

Every software developer should know how to design a basic data solution to store application data. In this article, we’ll take you step by step through the basics of data modeling.
By the end of the article, you‘ll understand the main phases of database modeling and the types of questions you need to ask when designing a data solution. This introduction to data modeling basics will hopefully spark your curiosity and show you that database modeling is an exciting challenge.
What Is Data Modeling?
Data modeling is a process in which a software developer or a database modeler builds a diagram representing the data model that will be used to support a software application. It is a challenging but exciting process that describes how data will be stored and how database tables will relate to each other through relationships. To support and represent the real side of the business, data constraints can also be implemented.
All of the details we mentioned so far are included in a document called the entity-relationship diagram. This is the first thing to know about data modeling.
What Is an Entity-Relationship Diagram?
The entity-relationship diagram visually shows the way logical entities, objects, or concepts from the real world interact with each other. For example, an entity-relationship diagram (also called an ERD or ER diagram) can represent the way customers interact with a business and its products; this interaction then influences sales, revenue, and employee bonuses.
To have a complete data model, you must represent all of the interactions and relationships between related entities in the ERD. Although thinking of all the possibilities might seem difficult, there are tips you can use to tackle this.
Knowing what an ERD is and when it is used is also an essential part of data modeling basics.
Steps of Database Modeling
Building a complete database model is an incremental process that starts with discussing the business requirements. There are a series of checkpoints through which a data model passes until creating the final model, from which the database is built.
Let’s briefly go through the steps of database modeling and the phases of the data model. If you want a more in-depth analysis, read this article on conceptual, logical, and physical data models, after finishing this one.
Conceptual Data Model
The first step in the evolution of a data model is to build the conceptual data model. When building the conceptual data model, we focus on defining our business’s main entities. This means communicating with the main stakeholders.
The purpose of the conceptual model is to define the scope of the solution. It also serves as a common ground for communicating and defining the business requirements, concepts, and rules. The output is a diagram with all of the main entities and their relationships.
Note: Vertabelo doesn’t have a conceptual data model document type; that’s because the line between conceptual and logical data models isn’t clearly defined. To create a conceptual data model in Vertabelo, use the logical data model document and simply omit the attributes from the entities.
Logical Data Model
After we’ve defined the conceptual model, we add details to create the logical data model. You might say that the logical model is a conceptual model to which data normalization techniques have been applied and for which all of the attributes have been identified. In this model, we make sure to select the primary identifier for each database table and create the appropriate relationships between tables.
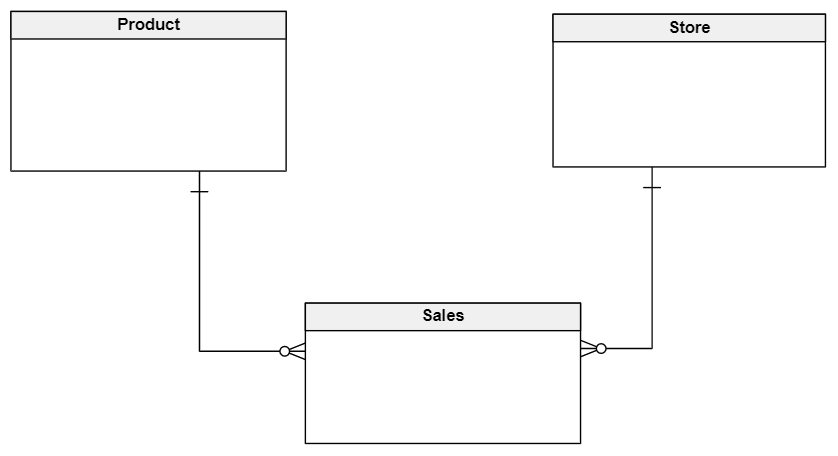
Below, there is an example of a logical data model for a store. It represents the basic elements of any store (products, sales and the store itself) and their relationships. Note that certain attributes are marked PI, which means they are the primary identifier for that entity. Watch what happens to these elements as we move into the physical model.
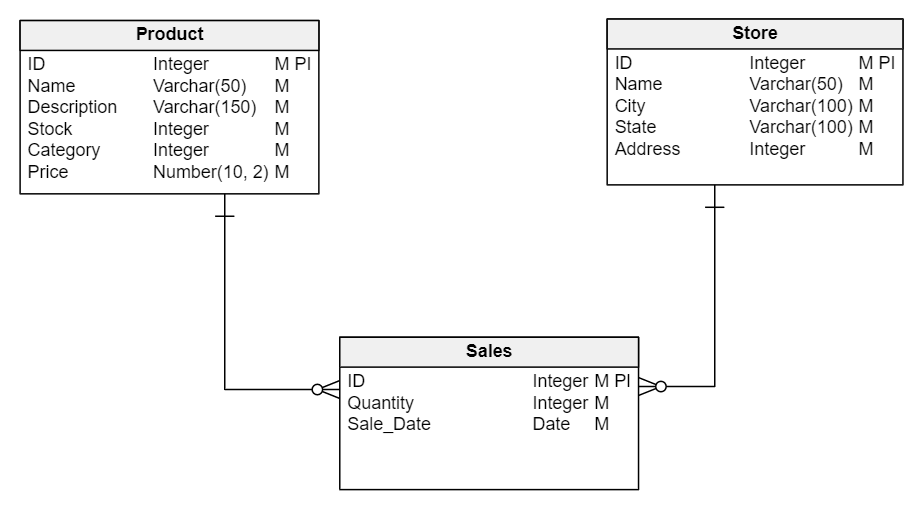
Physical Data Model
After the conceptual model is built, we need to create the physical data model. This is the final phase of the data model. All of the entities are transformed into tables and the attributes (i.e. columns) are associated with specific data types according to the target database engine. Essentially, once we have completed the physical data model, we can write or generate the database code.
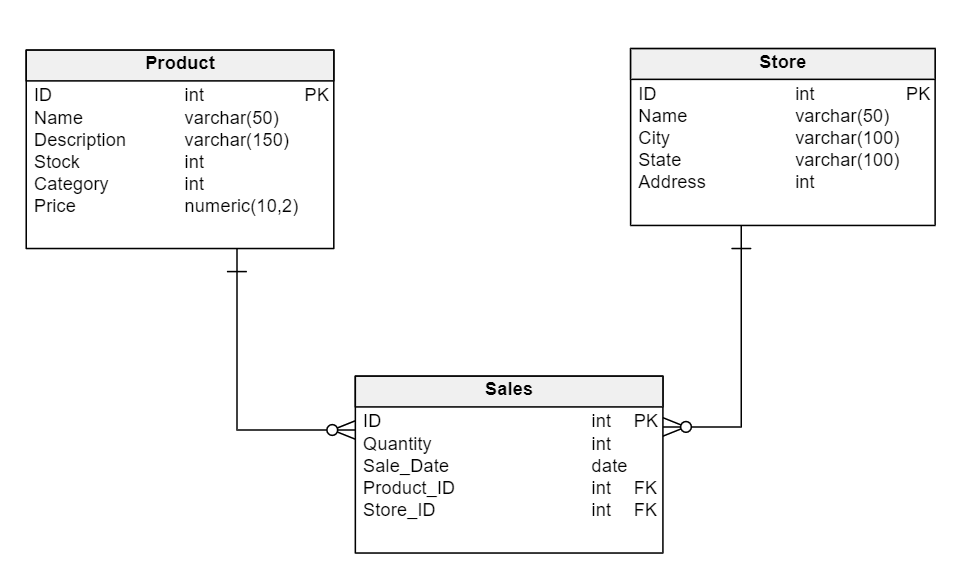
Differences Between Logical and Physical Data Models
The differences that occur between the physical and logical data model are generally determined by the target database engine. The same logical data model can be used if your target database is PostgreSQL, SQL Server, Oracle, MySQL, etc.
The specifics of each target database will determine the data types we choose, the types of indexes we create, if columns are nullable, the structure of tables, if we use partitions, etc.
The physical data model clearly defines the technical details that are needed to implement the database through code.
Basics of Creating a Database Table
All databases use the same main building block for storing data: a table. A table is the organized data structure that stores data about one object – in this case, stores, products, or sales. Each row in the table represents one sale, product, etc.
Data stored in a table is separated both logically and physically from data in a different table. If you’re using Vertabelo to design tables, you’ll need to create an entity before you create a table. This is done by adding a new entity to our logical data model, as shown below. If you still need help, here’s a quick tutorial on adding a table to an ERD.
After creating an entity in the logical data model, you need to add its attributes. Just selecting the entity will open up a list of Attributes on the right-side panel, where you can add attributes, input the name of the attribute, and select the kind of data that it will store.
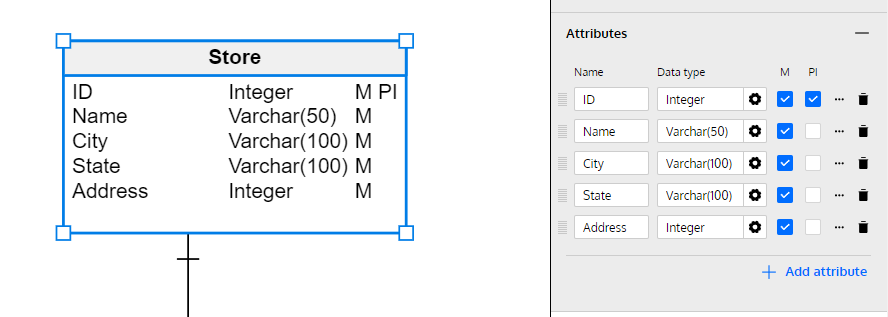
When you’ve finished setting up all of these attributes and the relationships between entities, it’s time to get into the physical data model. If you’re using Vertabelo, you’re in luck – you can easily auto-generate the physical data model for almost any database engine. To find out more about how to do this, have a quick look at our tutorial.
Once you have the physical data model as a separate file in Vertabelo, you’ll see a very similar structure to the logical data model. However, at this step, the target data types for the attributes (now columns) are defined. You also can set which columns are nullable, meaning they can store NULL values instead of real data when that specific information is not available.
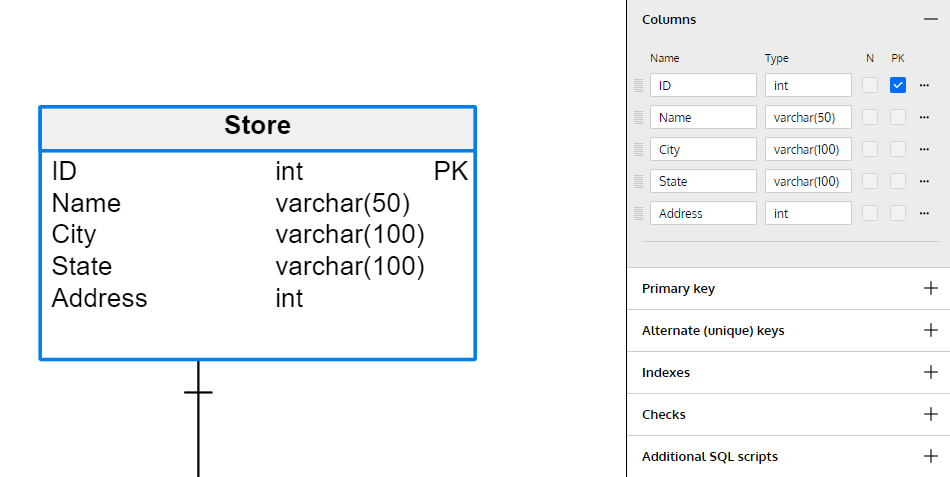
During this step, you can define other characteristics specific to the table, such as indexes, checks, and constraints. They’re all in this right-side panel. If you haven’t defined the entity’s primary identifier in the logical data model, make sure to set a primary key for the table.
How to Represent Entity Relationships
Real-life entities interact with each other; we need to represent this interaction as a relationship between database tables. This relationship is logically determined by a link between a primary key and a foreign key.
What Is a Primary Key?
A primary key (PK) is a column (or combination of columns) whose values (or combination of values) allow you to uniquely identify a row in a table. For example, a store ID (the unique business ID for a store), is a great primary key value for a Store table. For a vehicle, the VIN (vehicle identification number) is a great candidate for a PK. To learn more, we recommend this deep dive into primary keys.
What Is a Foreign Key?
Because some objects interact with each other, like a Store and its Sales, we need to represent the fact that a store has sales. This is done by showing a relationship between two entities; the endpoints of a relationship are made of a primary key linked to a foreign key.
A foreign key (FK) is the value of another table’s primary key stored in a different table. For example, the primary key value of a Store (its ID column) can also be placed in the StoreID column of the Sales table. This allows us to look up the sales of a specific store by searching through the Sales table for the ID of that store.
In Vertabelo, primary and foreign keys are created automatically from the relationships defined in the logical data model. Once you generate the physical model from the logical model, the primary identifiers are replicated from the primary table(s) to the foreign table(s), automatically creating foreign keys. The primary identifiers also automatically become primary keys for their tables.
Manually Creating Primary and Foreign Keys
If you haven’t specified primary identifiers in your logical data model, you’ll need to create primary and foreign keys manually. To create a primary key, select the relevant table and check the boxes for the column(s) that you want to be part of the PK:
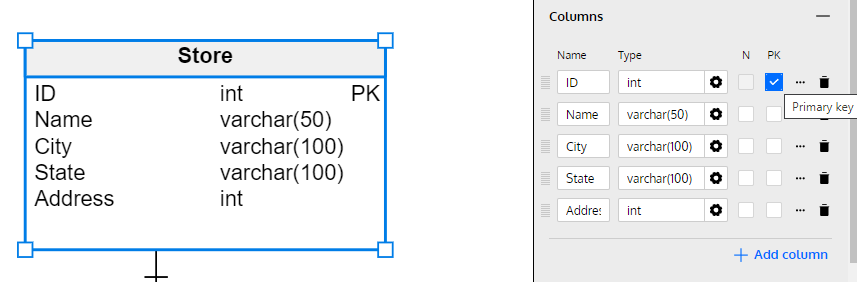
The process is a little bit more complicated for adding foreign keys. Since a foreign key requires a column with values matching another table’s PK values, we need to add this new column by hand. Let’s use the relationship between Store and Sales as an example.
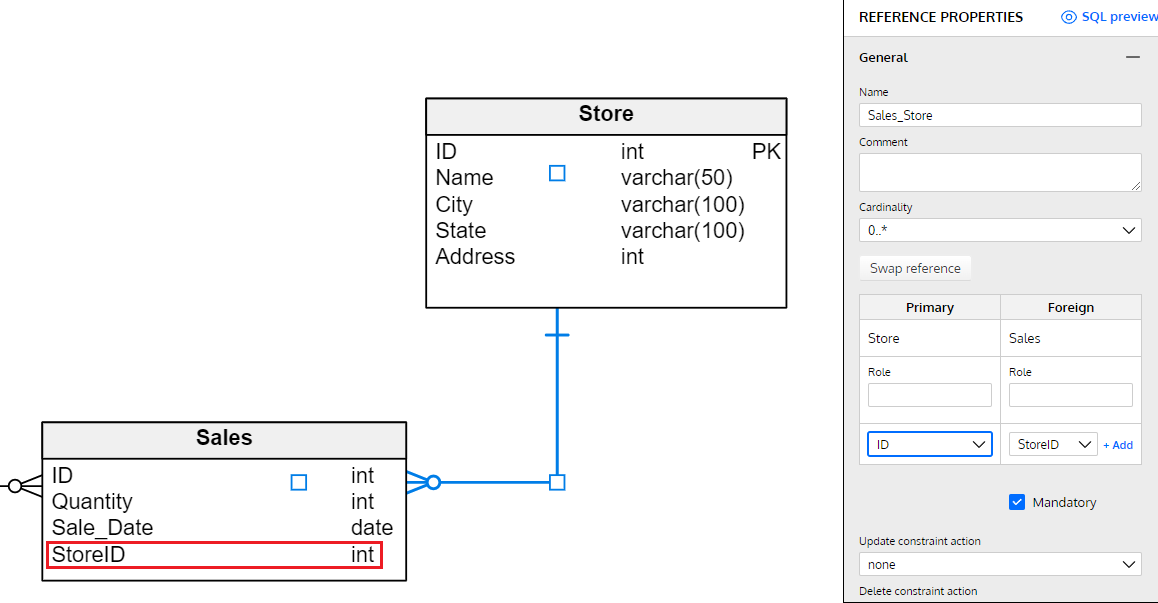
First, we create a new column called StoreID in the Sales table, following the method shown previously. Then, we click the relationship link between the two tables and define the cardinality between these tables. Finally, we set the linking columns (ID in Store and StoreID in Sales). And voila – we have our foreign key.
Expanding the Power of Your Database
Now that we have relationships defined in our physical model, we should consider adding indexes (to improve performance) and CHECK constraints to enforce business rules. Learning about indexes and constraints will help you complete your knowledge on data modeling basics.
For example, it would be a great idea to add an index on the newly created StoreID column in the Sales table. We’ll most likely have to join the Store and Sales tables together in our queries, so adding an index on StoreID will improve query performance. This can be done by selecting the Sales table and defining the indexes through the interface on the right-side panel.
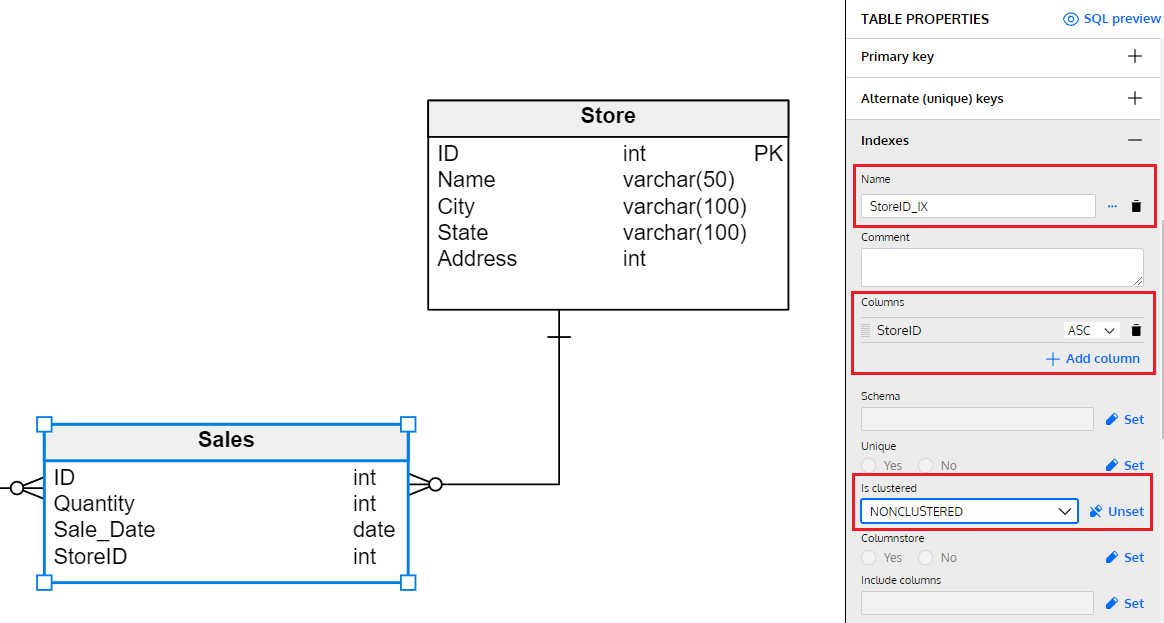
In this case, the most important things to set are the index name, the columns it’s created on, and the type of index (which, for this situation, is nonclustered). If we were to create this index from a SQL statement, it would be something like this:
CREATE NONCLUSTERED INDEX StoreID_IX ON Sales (StoreID ASC)
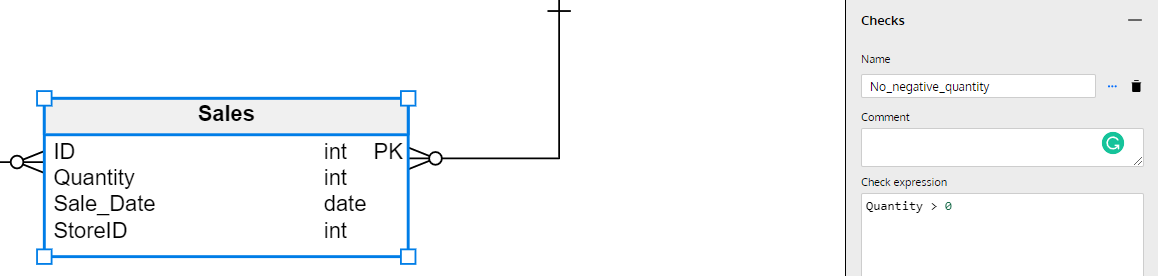
A great complement to adding an index would be to add a constraint on the Quantity column. To keep business consistency in our data, we can add a CHECK constraint on this column so that we can’t input negative or zero quantities. This reduces the input of incorrect data into our table and avoids other possible issues that can come up in our application due to storing incorrect data.
This can be done from the same right-side panel, where we input the definition of our CHECK constraint, like below.
Extend Your Data Modeling Basics
We’ve only taken 10 minutes, but you’ve already covered most of the data modeling basics. Don’t stop here – continue looking over more tips on how to design and improve your data modeling skills. Continuous learning is the key to success in any endeavor, so we recommend you keep learning about data modeling. There’s so much to discover!
