

Thinking of a database design for audit logging? Remember what happened to Hansel and Gretel: they thought leaving a simple trail of breadcrumbs was a good way to trace their steps.
When we design a data model, we are trained to apply the philosophy that now is all that exists. For example, if we design a schema to store prices for a product catalog, we may think that the database only needs to tell us the price of each product at the present moment. But if we wanted to know if the prices were modified and, if so, when and how those modifications occurred, we would be in trouble. Of course, we could design the database specifically to keep a chronological record of changes – commonly known as an audit trail or audit log.
Audit logging allows a database to have a ‘memory’ of past events. Continuing with the price list example, a proper audit log will allow the database to tell us exactly when a price was updated, what the price was before it was updated, who updated it, and from where.
Database Audit Logging Solutions
It would be great if the database could keep a snapshot of its state for every change that occurs in its data. This way, you could go back to any point in time and see how the data was at that precise moment just as if you were rewinding a movie. But that way of generating audit logging is obviously impossible; the resulting volume of information and the time it would take to generate the logs would be too high.
Audit logging strategies are based on generating audit trails only for data that can be deleted or modified. Any alteration in them must be audited to roll back changes, query the data in history tables, or track suspicious activity.
There are several popular audit logging techniques, but none of them serve every purpose. The most effective ones are often expensive, resource intensive, or performance degrading. Others are cheaper in terms of resources but are either incomplete, cumbersome to maintain, or require a sacrifice in design quality. Which strategy you choose will depend on the application requirements and the performance limits, resources, and design principles you need to respect.
Out-of-the-Box Logging Solutions
These audit logging solutions work by intercepting all commands sent to the database and generating a change log in a separate repository. Such programs offer multiple configuration and reporting options to track user actions. They can log all actions and queries sent to a database, even when they come from users with the highest privileges. These tools are optimized to minimize performance impact, but this often comes at a monetary cost.
The price of dedicated audit trail solutions can be justified if you’re handling highly sensitive information (such as medical records) where any alteration of the data must be perfectly monitored and auditable and the audit trail must be unalterable. But when audit trail requirements are not as stringent, the cost of a dedicated logging solution can be excessive.
The native monitoring tools offered by relational database systems (RDBMSs) can also be used to generate audit trails. Customization options allow filtering which events are recorded, so as not to generate unnecessary information or overload the database engine with logging operations that will not be used later. The logs generated in this way allow detailed tracking of the operations executed on the tables. However, they are not useful for querying history tables, since they only record events.
The most economical option for maintaining an audit trail is to specifically design your database for audit logging. This technique is based on log tables that are populated by triggers or mechanisms specific to the application that updates the database. There is no universally accepted approach for audit logging database design, but there are several commonly used strategies, each of which has its pros and cons.
Database Audit Logging Design Techniques
Row Versioning for Audit Logging In Place
One way to maintain an audit trail for a table is to add a field that indicates the version number of each record. Insertions into the table are saved with an initial version number. Any modifications or deletions actually become insertion operations, where new records are generated with the updated data and the version number is incremented by one. You can see an example of this audit logging in place design below:
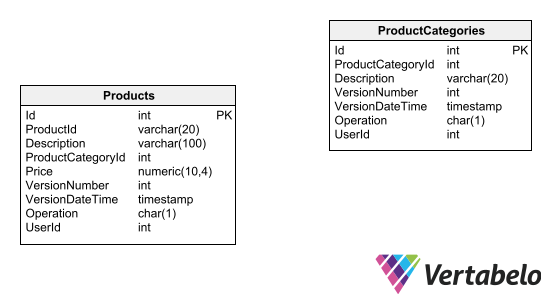
Note: Table designs with embedded row versioning cannot be linked by foreign key relationships.
In addition to the version number, some extra fields should be added to the table to determine the origin and cause of each change made to a record:
- The date/time when the change was recorded.
- The user and application.
- The action performed (insert, update, delete), etc. For the audit trail to be effective, the table must only support insertions (updates and deletions should not be allowed). The table also necessarily requires a surrogate primary key, since any other combination of fields will be subject to repetition.
To access the updated table data through queries, you must create a view that returns only the latest version of each record. Then, you must replace the name of the table with the name of the view in all queries except those specifically intended to view the chronology of records.
This versioning option’s advantage is that it does not require using additional tables to generate the audit trail. Plus, only a few fields are added to the audited tables. But it has a huge disadvantage: it will force you to make some of the most common database design errors. These include not using referential integrity or natural primary keys when it is necessary to do so, making it impossible to apply the basic principles of entity-relationship diagram design. You can visit these useful resources on database design errors, so you’ll be warned on what other practices should be avoided.
Shadow Tables
Another audit trail option is to generate a shadow table for each table that needs to be audited. The shadow tables contain the same fields as the tables they audit, plus the specific audit fields (the same ones mentioned for the row versioning technique).
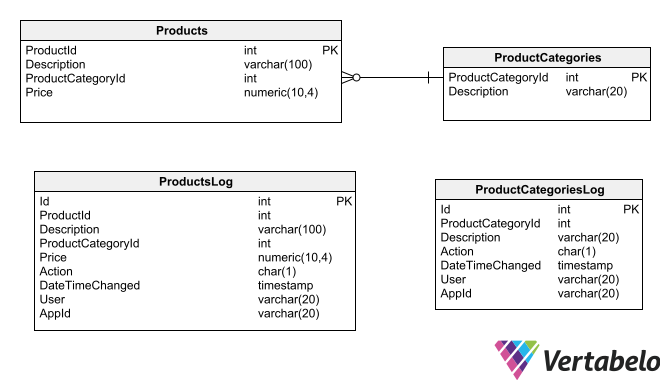
Shadow tables replicate the same fields as the tables they audit, plus the fields specific for auditing purposes.
To generate audit trails in shadow tables, the safest option is to create insert, update and delete triggers, that for each affected record in the original table generate a record in the audit table. The triggers should have access to all the audit information you need to record in the shadow table. You will have to use the database engine’s specific functionality to obtain data such as the current date and time, logged user, application name, and the location (network address or computer name) where the operation originated.
If using triggers is not an option, the logic to generate the audit trails should be part of the application stack, in a layer ideally located just before the data persistence layer, so that it can intercept all the operations directed towards the database.
This kind of log table should only allow record insertion; if they allow modifying or deleting, the audit trail would no longer fulfill its function. The tables also must use surrogate primary keys, as the dependencies and relationships of the original tables cannot be applied to them.
If the table for which you have created an audit trail has tables on which it depends, these should also have corresponding shadow tables. This is so that the audit trail is not orphaned if changes are made to the other tables.
Shadow tables are convenient because of their simplicity and because they do not affect the integrity of the data model; the audit trails remain in separate tables and are easy to query. The drawback is that the scheme is not flexible: any change in the structure of the main table must be reflected in the corresponding shadow table, which makes it difficult to maintain the model. In addition, if audit logging needs to be applied to a large number of tables, the number of shadow tables will also be high, making schema maintenance even harder.
Generic Tables for Audit Logging
A third option is to create generic tables for audit logs. Such tables allow the logging of any other table in the schema. Only two tables are required for this technique:
A header table that records:
- The date and time of the change.
- The name of the table.
- The key of the affected row.
- The user data.
- The type of operation performed.
A details table that records:
- The names of each affected field.
- The field value(s) before the modification.
- The field value(s) after the modification. (You may omit this if necessary, as it can be obtained by consulting the following record in the audit trail or the corresponding record in the audited table.)
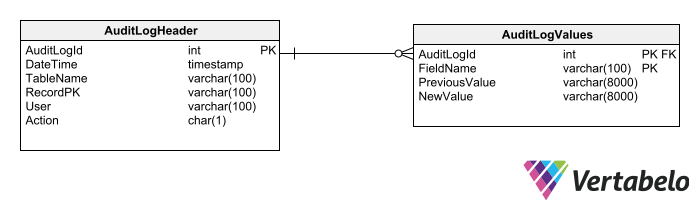
The use of generic audit log tables places limits on the types of data that can be audited.
This audit logging strategy’s advantage is that it does not require any tables other than the two mentioned above. Also, records are stored in it only for the fields that are affected by an operation. This means that there is no need to replicate a whole row of a table when only one field is modified. In addition, this technique allows you to keep a log of as many tables as you want – without cluttering the schema with a large number of additional tables.
The disadvantage is that the fields that store the values must be of a single type – and wide enough to store even the largest of the fields of the tables for which you want to generate an audit log. It is most common to use VARCHAR-type fields that accept a large number of characters.
If, for example, you need to generate an audit log for a table that has one VARCHAR field of 8,000 characters, the field that stores the values in the audit table must also have 8,000 characters. This is true even if you just store one integer in that field. On the other hand, if your table has fields of complex data types, such as images, binary data, BLOBs, etc., you will need to serialize their contents so that they can be stored in the log tables’ VARCHAR fields.
Choose Your Database Audit Log Design Wisely
We have seen several alternatives for generating audit logging, but none of them is really optimal. You must adopt a logging strategy that does not substantially affect the performance of your database, does not make it grow excessively, and can meet your traceability requirements. If you only want to store logs for a few tables, shadow tables may be the most convenient option. If you want the flexibility to log any table, generic logging tables may be best.
Have you discovered another way to keep an audit log for your databases? Share it in the comments section below – your fellow database designers will be very grateful!
