

When you were learning database concepts, data modeling looked pretty easy, didn’t it? You knew all the rules, and modeling seemed like a game: get a challenge, do your best, and eventually solve it. Job well done! Moving up to the next level – and so on.
As you continue, though, you’ll see that database modeling is also an art. Many cases require a totally new approach. Everything can be done ‘by the book’, but sometimes you get better results when you go less orthodox.
In this article, I’ll share my personal views on database modeling as well as some handy tips you can use to make a project run smoothly. I’ll summarize what I’ve learned working on ‘regular’ jobs and on freelance/consulting projects. Along the way, I’ve worked with an IT company, a bank, and an assortment of clients, from an attorney who needed a simple database for his personal use to a telecommunications company that needed a sales system with 300+ functionalities.
Do We Really Need to Develop a New Database?
This might sound silly, but ask this question as least twice, especially on smaller projects: Does a solution already exist?
In larger organizations, there is a good chance that your problem has already been solved; there are lots of data and people, so someone else may already have built a solution. It’s better to ask a few questions than to re-develop something that exists.
This re-inventing of the wheel is more prone to happening when people create ad-hoc solutions in Access or similar software. In a bank, things are usually done hastily; new solutions, it seems, are often needed almost instantly. Such situations do not allow you to properly document your work, so an existing solution could easily be forgotten.
Maybe you don’t have an in-house solution. Is there an existing product that you can use for free or at a reasonable price? Do some math. Is it more economical to buy your solution or develop one from scratch? There is wide range of free CRM software that covers most small- and medium-sized businesses’ requirements. It will take time to set it up and to train employees how to use it but it’s still more efficient than developing something similar.
Suppose you’re sure that your problem has not already been solved. The next reasonable question is this: Do you need a customized system, or can you use software like Excel or Access to do the job?
Regardless of the contempt that some IT people feel for them, Excel and Access are nice pieces of software that can solve many tasks when used properly. For a small company that doesn’t need a web app, Excel or Access could be the right solution. I used both of them extensively when I worked in a bank and later as a freelancer. They are the first things I think of when I need to develop small application without a lot of security requirements. You probably have these programs already installed, and they offer an easy way to solve simple tasks, like joining tables and creating queries. You can even use them to come up with GUIs and dashboards. However, they have their security issues and should not be used as replacements for web apps.
We Do Need a New Database. Now What?
Most of us fit into this category: the problem is too specific, and existing solutions don’t meet our clients’ or company’s needs. Some reasons for this might include:
- We want better security.
- We expect to make changes to the application, and our IT team can implement them much faster than a supplier can.
- In the long run, we’ll save money.
- There is market interest in this solution, and we could sell our version.
Now, let’s talk about the modelling process. The people who’ll use your application are collectively the most important factor here. Maybe you already have functional specifications, but you have to understand what users really need. Ask them, watch how they work, consider their suggestions. Maybe you’ll think of a new idea that can be of great benefit. (If you’re freelancing or consulting, this could lead to some extra money, too!)
If you’re working for somebody, they probably already have a solution and data to migrate. When they started their business, it was most likely small. A simple solution like Excel was enough. But as the business expanded, the existing software was not suitable for all the client’s needs.
From the business (or client) point of view, improving an existing solution is the most appealing option. If you’re certain that this would do more harm than good, sit down with your contact and give them the reasons why you’re so sure. Keep explanations simple and non-technical, and be sure that the client gets the point.
The two tables shown below represent two spreadsheets, where:
client_sheet– contains client detailssales_sheet– contains details about sales made
Looking at this example, we can offer the contact the following arguments in favor of customization:
- Security reasons; all employees have access to all the data.
- Redundancy and data integrity issues.
- Problems with multi-user access to files.
- Significant memory usage and increased network traffic, resulting in poor performance.
- Limitations to the number of rows in each sheet.
- There is no GUI, so it’s very hard to find needed data.
After everyone agrees to developing a new application, keep these things in mind:
- Think ahead when you need to ask questions. In my experience, your project contact is often unreachable because they are needed on other tasks. Your contact also delegates tasks to their subordinates, so you may be communicating with those people as well. Ask questions only when you can’t come to a conclusion on your own. Try to think of a solution before your question, present it to your contact(s), and ask how they feel about it. You’ll save a lot of time.
- Don’t forget about data migration. Explain to your contact what can be migrated and at what cost. Is detailed historical data really needed, or can you save it as a blob?
Before you start modelling, make sure you know the answers to these questions:
- How big is our team and who’s responsible for which aspect of this process?
- What database modeling software will we use? An online database modeling tool could be the right solution if you have a dispersed team with reliable Internet connections.
- Which database engine will we use? Often, any will do. The most popular open-source solutions are MySQL and PostgreSQL. If you don’t have any specific reason to use a specific engine, use the one you’re comfortable with.
Modeling – Step 1: Talk With Your Client Again
Before you really start modeling, sit down again with your contact. Explain your idea again. (Or explain it now if you haven’t already done so.) Ask questions. Let them know that if they want changes later in the process, it will very probably impact multiple parts of the design and will require more time. If your client wants some new features and asks “Can you do it?”, give them an honest answer. If it requires more time and therefore more money, don’t hesitate to say so. Play fair and you can expect that the other side will do the same.
Modeling – Step 2: Set Some Basic Rules
It’s always helpful to follow a routine, but this becomes even more important when you work in a team. If you provide your team with the rules to follow during modeling, everyone should understand the model quite quickly. Here are a few things your basic data modeling process should standardize:
- A naming convention: e.g. tables names are singular; table and attribute names are self-explanatory; use the same name for attributes in different tables if they have similar meanings (i.e.
start_timeandend_time). - Use one attribute in each table as a primary key; It should be of the int type with autoincrement set to yes.
- Include comments.
- Decide how extensively stored procedures will be used.
- Don’t blame yourself if you screw something up.
Modeling – Step 3: Start Modeling From Several Directions
Before you start modeling, you must define the most important entities. In our example, this will be the three tables used to store users, clients, and product data. We can also expect that these three tables will be the “core” tables in most (similar) models. Of course, depending on our situation we could have more or fewer core entities.
The user table contains a list of all registered users in our application. In the client table, we’ll store all our clients, and in the product table we’ll have a list of all the products (or services) we offer. Obviously, these tables are not related and we could look at them as a copy of the spreadsheets we mentioned before. The client table has serious limitations, particularly in the number of contacts we can store.
I love this approach because you can build the model from several directions. If you are uncertain about one direction, you can simply go in another. Maybe the solution will show up after your brain rests, maybe even as you sleep. (This has happened to me, and I guess I’m not the only one). You can see how your model grows, how tables relate together and how everything fits where it should. It also minimizes fear of the unknown (“I’ve done x so far, but who knows how big/confusing/problem-strewn the next part will be”).
Maybe the most valuable outcome from this is that both you and the client can come up with new ideas. If you develop from multiple directions, you’ll reduce the chance that new client requirements will surface later and change the whole model. Suppose it is decided that Product should be organized in a different manner – that shouldn’t impact the Client and User sections of the model.
Modeling – Step 4: Expanding Around Basic Tables
In this step, we’ll look at the requirements and expand the User, Client, and Product sections to fit project needs. When we complete this step, we should have fully-functional segments that we could easily reuse when designing future models.
So far, the user table contains only four basic attributes. However, our model didn’t implement user rights. Because of that, we need to add roles and statuses.
The user table presented in the previous model is replaced with this five-table section. While user_account contains user details, the other four tables expand the model with new options. Lists of possible values are stored in the role and status dictionaries; the actual values are stored in the user_has_role and user_has_status tables.
Following the same idea, let’s expand the client section. Two dictionaries, contact_type and person_type, will define all possible contact and person types that we want to relate with that client. The actual data is once again stored (via many-to-many relations) in the client_contact and related_person tables.
The product table gets four new attributes, and a table to record product price history is added to the model.
Modeling – Step 5: Bringing Everything Together
In this step, we’ll connect our segments and add purpose-specific tables. Since we’re modeling a database to store sales history, we’ll need to store contacts regarding clients and the resulting sales details.
Let’s say that the client wants to keep a history of their sales. We can also expect that they’ll make calls and arrange meetings. The model presented above has two new sections: Sales and Calls and Meetings.
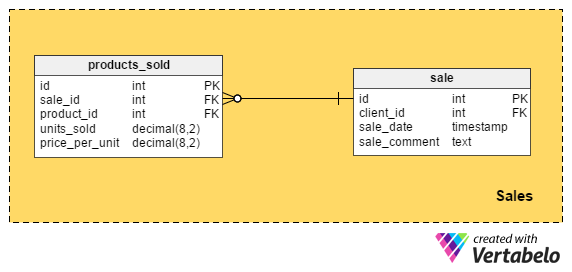
The Sales section has two tables:
sale– contains the time and description of the sale event.products_sold– contains a list of products sold in that sale event, the number of sold units, and the unit price when the sale was made.
This section directly relates products with clients.
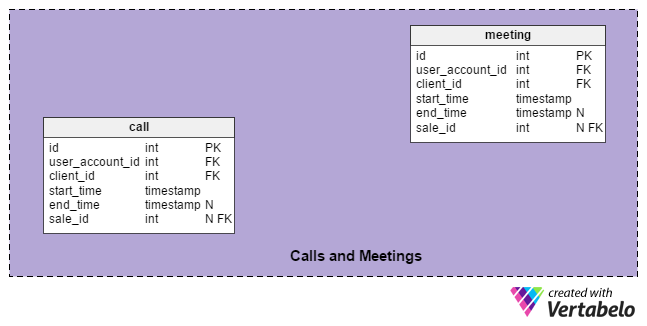
In the final section of our model, we’ve added the call and meeting tables. They relate all of our three main sections: the User, Roles, Statuses section via the user_account_id attribute; the Clients section via the client_id attribute; and the Products section indirectly via the sale_id attribute.
Modeling – Step 6: Unique Values, Indexes and Redundancy
You should always define unique values where you expect them. If you haven’t done this yet, do it now. In our model, all role, status, and product names should be unique values.
If you can tell that some actions will significantly affect database performance (i.e. bottlenecking) add:
- Indexes where you need them.
- Redundancy. This can be very helpful when you want to speed up reporting from the live system; read more about it in this article.
It may seem easy to design a database. Still, take some time before you start modeling – especially on larger projects. Be sure that you clearly understand clients’ needs; choose the appropriate modeling tool and the DMBS.
Data modeling is an iterative process, so expect to make changes pretty often. My personal advice is to start from a few different perspectives, encircle the problem, and slowly tighten your grip until all the relevant data is in the model. Test it at the end of each iteration until it passes all the tests.
