

To implement multi-language support in your data model, you don’t need to reinvent the wheel. This article will show you the different ways to do it and help you choose the one that works best for you.
The concept of localization is vital to the development of a software application, particularly when that application’s scope is global. Support for multiple languages is the main aspect to consider; a database design that supports a multi-language application allows you to diversify your target markets and thus reach many more customers. Besides, such a database design could be part of your long-term strategy for designing localization-ready systems.
The key to incorporating multi-language support into your application is to do it in a way that doesn’t drastically increase development or maintenance costs. As database modeling is an inseparable part of the software development process, you need to think about the best data model design strategy to give your application multi-language support.
A proper data model should allow you to modify the application or add new functionality while maintaining multi-language support – without adding extra effort or cost. It should also allow you to incorporate new languages without touching the application; you only need to add the corresponding translation data to the database.
Simple Implementation vs. Flexibility and Functionality
There are different approaches to creating a database design for multi-language applications. Each has its advantages and disadvantages. Those that are easier to implement offer less flexibility and less functionality; those that offer more flexibility and functionality have more complex implementations.
My advice here is to always go for the ones that offer more functionality and flexibility, even if they are more expensive to implement. Sometimes we make the mistake of thinking that an application is too small, that it is not worth implementing complex schemas to solve things like multi-language support. But eventually, that application will grow and we’ll regret opting for the “quick and dirty” approach that seemed simpler and less expensive.
The ideal for implementing accessory functionality to an application – be it multi-language support, change logging, user authentication, or something else – is for that functionality to have its own subschema and its logic encapsulated in reusable components. This way, both the accessory functionality and its subschema can be incorporated into any new application with minimum effort.
An intelligent database design and data modeling tool like Vertabelo is a great help for the efficient management of your schemas and subschemas. Also, check out these tips for better database design and make sure you follow all of them. Before you start drawing your ER diagram, I suggest you consider this essential series of database modeling tips.
Some Appealing (But Unadvisable) Multi-Language Database Design Solutions
Easiest – But Least Recommended
Let’s start with the least recommended but easiest way to implement a multi-language application database. It allows you to quickly solve the need to support a multi-language application, but it will bring you problems when the application grows in functionality or in geographical coverage.
This simple strategy consists of adding an additional column for each column of text that needs translation and for each language into which the texts must be translated.
For example, in the Movies table below, there is an OriginalTitle field. An additional title column is added for each language to be translated:
| MovieId | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Die Hard | Duro de matar | Trappola di cristallo | Piege de cristal |
| 2 | Back to the Future | Volver al futuro | Ritorno al futuro | Retour vers le futur |
| 3 | Jurassic Park | Parque jurásico | Giurassico parco | Parc jurassique |
The application must obtain the description data from the column corresponding to the language selected by the user. When you need to add a new language, you must add an additional column to the table to contain the texts translated to the new language. You must also adapt the application to acknowledge the added language and columns.
This solution does not require complicated JOINs to obtain the translated texts, nor does it require duplicated records – only the replication of text content columns. But its applicability is limited to situations where only a few tables need to be translated.
For example, suppose you have a Products table and a Processes table. Each of them has a Description field that needs translation; seems easy enough, right? But if the entire application (including all of its menu options, error messages, etc.) needs to be multi-lingual, this solution is inapplicable.
More Versatile, But Also Not Advisable
Continuing with the idea of keeping translations within the same table, an alternative to the previous option is to enlarge the text fields. This would allow us to store all translations in the same field, organizing them in a data structure (e.g. an XML document or a JSON object). If you need to convert data from JSON to XML, use a special online platform. This can eventually make our work easier, quicker, and more efficient. Below we have an example:
|
MovieId |
OriginalTitle |
Translations |
|
1 |
Die Hard |
[ {"language": "sp", "title": "Duro de matar"}, {"language": "it", "title": "Trappola di cristallo"}, {"language": "fr", "title": "Piège de cristal"} ] |
|
2 |
Back to the Future |
[ {"language": "sp", "title": "Volver al futuro"}, {"language": "it", "title": "Ritorno al futuro"}, {"language": "fr", "title": "Retour vers le futur"} ] |
|
3 |
Jurassic Park |
[ {"language": "sp", "title": "Parque jurásico"}, {"language": "it", "title": "Giurassico parco"}, {"language": "fr", "title": "Parc jurassique"} ] |
This option does not require additional columns, but adds complexity. The data queries now must be able to correctly process and interpret the data structure used for multi-language support. For example, if JSON or XML is used to store translations, SQL queries must use an SQL version that supports the chosen data type.
The following SQL command uses the MS SQL Server OPENJSON() function to use the contents of the Translations field as a subordinated table:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Since there are no functions or operators to manipulate JSON or XML formatted data in standard SQL, you are forced to write your queries for a particular RDBMS if you want to use this technique to store translated texts. For instance, the previous query is not supported by MySQL. If you need to read the JSON data in the Movies table with MySQL, you’d write this query:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Storing Translated Text in Different Records
You can also choose to use different records for each language. However, you must resign yourself to losing normalization: the same data is repeated in several records, in which only the translation varies.
| MovieId | LanguageId | Title |
|---|---|---|
| 1 | en | Die Hard |
| 1 | sp | Duro de matar |
| 1 | it | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | en | Back to the Future |
| 2 | sp | Volver al futuro |
| 2 | it | Ritorno al futuro |
With this option, you could create views of each table that return only the rows in a given language:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Then, to query the table, you could use a different view according to the target translation language. But the normalization of the model is lost and table maintenance is unnecessarily complex.
Storing Translated Text in Separate Tables
One way to store the translated texts without breaking the relational model is to have a details table for each table containing texts to be translated. The subordinate table containing the translations must have the same key fields as the mother table, plus a field indicating the translation language.
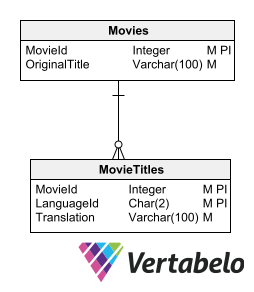
A subordinate table with translations must have the same key fields as the mother table, plus a field indicating the translation language.
This option allows incorporating new languages without altering the table structure. It does not require generating redundant information or breaking the model normalization.
The drawback for this option is that it requires the creation of a subordinate table for each table that stores textual data requiring translation. However, the idea of storing translations in related tables brings us closer to the most advisable way of designing a multi-language database.
The Universal Solution: A Translation subschema
For an application and its database to be truly multi-lingual, all texts should have a translation in each supported language – not just the text data in a particular table. This is achieved with a translation subschema where all data with textual content that can reach the user’s eyes is stored.
In web applications intended for use in different languages, a translation subschema is a necessity, not an option. Anything else will lead to complexities that will make proper maintenance of the application impossible.
The key of keeping translations in a separate schema is to maintain an indexed catalog with all texts that need translation, whether they are entity descriptions, error messages, or menu options. The idea is that no text that can reach the user’s eyes is stored in any table outside this subschema.
One way to organize the translation catalog is to use three tables:
- A master table of languages.
- A table of texts in the original language.
- A table of translated texts.
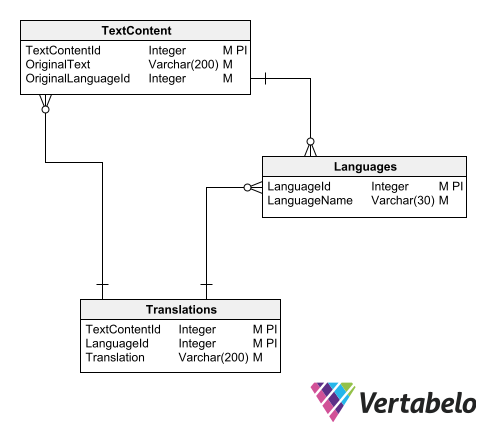
Schema for a universal translation catalog.
In the master table of languages, we simply insert a record for each language supported by the data model. Each one has an ID code and a name:
| LanguageId | LanguageName |
|---|---|
| en | English |
| sp | Spanish |
| it | Italian |
| fr | French |
The text table records all texts that require translation. Each record has an arbitrary ID, the original text, and the ID of the original language.
In the TextContent table, the original text and the ID of the original language are not strictly necessary. But they do simplify queries that do not require translation. For example, when doing statistical analysis or management control queries (which are usually only available to users who understand the original language) the queries can be simplified by using the default (non-translated) texts.
The orginal texts are also useful for those who have to fill the table of translated texts. Translation data entry can be done by means of a mini-application showing the original text and translations in all available languages. It is also possible to generate information for the translation subschema through an automatic process using a translation API.
Linking with the Main Schema
In the application’s main schema, columns with text values that need translating are replaced by IDs that point to the table of translated texts:
The main schema is linked to the translation schema through tables with texts that need translation.
You may leave the original text field in some of the main schema tables to facilitate queries where translation is not required, even though this generates redundant information. For example, we might keep the ProductDescription field in the Products table to facilitate statistical queries or to populate the dimensions of a data warehouse, leaving aside the translation subschema when it is not needed.
- Multi-Language Database Design: Do It Once and Do It Right
We have seen several alternatives for creating a multi-language database design. Some are easier and faster to implement. The last solution is a bit more complex, but it gives you much more flexibility. It will also save you trouble when the time comes to maintain the application and the database. Thus, in the long run, it will be much less expensive.
At times, the shortest path in database design tempts you into believing that you will save time and effort. But when you choose it, you’re overlooking the fact that you’ll probably have to go down it several times. If you ignore the best practices for multi-language database design, you will probably end up doing the same job over and over again.
