

In this article, we will see how to use Vertabelo to create a Snowflake DDL script. We’ll start from a data model created online and walk you through the process of generating the SQL script that will create the physical database.
Vertabelo is a powerful yet easy-to-use data modeling tool that can help you create database models for many database engines, including Snowflake.
What Is Snowflake?
Snowflake is a Cloud-based Database-as-a-Service designed by former Oracle engineers. It can be executed on leading Cloud providers, including Microsoft Azure, Google Cloud, and Amazon Web Services. This is one of the key benefits of Snowflake, since it provides the flexibility to change to another Cloud provider. This mitigates the risk of being locked into one Cloud vendor.
Snowflake is mostly used for data warehouse and data lake implementations. This is because it facilitates the storage of structured, semi-structured and unstructured data that can be accessed using ODBC, JDBC, or native connectors.
Creating a Snowflake Physical Data Model with Vertabelo
We’ll create a very simple Snowflake database model using the Vertabelo data modeler; then we’ll explore the different ways to get a Snowflake DDL for all (or some) of the tables. You can read Data Modeling Basics in 10 Minutes if you do not have experience using Vertabelo. The article What Are Document Types in Vertabelo? explains the different types of models available.
When creating the model, we need to name it, select the database engine (Snowflake), and then press the Start Modeling button:
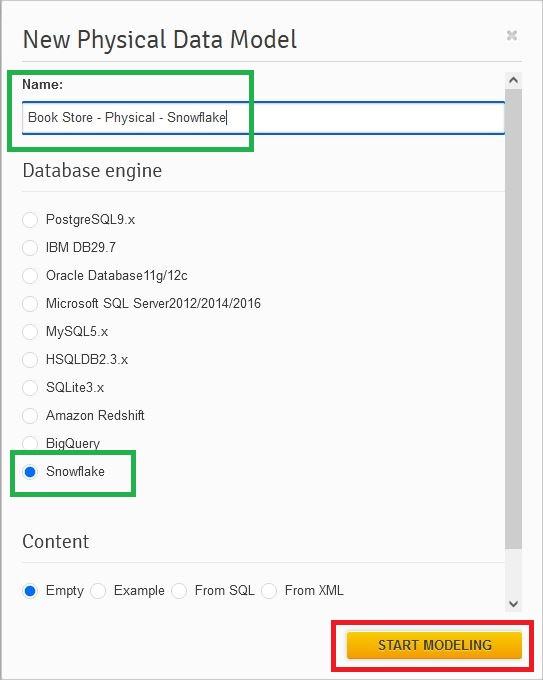
Now we have an empty Snowflake physical data model and we can start designing our database.
Adding Tables
The first step when creating any data model is to add the desired tables. We can do this by clicking on the third icon of the diagram taskbar![]() and then clicking on any empty space in the diagram.
and then clicking on any empty space in the diagram.
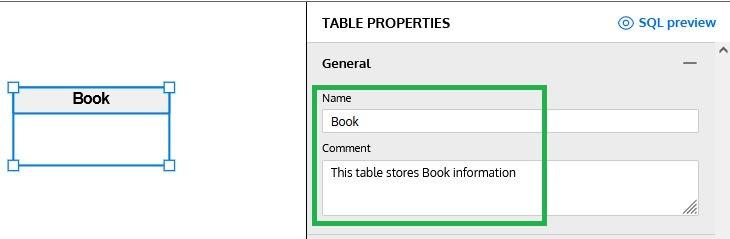
Once we have generated the first table, the Table Properties panel will appear on the right side of the Snowflake diagram. We will use the different sections of this panel to define all details, starting by providing a name and description for the table:
Adding Columns
Below the General section of the Table Properties panel, the Columns section allows us to define columns. After clicking on the Add Column button (identified in red in the following image), we must define the column’s name and datatype, whether the column allows NULL values (using the N checkbox) and whether it’s part of that table’s primary key (using the P checkbox):
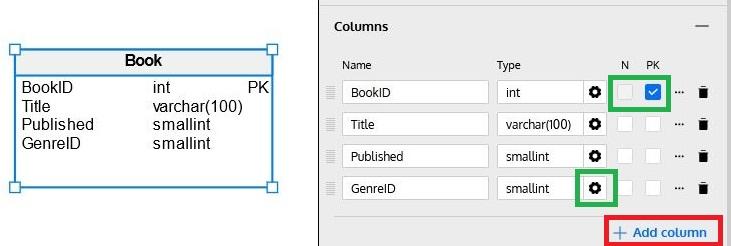
Datatypes
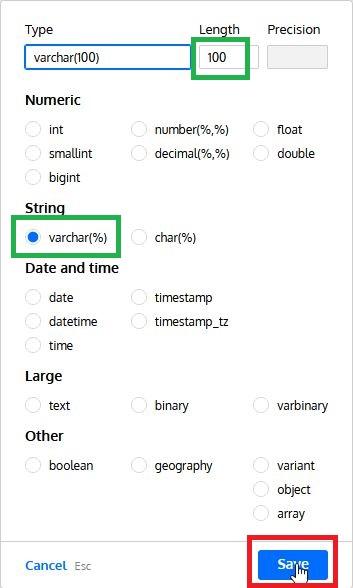
The datatype wizard simplifies the selection of datatypes, showing the ones available in each database engine and allowing us to define length and precision (when required). The image below shows all datatypes available for Snowflake:
Additional Column Properties
Besides a column’s name, datatype and nullability, and primary key status, there are other options available that define additional characteristics and behaviors. By clicking on the … icon (marked in red below) on each column row, we can set additional column properties:
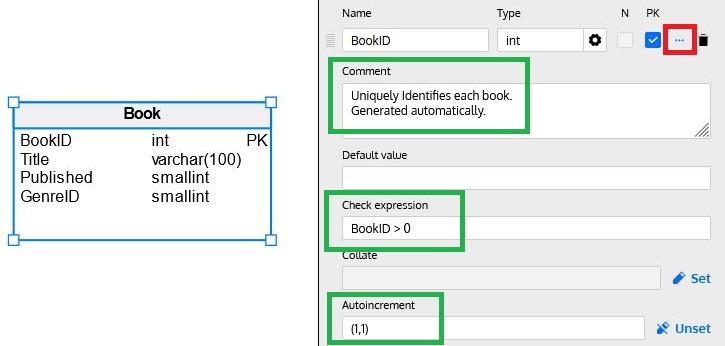
These properties vary from one database engine to another, so we are just going to mention those applicable to Snowflake:
- Description: Describes the column contents and/or purpose.
- Default Value: Provides a default value when a new row is inserted but the column is omitted in the INSERT
- Note: Default Value and Autoincrement (see below) are mutually exclusive.
- Check Expression: This property allows us to define an expression to be checked whenever a row is inserted or updated.
- Note: Check Expressions are currently ignored during SQL Preview and SQL Script generation.
- Collate: Defines the collation to be used.
- Note: Collate is supported only for string datatypes.
- Autoincrement: Also known as Identity, this feature allows a number to be automatically assigned at insert time for each row. You need to enable the feature (by clicking Set) and define an initial value and an increment (enclosing both values in parentheses); the database engine will automatically generate values each time a row is inserted, using an internal sequence to obtain the values.
- Note: If you do not provide initial and increment values, the default of 1 is used for both.
- Note: Autoincrement and Default are mutually exclusive.
- Note: Autoincrement is supported only for numeric datatypes.
Primary Key & Unique Key
Snowflake supports primary and unique keys. The next two sections of the Table Properties panel allow us to create a primary key (if no column was selected as a primary key in the Columns section), name it, and define one or more additional unique keys.
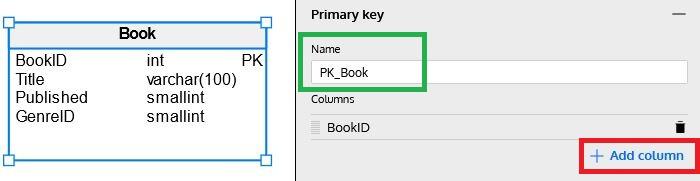
Note: Both primary and unique keys can be defined using multiple columns via the Add column button. Columns can be arranged using the icon to the left of each column name.
Additional Properties
This section includes options specific to each database engine, like logical grouping, loading/unloading data, and other characteristics. Snowflake models in Vertabelo include the following properties:
Schema
If your data model is complex, separating tables into smaller groups may be a good way to organize tables in the model. Schemas are a logical way to organize database objects (not only tables) based on functionality or another classification. A schema represents a group of related objects.
Transient
Transient tables in Snowflake are similar to regular tables, but the information does not have the same level of protection. Data stored in a transient table may be lost in case of a system failure, so this should be used only for tables that can be recreated (either externally or by querying non-transient tables).
Cluster By
Clustering is a feature designed for very large tables (tables with a size measured in terabytes). It allows Snowflake to store data that shares the same clustering key together, thus reducing resources used to access data when filtering by columns included in the cluster key.
Note: Designing an optimal clustering key is not a trivial task; read the Clustering Keys & Clustered Tables article in the Snowflake documentation for more details.
Stage File Format
This option specifies the default format used to load/unload data into/from the table. It can be a user-defined format. (See the syntax for CREATE FILE FORMAT in the Snowflake documentation.) Or it can be one of Snowflake’s included formats – CSV, JSON, AVRO, ORC, PARQUET, and XML. Each format has many options, like specifying a compression algorithm or defining a default file extension. Please read the Format Type Options section of the Snowflake documentation for more details.
Stage Copy Options
Copy options allow us to define how data is loaded or unloaded to Snowflake for each table. The most popular options are:
- ON_ERROR: Define what to do when an error is encountered while loading data.
- SIZE_LIMIT: Define when to stop loading data from new files, i.e. once the size limit has been reached.
- PURGE: Defines whether files containing data are automatically removed from the staging area once the file is successfully loaded into Snowflake.
There are several additional options; you can learn about them on the Copy Options section of Snowflake documentation.
Data Retention
Defines the number of days data is kept in order to perform Time Travel actions like SELECT, CLONE and UNDROP. Those actions can be done on a historical version of the table data, as explained in Understanding & Using Time Travel.
Max Data Extension
This option defines the number of days (in addition to data retention) that Snowflake can extend the data retention period to avoid streams becoming stale.
Change Tracking
This option enables change tracking by adding two hidden columns (used to store metadata) to the source table. This option allows the CHANGES clause of the SELECT sentence to be used to query change-tracking metadata.
Default Collation
This option defines a default collation for all string columns (either existing ones or ones added later).
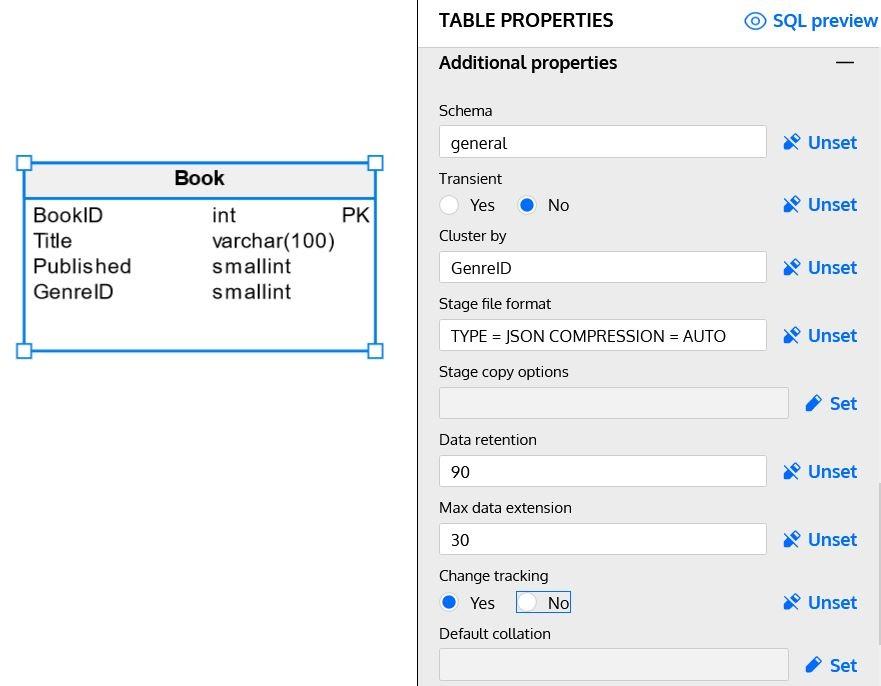
The following image show some of these properties implemented in our Book table:
Now that we have reviewed the Snowflake data model’s main options, we can continue adding a few more tables to complete our model:
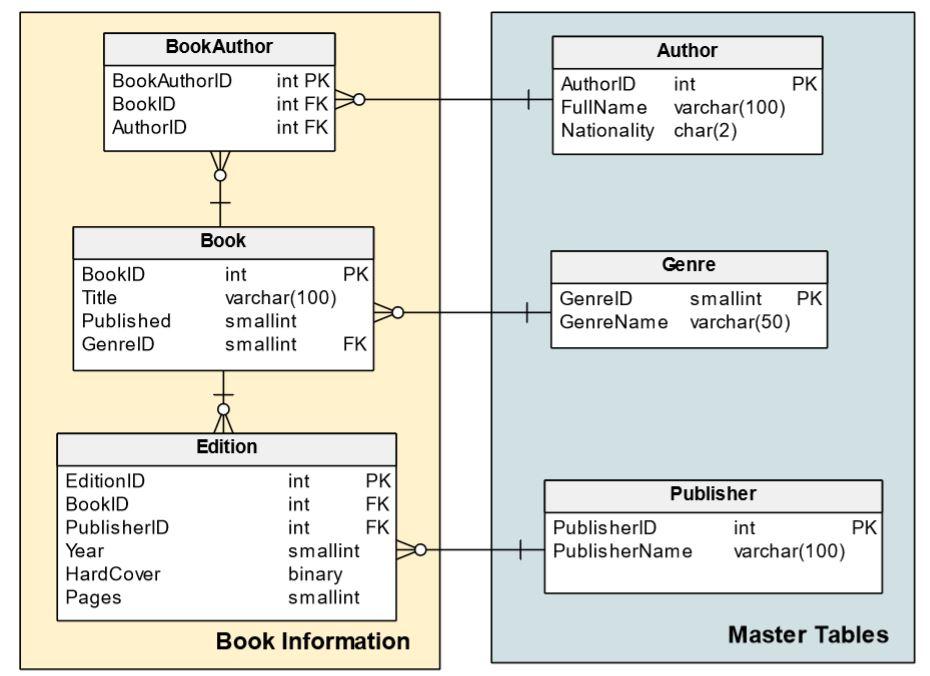
Adding Additional Objects
Currently, Vertabelo does not support all Snowflake object types; you may need to add some additional objects by adding the script directly to the model. Let’s see an example of how easy it is to do this.
In the Stage File Format section of this article, we mentioned that Snowflake allows us to define our own file formats. We can use the Additional SQL scripts section in the Model Properties panel to include a script that creates the file format:
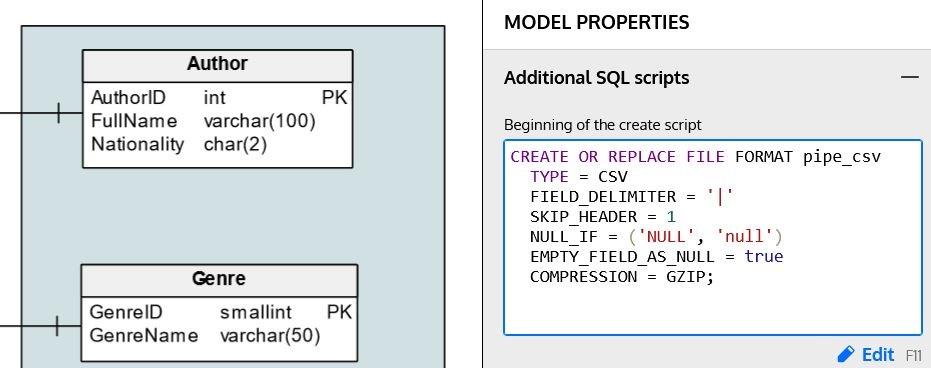
Once we’ve defined it, we can use this format in the Stage File Format property of any table in our model:
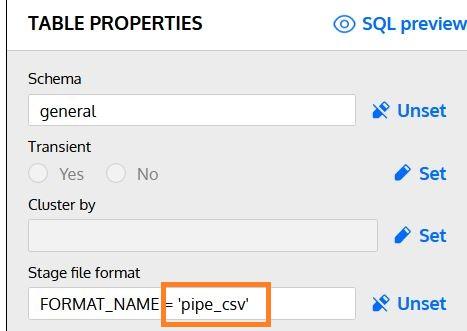
How to Get a Snowflake DDL for All Tables
Vertabelo has a feature that easily and automatically generates a Snowflake DDL script to implement our entire model. The first step is to select Generate SQL Script in the top menu:
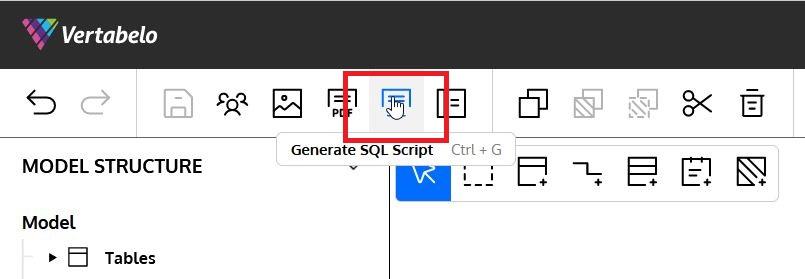
A popup lets us select what types of objects to include in the script. (You can also enable the Only selected elements checkbox to create the script only for elements currently selected). We then click Generate:
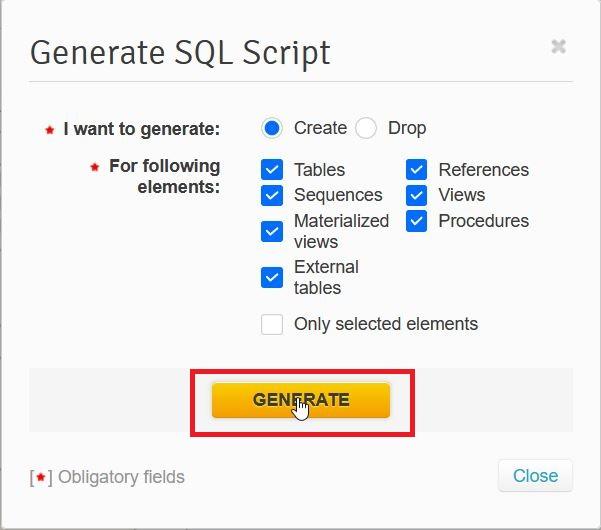
In a few seconds, the script is generated. You can download it or store it in your Vertabelo drive for later use:
You can read the article How to Generate a SQL Script in Vertabelo to get more details on the process of creating your model scripts. The article Vertabelo’s Document Structure: How Documents and Models Are Organized will help you learn about Vertabelo’s drive structure.
And that’s it! You’ve successfully designed a data model for a Snowflake database and created the DDL file that will bring your data model to life!
