.
What Is Normalization?
Let’s refresh our memory about what normalization is and why it is used. Normalization is a database design process used mainly to minimize data redundancy in tables. In a normalized database, each piece of information is saved only once and in one table, with relationships pointing to other tables. As an additional benefit, we also avoid certain edge situations in which we may encounter update anomalies.
Normalization is applied by using one of the three normal forms. The most common form is the 3NF normal form. Sometimes, this normal form is not strict enough; for that reason, the Boyce-Codd Normal Form was invented. For more in-depth reading, I recommend this great article, “A Unified View on Database Normal Forms.”
What Is Denormalization?
Now that we have clarified what normalization is, the concept of denormalization in databases is relatively simple. Normalizing results in data being split into multiple tables; denormalizing results in data from normalized tables brought in a single table.
The goal of denormalization is to move data from normalized tables back into a single table to have the data where it is needed. For example, if a query joins multiple tables to get the data but indexing is not sufficient, denormalizing may be better.
We trade data redundancy and data storage for an improvement in query time and possibly in resource consumption during query execution. Denormalization has some disadvantages and may bring its own set of problems, but we will discuss that later.
Evaluating a Normalized Model
Whenever we consider denormalization, we need to start from a normalized data model.
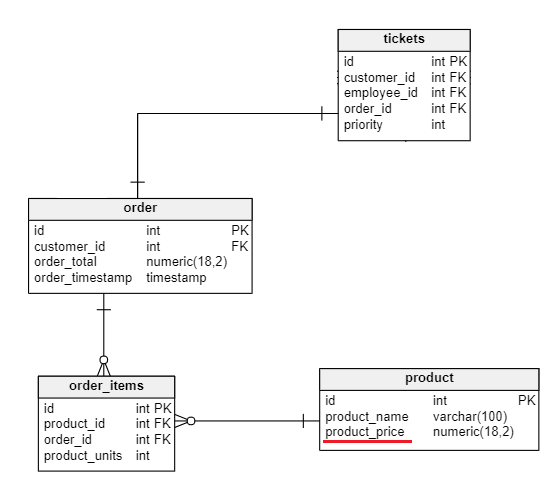
We will use the model below for our example. It represents a part of the data model for an application to track orders and tickets submitted by customers about their orders.
As we see, the data is perfectly normalized. We do not find any redundancies in the data stored other than the columns needed for maintaining the relationships.
Let’s take a quick look at the tables, their structures, and the types of data stored:
- The
customertable contains basic information about the customers of the store. - The
usertable contains the login information for both customers and store employees. - The
employeetable contains information about store employees. - The
ticketstable contains information about the tickets submitted by customers about orders they have placed. - The
calltable contains information about the calls between customers and customer support representatives about the tickets. - The
call_outcometable contains information about the outcomes of the calls. - The
ordertable contains basic information about orders placed by customers. - The
order_itemstable contains many-to-many information, linking the products customers bought in the orders. It also stores the quantity of each product ordered. - The
producttable contains information about the products customers can order.
This normalized data model is acceptable for a relatively small amount of data. As long as we pay attention during the design of the data model and take into consideration the types of queries needed, we shouldn’t have any performance problems.
Adding new Business Requirements
Suppose we have two new requirements from the business.
First, each customer support representative needs quick access to some metrics about the customer at hand. The new functionality in the application needs a dashboard about the customer with total sales, the number of tickets submitted, and the number of customer service calls.
Second, customer support representatives need a ticket dashboard with a list of tickets and their respective details quickly. They need this for selecting tickets to address based on priority.
Because our data model is normalized, we need to join quite a few tables to get all of this information: customer, tickets, call, order, order_items, and product. As the data grows, this query consumes more and more resources. We need to find a way to improve performance since indexing does not give us the best performance in this case.
Applying Denormalization
We apply denormalization to our data model to improve performance. As we have mentioned, it takes a step back and increases data redundancy in return for faster queries.
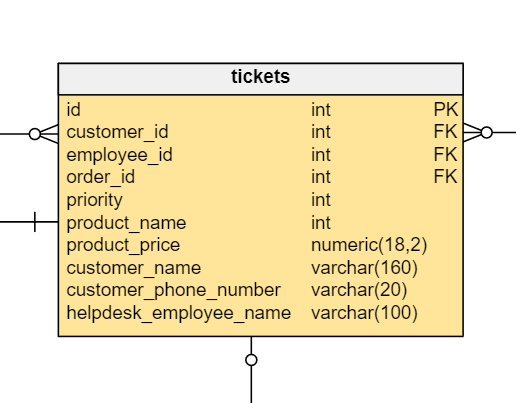
The denormalized version is below with the fixes for our performance problems.
We have made changes to address the new business requirements. Let’s break down the solution for each problem.
Customer metrics dashboard. We create a new table,
customer_statistics, highlighted in green in the data model. We use this table to store up-to-date information about each customer’s buying habits. Every time a change is made through the application, the new data is stored in appropriate normalized tables andcustomer_statisticsis updated. For example, when a customer places a new order,orders_total_amountis increased by the total of the new order for that customer.
The ticket dashboard for customer support representatives. We denormalize the data in the tickets table and add additional columns containing the information we need. The application then reads all summary information from one table without joining customer, tickets, call, order, order_items, and product. It is true we now have duplicate information regarding product names, prices, customer names, phone numbers, etc. But the execution time for our query is now much shorter, which is the goal.
When to Apply Denormalization
Performance Improvements
As we have mentioned, one of the main situations for applying denormalization is when we are trying to solve a performance problem. Because we read data from fewer tables or even a single table, it usually makes the execution time much shorter.
Maintaining History
Sometimes, applying denormalization is the only way to address business requirements. Specifically, you may need to maintain history by denormalizing.
In our example, consider the following scenario: the customer support representative has noticed the price paid for a product does not match the price shown on the dashboard. If we look closely at our initial data model, product_price is available only on the product table. Each time the representative opens the dashboard, a query is executed to join the four tables below.
But because the price has changed since the time the order was placed, the price on the representative’s dashboard no longer matches the amount paid by the customer. This is a big issue in functionality and one scenario in which we need the history of the price for each order.
To do this, we have to duplicate product_price in the order_items table so that it is stored for each order. The table order_items now has the following schema.
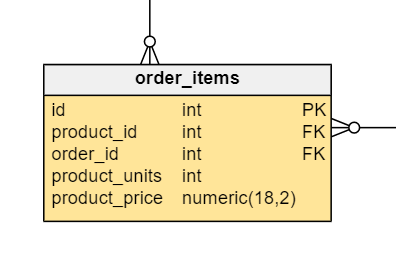
We can now take the product_price value at the product-order level, not just at the product level.
Disadvantages of Denormalization
Although denormalization provides great benefits in performance, it comes with tradeoffs. Some of the most important ones are:
Updates and inserts are more expensive. If a piece of data is updated in one table, all values duplicated in other tables need to be updated as well. Similarly, when inserting new values, we need to store data both in the normalized table and in the denormalized table.
- More storage is needed. Because of data redundancy, the same data takes up a lot more space depending on how many times it is duplicated. For example, the updated
ticketstable stores the customer name twice, as well as the name of the support representative, as well as product and other information.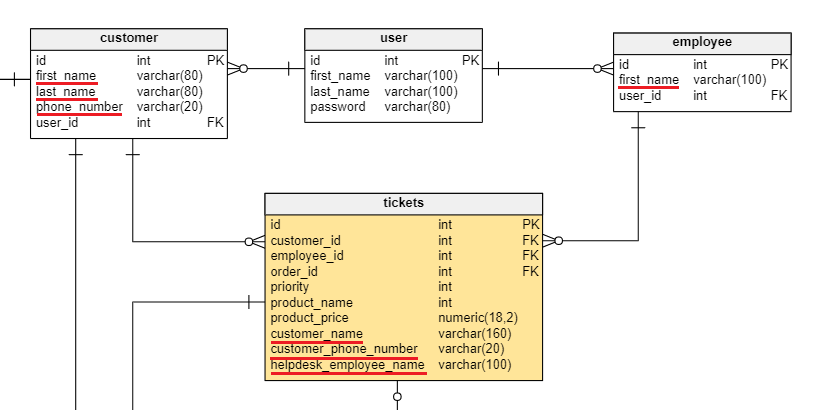
- Data anomalies may result. When updating data, we need to be aware it may be present in multiple tables. We need to update every piece of duplicate data.
- More code is needed. We need additional code for updating the table schemas to migrate the data and to maintain the consistency of the data to achieve the same functionality. This needs to be done through multiple
INSERTandUPDATEcommands as soon as new data comes in or old data is modified.
Denormalization Does Not Have to Be Scary
Denormalization is not something to be afraid of. Before you start denormalizing a normalized data model, make sure you need it. Track the performance of the database to see if it degrades, then analyze the query and the data model. If there is indeed a problem in accessing the same data frequently, then denormalizing some tables is likely an option. If you evaluate the need for it and track the changes made, you shouldn’t have any problems.
