

You may think database maintenance is none of your business. But if you design your models proactively, you get databases that make life easier for those who have to maintain them.
A good database design requires proactivity, a well-regarded quality in any work environment. In case you are unfamiliar with the term, proactivity is the ability to anticipate problems and have solutions ready when problems occur – or better yet, plan and act so that problems don’t occur in the first place.
Employers understand the proactivity of their employees or contractors equals cost savings. That’s why they value it and why they encourage people to practice it.
In your role as a data modeler, the best way to demonstrate proactivity is to design models that anticipate and avoid problems that routinely plague database maintenance. Or, at least, that substantially simplify the solution to those problems.
Even if you are not responsible for database maintenance, modeling for easy database maintenance reaps many benefits. For example, it keeps you from being called at any time to solve data emergencies that take away valuable time you could be spending on the design or modeling tasks you enjoy so much!
Making Life Easier for the IT Guys
When designing our databases, we need to think beyond the delivery of a DER and the generation of update scripts. Once a database goes into production, maintenance engineers have to deal with all sorts of potential problems, and part of our task as database modelers is to minimize the chances that those problems occur.
Let’s start by looking at what it means to create a good database design and how that activity relates to regular database maintenance tasks.
What Is Data Modeling?
Data modeling is the task of creating an abstract, usually graphical, representation of an information repository. The goal of data modeling is to expose the attributes of, and the relationships between, the entities whose data is stored in the repository.
Data models are built around the needs of a business problem. Rules and requirements are defined in advance through input from business experts so that they can be incorporated into the design of a new data repository or adapted in the iteration of an existing one.
Ideally, data models are living documents that evolve with changing business needs. They play an important role in supporting business decisions and in planning systems architecture and strategy. The data models must be kept in sync with the databases they represent so that they are useful to the maintenance routines of those databases.
Common Database Maintenance Challenges
Maintaining a database requires constant monitoring, automated or otherwise, to ensure it does not lose its virtues. Database maintenance best practices ensure databases always keep their:
- Integrity and quality of information
- Performance
- Availability
- Scalability
- Adaptability to changes
- Traceability
- Security
Many data modeling tips are available to help you create a good database design every time. The ones discussed below aim specifically at ensuring or facilitating the maintenance of the database qualities mentioned above.
Integrity and Information Quality
A fundamental goal of database maintenance best practices is to ensure the information in the database keeps its integrity. This is critical to the users keeping their faith in the information.
There are two types of integrity: physical integrity and logical integrity.
Physical Integrity
Maintaining the physical integrity of a database is done by protecting the information from external factors such as hardware or power failures. The most common and widely accepted approach is through an adequate backup strategy that allows the recovery of a database in a reasonable time if a catastrophe destroys it.
For DBAs and server administrators who manage database storage, it is useful to know if databases can be partitioned into sections with different update frequencies. This allows them to optimize storage usage and backup plans.
Data models can reflect that partitioning by identifying areas of different data “temperature” and by grouping entities into those areas. “Temperature” refers to the frequency with which tables receive new information. Tables that are updated very frequently are the “hottest”; those that are never or rarely updated are the “coldest.”
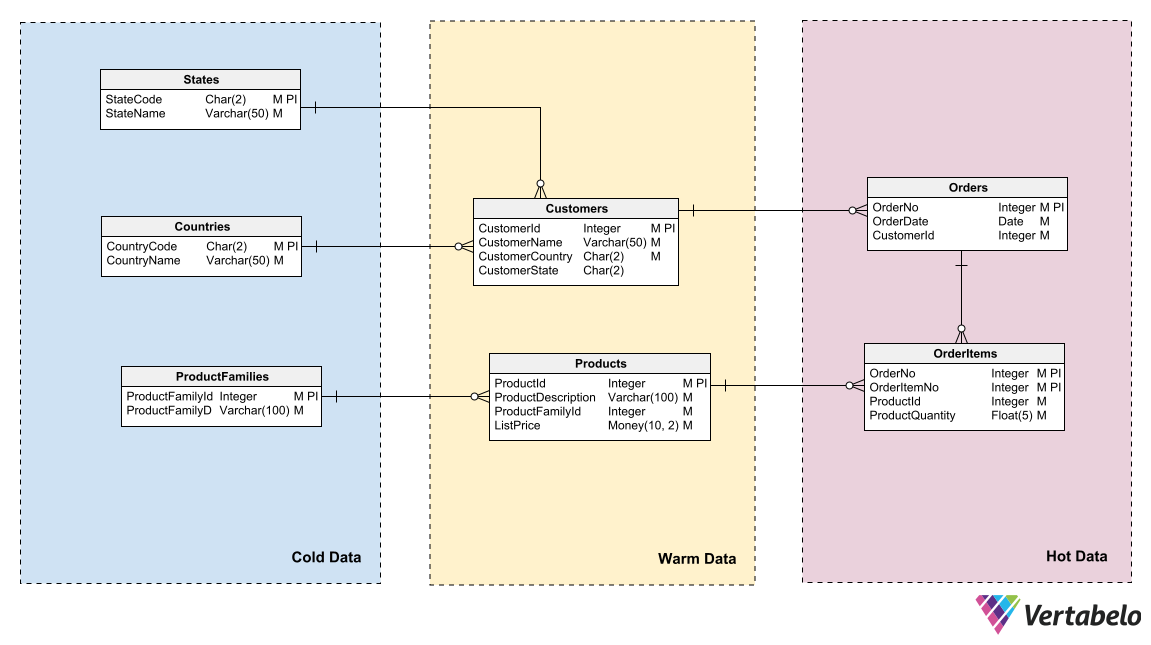
Data model of an e-commerce system differentiating hot, warm, and cold data.
A DBA or system administrator can use this logical grouping to partition the database files and create different backup plans for each partition.
Logical Integrity
Maintaining the logical integrity of a database is essential for the reliability and usefulness of the information it delivers. If a database lacks logical integrity, the applications that use it reveal inconsistencies in the data sooner or later. Faced with these inconsistencies, users distrust the information and simply look for more reliable data sources.
Among the database maintenance tasks, maintaining the logical integrity of the information is an extension of the database modeling task, only that it begins after the database is put into production and continues throughout its lifetime. The most critical part of this area of maintenance is adapting to changes.
Change Management
Changes in business rules or requirements are a constant threat to the logical integrity of databases. You may feel happy with the data model you have built, knowing that it is perfectly adapted to the business, that it responds with the right information to any query, and that it leaves out any insertion, update, or deletion anomalies. Enjoy this moment of satisfaction, because it is short-lived!
Maintenance of a database involves facing the need to make changes in the model daily. It forces you to add new objects or alter the existing ones, modify the cardinality of the relationships, redefine primary keys, change data types, and do other things that make us modelers shiver.
Changes happen all the time. It may be some requirement was explained wrong from the beginning, new requirements have surfaced, or you have unintentionally introduced some flaw in your model (after all, we data modelers are only human).
Your models must be easy to modify when a need for changes arises. It is critical to use a database design tool for modeling that allows you to version your models, generate scripts to migrate a database from one version to another, and properly document every design decision.
Without these tools, every change you make to your design creates integrity risks that come to light at the most inopportune times. Vertabelo gives you all this functionality and takes care of maintaining the version history of a model without you even having to think about it.
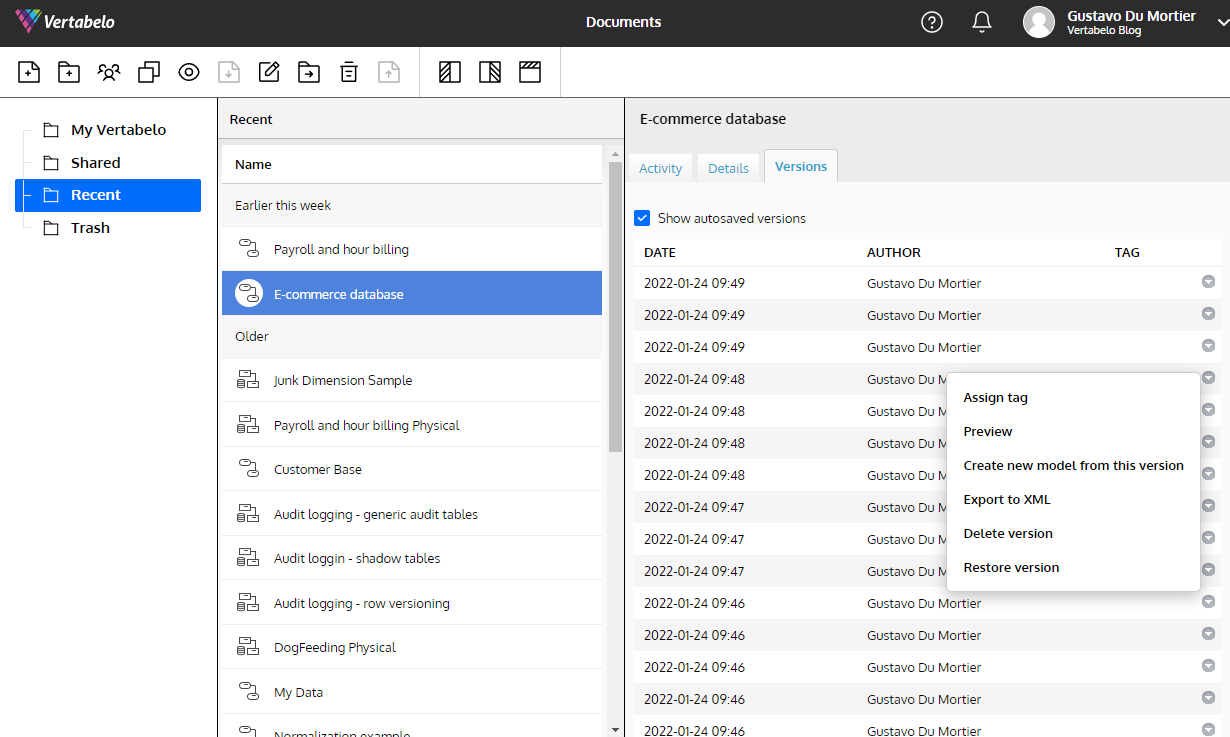
The automatic versioning built into Vertabelo is a tremendous help in maintaining changes to a data model.
Change management and version control are also crucial factors in embedding data modeling activities into the software development lifecycle.
Refactoring
When you apply changes to a database in use, you need to be 100% sure that no information is lost and that its integrity is unaffected as a consequence of the changes. To do this, you can use refactoring techniques. They are normally applied when you want to improve a design without affecting its semantics, but they can also be used to correct design errors or adapt a model to new requirements.
There are a large number of refactoring techniques. They are usually employed to give new life to legacy databases, and there are textbook procedures that ensure the changes do not harm the existing information. Entire books have been written about it; I recommend you read them.
But to summarize, we can group refactoring techniques into the following categories:
- Data quality: Making changes that ensure data consistency and coherence. Examples include adding a lookup table and migrating to it data repeated in another table and adding a constraint on a column.
- Structural: Making changes to table structures that do not alter the semantics of the model. Examples include combining two columns into one, adding a substitute key, and splitting a column into two.
- Referential integrity: Applying changes to ensure that a referenced row exists within a related table or that an unreferenced row can be deleted. Examples include adding a foreign key constraint on a column and adding a non-null value constraint to a table.
- Architectural: Making changes aimed at improving the interaction of applications with the database. Examples include creating an index, making a table read-only, and encapsulating one or more tables in a view.
Techniques that modify the semantics of the model, as well as those that do not alter the data model in any way, are not considered refactoring techniques. These include inserting rows to a table, adding a new column, creating a new table or view, and updating the data in a table.
Maintaining Information Quality
The information quality in a database is the degree to which the data meets the organization’s expectations for accuracy, validity, completeness, and consistency. Maintaining data quality throughout the life cycle of a database is vital for its users for making correct and informed decisions using the data in it.
Your responsibility as a data modeler is to ensure your models keep their information quality at the highest possible level. To do this:
- The design must follow at least the 3rd normal form so that insertion, update, or deletion anomalies do not occur. This consideration applies mainly to databases for transactional use, where data is added, updated, and deleted regularly. It does not strictly apply in databases for analytical use (i.e., data warehouses), since data update and deletion are rarely performed, if ever.
- The data types of each field in each table must be appropriate to the attribute they represent in the logical model. This goes beyond properly defining whether a field is of a numeric, date, or alphanumeric data type. It is also important to correctly define the range and the precision of values supported by each field. An example: an attribute of type Date implemented in a database as a Date/Time field may cause problems in queries, since a value stored with its time part other than zero may fall outside the scope of a query that uses a date range.
- The dimensions and facts that define the structure of a data warehouse must align with the needs of the business. When designing a data warehouse, the dimensions and facts of the model must be defined correctly from the very beginning. Making modifications once the database is operational comes with a very high maintenance cost.
Managing Growth
Another major challenge in maintaining a database is preventing its growth from reaching the storage capacity limit unexpectedly. To help with storage space management, you can apply the same principle used in backup procedures: group the tables in your model according to the rate at which they grow.
A division into two areas is usually sufficient. Place the tables with frequent row additions in one area, those to which rows are rarely inserted in another. Having the model sectored this way allows storage administrators to partition the database files according to the growth rate of each area. They can distribute the partitions among different storage media with different capacities or growth possibilities.
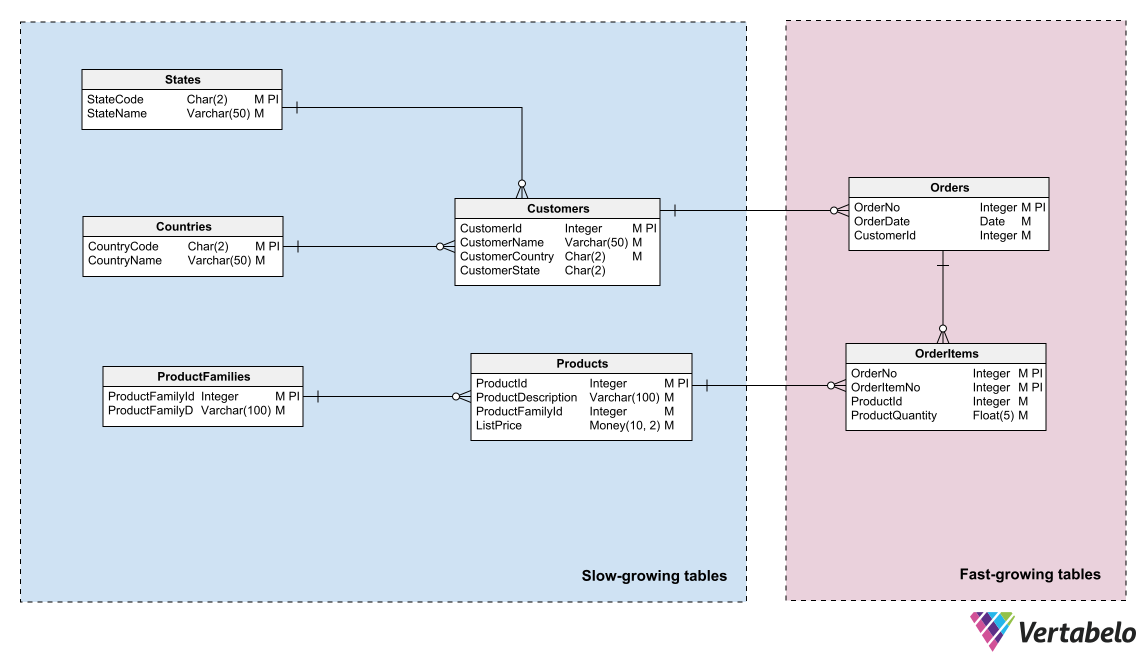
A grouping of tables by their growth rate helps determine the storage requirements and manage its growth.
Logging
We create a data model expecting it to provide the information as it is at the time of the query. However, we tend to overlook the need for a database to remember everything that has happened in the past unless users specifically require it.
Part of maintaining a database is knowing how, when, why, and by whom a particular piece of data was altered. This may be for things such as finding out when a product price changed or reviewing changes in the medical record of a patient in a hospital. Logging can be used even to correct user or application errors since it allows you to roll back the state of information to a point in the past without the need to resort to complicated backup restoration procedures.
Again, even if users do not need it explicitly, considering the need for proactive logging is a very valuable means of facilitating database maintenance and demonstrating your ability to anticipate problems. Having logging data allows immediate responses when someone needs to review historical information.
There are different strategies for a database model to support logging, all of which add complexity to the model. One approach is called in-place logging, which adds columns to each table to record version information. This is a simple option that does not involve creating separate schemas or logging-specific tables. However, it does impact the model design because the original primary keys of the tables are no longer valid as primary keys – their values are repeated in rows that represent different versions of the same data.
Another option to keep log information is to use shadow tables. Shadow tables are replicas of the model tables with the addition of columns to record log trail data. This strategy does not require modifying the tables in the original model, but you need to remember to update the corresponding shadow tables when you change your data model.
Yet another strategy is to employ a subschema of generic tables that record every insertion, deletion, or modification to any other table.
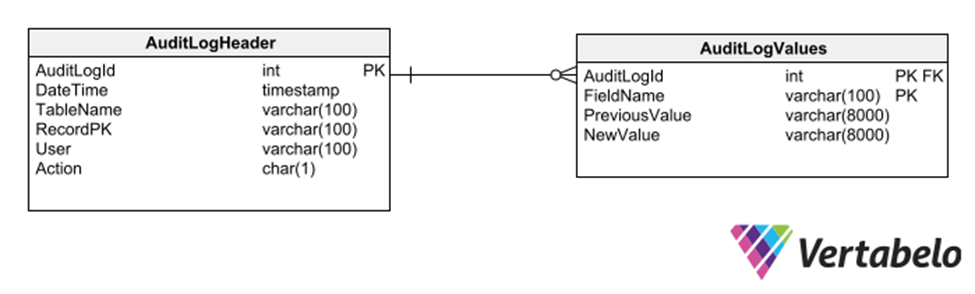
Generic tables to keep an audit trail of a database.
This strategy has the advantage that it does not require modifications to the model for recording an audit trail. However, because it uses generic columns of the varchar type, it limits the types of data that can be recorded in the log trail.
Performance Maintenance and Index Creation
Practically any database has good performance when it is just starting to be used and its tables contain only a few rows. But as soon as applications start to populate it with data, performance may degrade very quickly if precautions are not taken in designing the model. When this happens, DBAs and system administrators call on you to help them solve performance problems.
The automatic creation/suggestion of indexes on production databases is a useful tool for solving performance problems “in the heat of the moment.” Database engines can analyze database activities to see which operations take the longest and where there are opportunities to speed up by creating indexes.
However, it is much better to be proactive and anticipate the situation by defining indexes as part of the data model. This greatly reduces maintenance efforts for improving database performance.
There are practical rules that provide enough guidance for creating the most important indexes for efficient queries. The first is to generate indexes for the primary key of each table. Practically every RDBMS generates an index for each primary key automatically, so you can forget about this rule.
Another rule is to generate indexes for alternative keys of a table, particularly in tables for which a surrogate key is created. If a table has a natural key that is not used as a primary key, queries to join that table with others very likely do so with the natural key, not the surrogate. Those queries do not perform well unless you create an index on the natural key.
The next rule of thumb for indexes is to generate them for all fields that are foreign keys. These fields are great candidates for establishing joins with other tables. If they are included in indexes, they are used by query parsers to speed up execution and improve database performance.
Finally, it is a good idea to use a profiling tool on a staging or QA database during performance tests to detect any index creation opportunities that are not obvious. Incorporating the indexes suggested by the profiling tools into the data model is extremely helpful in achieving and maintaining the performance of the database once it is in production.
Security
In your role as a data modeler, you can help maintain database security by providing a solid and secure base in which to store data for user authentication. Keep in mind this information is highly sensitive and must not be exposed to cyber-attacks.
For your design to simplify the maintenance of database security, follow the best practices for storing authentication data, the main one among which is not to store passwords in the database even in encrypted form. Storing only its hash instead of the password for each user allows an application to authenticate a user login without creating any password exposure risk.
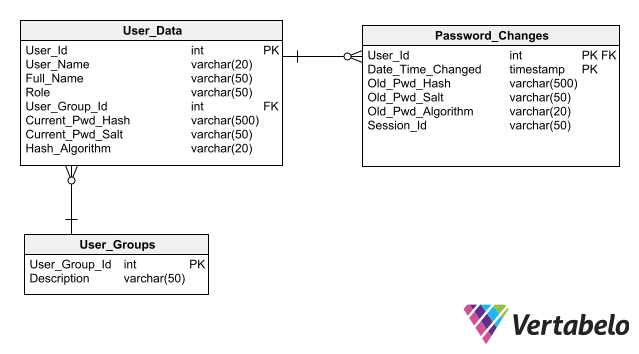
A complete schema for user authentication that includes columns for storing password hashes.
Vision for the Future
So, create your models for easy database maintenance with good database designs by taking into account the tips given above. With more maintainable data models, your work looks better, and you gain the appreciation of DBAs, maintenance engineers, and system administrators.
You also invest in peace of mind. Creating easily maintainable databases means you can spend your working hours designing new data models, rather than running around patching databases that fail to deliver correct information on time.
