

All rows in a database need to have a unique identifier. But what if you need to have unique identifiers for all of the rows in all of your tables? We know GUIDs are problematic when indexing, so what other options are there? A database sequence might be a great option.
What Is a Database Sequence?
A database sequence is a type of object created in a database that allows developers to generate unique values. It essentially works like a number generator, but in sequence. Every time you request a number from a database sequence, it will return a unique number.
A database sequence does not necessarily generate consecutive numbers. You can configure it to generate numbers in increments of “n.” You define “n” when creating the sequence.
A database sequence is not tied to any table in particular and is different from the way an IDENTITY column or AUTO-INCREMENT column works.
For example, if you have a transaction with multiple queries and one query fails, then the transaction is rolled back. However, if, in the transaction, you received a number from the sequence, that will not be rolled back. The number returned from the sequence will no longer be returned at the next sequence call.
Which Databases Support Database Sequences?
Although a database sequence is a niche feature, almost all modern databases offer support for creating a database sequence. You can create a database sequence using any of these databases:
- Microsoft SQL Server
- Oracle
- PostgreSQL
- MariaDB (based on MySQL)
- IBM DB2
When Should You Use a Database Sequence?
The general purpose of a database sequence is to generate numbers that are unique within a database. Most often, database sequences are used for creating surrogate keys, which are artificial primary keys.
Surrogate keys are values that allow you to uniquely identify a row in a database. Typically, a surrogate key is populated by a sequence when the available primary key candidates are too wide (composite keys).
We offer more detailed information in our article about why surrogate keys might be a good choice.
A real-world use case for a database sequence is when using an IDENTITY column or an AUTO-INCREMENT column is insufficient. However, there are other situations in which a database sequence is a good option. Below, I’ll explain a situation when a database sequence was the best and only solution.
Real World Use Case
I once worked on a project in which the business was receiving Excel files with payment data. The Payments team had to manually review and accept payments.
The Excel files were received via e-mail and had to be uploaded to our application. Each of the files had a few thousand rows of payments. The interface was an upload button and simple preview table that allowed users to preview the data in the webpage before sending it to the SQL Server database.
The team was always eager to upload the files to the database as quickly as possible. Afterward, they could proceed with manually processing the payment records, the most important part.
The team always received the files on the second to last day of the month and had to manually process the payments by the end of the month. So, on the last two days of the month, our system experienced the highest concurrency.
The users needed to be able to review the contents of any files they previously received. So, we decided to create the concept of a “batch file” for an Excel file. This was an easy way for users to later review any files and refer to them by their batch ID.
Essentially, all of the rows read from an Excel file would be associated with a batch ID. So, we created a table with the columns of data from the Excel file and two new columns: a unique row identifier and the batch ID column.
We used a surrogate primary key column so that we could uniquely identify the payment records. The batch ID column allowed us to refer to the Excel file that was uploaded.
We started implementing our application logic in the backend of our application. We always looked up the max value in the batch ID column to see which batch ID was most recently inserted. We incremented that value by one and sent the thousands of rows back to the database.
Everything seemed to work fine until we realized we had some problems. We had high user concurrency and latency when we queried the database for the max batch ID for each user session. This was mainly because each user had around 10,000 rows in their files.
Each file upload action triggered from the web interface queried the database for the max batch ID. After the max batch ID was returned, it was incremented by one and assigned to the new batch. Then, the data was saved in the database table with its associated batch ID.
Because of latency in inserting the data in the table and high concurrency, two distinct Excel files received the same batch ID. This caused quite a big problem because our files were essentially merged. So, we didn’t know which records came from which file.
This is the point where I can honestly say that the database sequence feature saved us.
Overnight, when the Payments team was off work and no records were being added to the table, we quickly implemented a database sequence. We calculated the max batch ID from our table, plus one, and set it as the starting number for our database sequence. We set the increment of the sequence to one and deployed it to the database.
We not only solved the problem of getting merged batches of payment records but also improved performance. This was because we no longer had to scan for the max value. Even if the column was indexed, we still avoided scanning the index.
In the end, we only had to request a single number from the database sequence. We always knew it was unique for every user, for every session, and for every call.
The code we deployed for creating the database sequence was also quite simple:
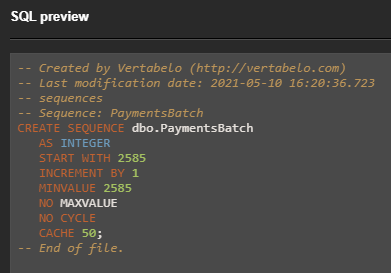
CREATE SEQUENCE dbo.PaymentsBatch AS INTEGER START WITH 2585 INCREMENT BY 1 CACHE 50;
And requesting a new number for the database sequence was even simpler:
SELECT NEXT VALUE FOR dbo.PaymentsBatch;
This small feature saved us all of a lot of headaches, especially when we needed it the most.
Database Sequence Options
When creating a database sequence, you have a couple of arguments to choose from. These arguments will configure your database sequence to work differently. Below, we will focus on the arguments available for SQL Server database sequences. Other databases might have slightly different names or arguments available.
- START WITH - This argument defines the first value returned by the database sequence. If you have a MINVALUE or MAXVALUE defined for the sequence, this number must be within that range.
- INCREMENT BY - This argument is the increment by which your sequence will either increase or decrease. You can have descending sequences by specifying a negative increment.
- MINVALUE - This argument specifies the lower limit of the database sequence.
- MAXVALUE - This argument specifies the upper limit of the database sequence.
- CYCLE/NO CYCLE - This argument specifies if the sequence should or should not restart counting from the minimum value (or maximum value for descending sequences). The default value for this option is NO CYCLE.
- CACHE/NO CACHE - This argument will help increase the performance of your database sequence. It does so by reducing the number of disk IO operations required to read a new number from the sequence. If CACHE is specified, along with a number, then the database sequence stores in memory only the current value of the sequence and the numbers left in the cache.
Adding a Database Sequence in Your Vertabelo Database Model
It’s always important to keep your database model up to date with each change you make to your objects. Fortunately, Vertabelo allows you to define your database sequences so that you never accidentally miss documenting them.
To add a database sequence, you must first go to your physical data model project file. In the “Model Structure” menu on the left-hand side, you will have an option called “Sequences.” Right-click on “Sequences,” and select “Add sequence.”
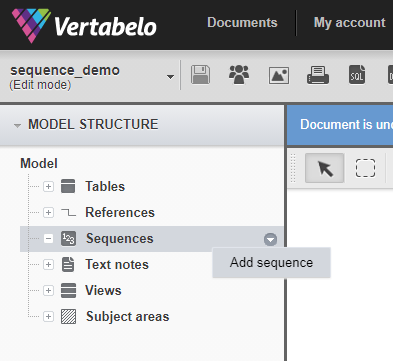
After selecting “Add sequence,” a new item will appear nested under this menu, and a new panel will open up on the right-hand side of our model view. Note that the database sequence only shows up in the left-hand-side menu and does not in the diagram.
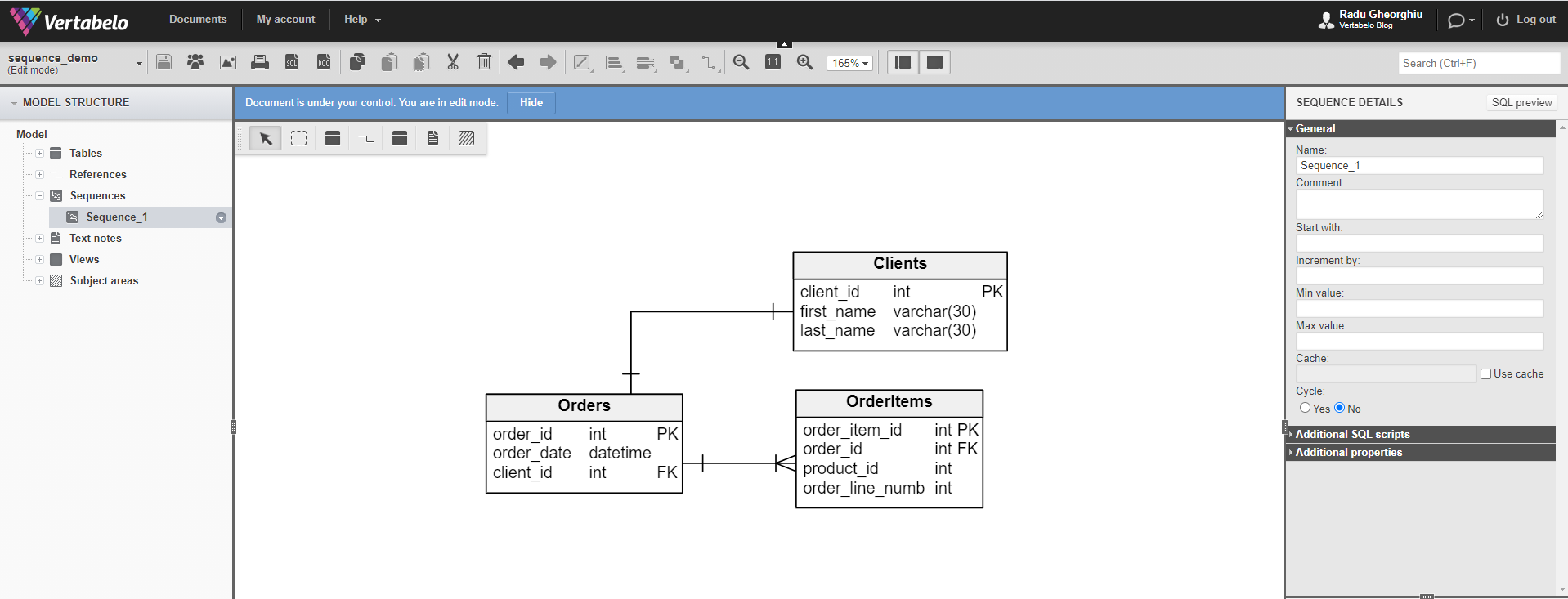
If the right-hand-side panel doesn’t show up, make sure you have selected your “Sequence_1” sub-item from the “Sequences” menu. We’re now going to focus on the right-hand-side panel.
If I were to set up the database sequence I used to solve the problem I previously mentioned in Vertabelo, I would do this:
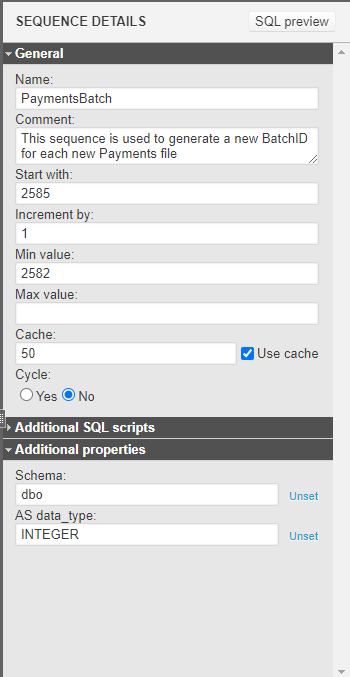
You can easily set up all of the database sequence arguments in this panel. At the top of the panel, you can set up the name of the sequence. This will automatically update the name of the sequence in the left-hand-side menu.

You can easily add all of the arguments of the database sequence that I manually created. If you expand the middle of the right-hand-side panel, you will see that you can add additional SQL scripts that you might need to run before and after creating your sequence.
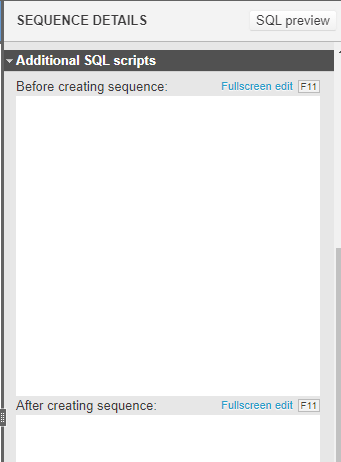
At the bottom of the right-hand-side panel, you can also set the schema on which the sequence is to be created as well as the numeric datatype the sequence will have.
Once the definition is set up for our database sequence, at the top-right of the “Sequence Details” panel, there is a “SQL Preview” button. If we press it, we instantly get access to the entire T-SQL code needed to create this database sequence.
Keep Learning About Databases!
Did you enjoy this article? We hope you found the information useful and now know about some good use cases for database sequences. We invite you to browse our blog and learn more about database features that can expand your applications.
