

Different scenarios call for different data modeling techniques for the greatest benefit. Knowing what type of data model to create is very important. Applying the right technique saves you a lot of headaches and avoids common errors. We go into a bit of detail about what these techniques are and how they are applied.
What Is Data Modeling?
Data modeling involves building a diagram that represents the data structure to support a new software application. It is an essential step in developing a data architecture or structure for the data you want to store.
Not only does a data model need to support your application data, but it also needs to support the business processes that fuel your organization. Sometimes, it needs to keep track of changing data, versions of previous data fields, and the creators and the entities involved in this new data.
If you want to learn more, read this deep-dive article about data modeling.
The Data Modeling Process
The process evolves a data model in three main phases with different levels of detail: the conceptual data model, the logical data model, and the physical data model. Each of these represents an evolution from the previous phase, with additional details as they are discovered. The new information related to new types of data or new business processes may even change the shape of the data model.
The data modeling process needs to identify a set of key elements to produce a valid data model. It needs to identify the entities that generate the data and the types of data it generates. Also, each new piece of data may have some constraints not only on its type but also on its values. Some data points need to be unique in the context of the data model to support data linking between entities.
This data linking, also called the data relationship, is created between data entities in the model. Sometimes, storing data related to the same entity or process in smaller tables improves both the structure and the performance.
The Conceptual Data Model
The first step in any data modeling process is the conceptual phase to identify the entities that build out our data model and their relationships. The goal is to have a basic outline of the data structure and a common ground for discussion with the business team to make sure your model is right for the job.
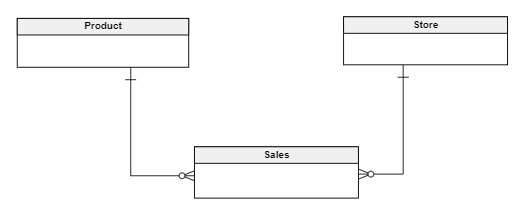
The Logical Data Model
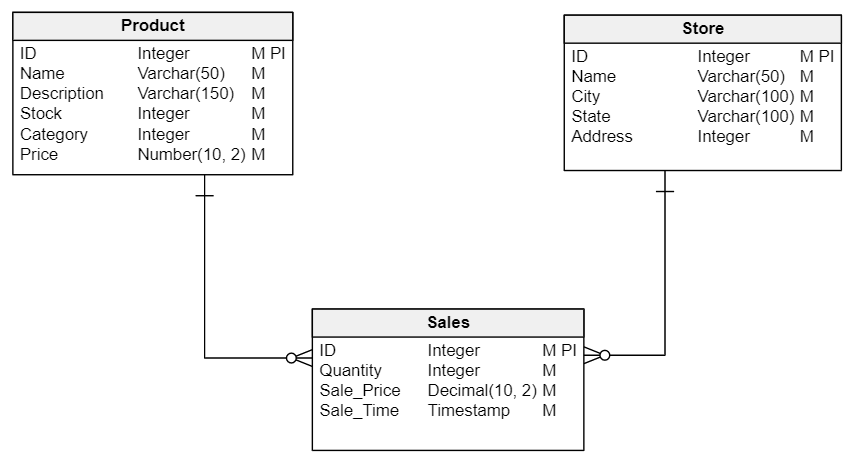
The logical data model expands the conceptual model and adds more information about the attributes of each entity including the primary identifier. We also make sure the cardinality between the entities is correct. We see what a logical model looks like in the diagram below. The primary identifier is marked with “PI”; “M” (for “mandatory”) indicates that it needs to be stored for every row.
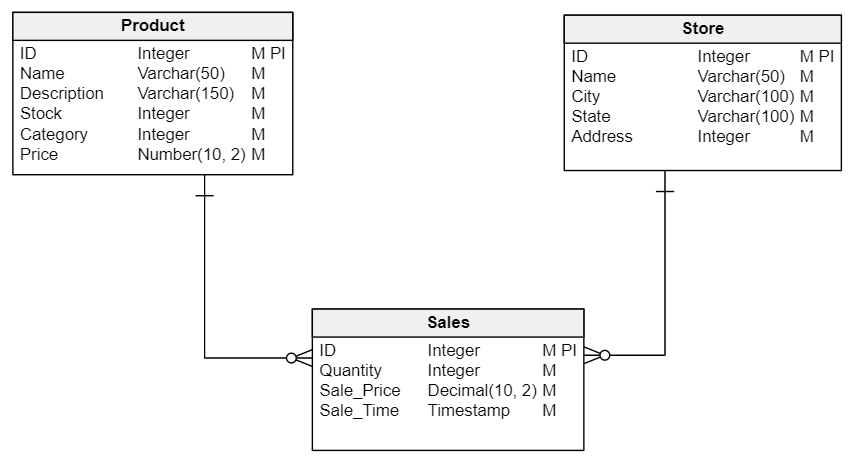
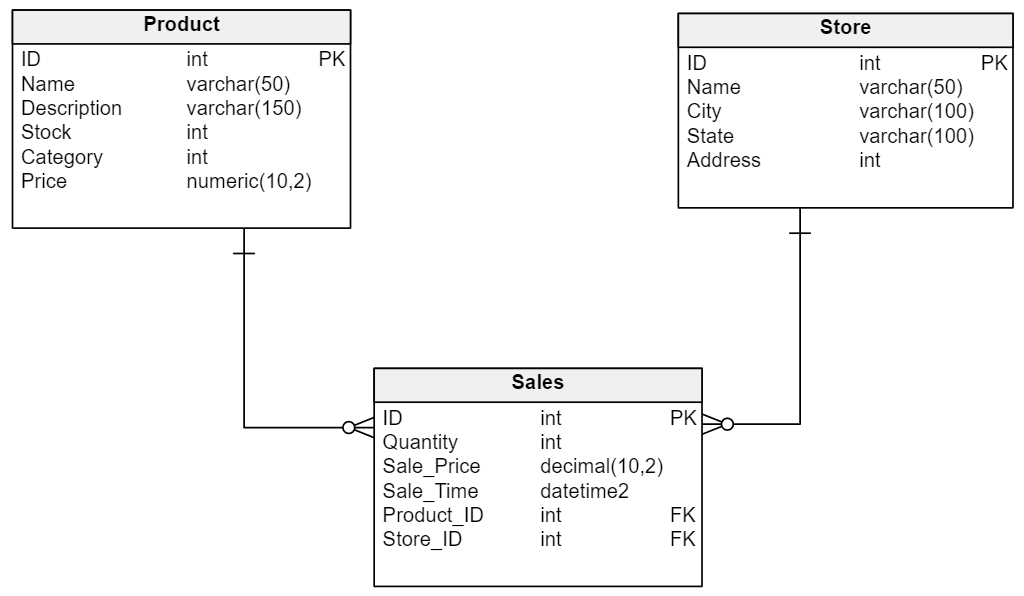
The Physical Data Model
Once we have our logical model, we build the physical data model. In the diagram below, you see the physical model is very similar to the logical one but with more details about the attributes of each entity. The entities become tables, and the attributes become columns.
In the physical data model, we also choose the data types of the attributes depending on the database in which we are going to deploy.
If you use a tool like the Vertabelo Modeler, creating a physical model is just 2 clicks away. Once you create the logical model, you simply need to right-click the data model file and select the target database for which you want the physical data model.
Data Modeling Techniques
As mentioned at the beginning of this article, different problems require different data models and data modeling techniques. Below, we outline the most common types of data models as conceptual models and show an implementation diagram for each.
The Hierarchical Data Model
The hierarchical data model is optimized for hierarchical data. An example is an organizational chart for a company in a tree structure. The data is stored in parent and child records, each of which may have a set of attributes.
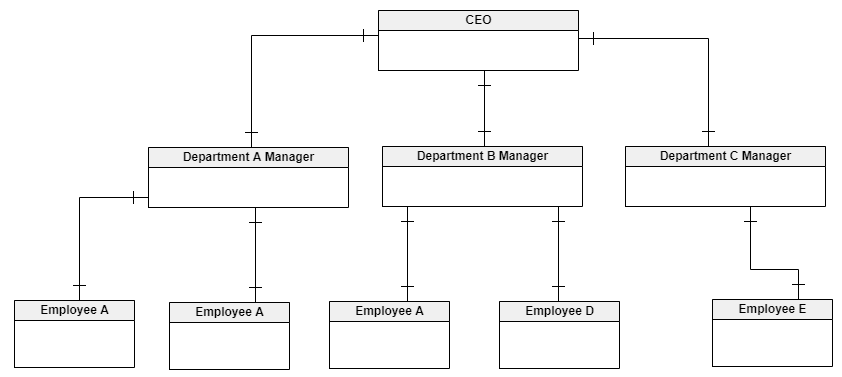
Each parent record can have one or more children; however, a child record can have only one parent.
The Network Data Model
Another technique used in a more special scenario is the network data model. It provides a flexible way to represent the objects and the relationships among them.
A key characteristic of this data model is that its object types are nodes and the relationships form arcs in the graph when the schema is viewed as a graph. This is similar to the hierarchical model; however, the network model does not constrain its arcs to form a hierarchy.
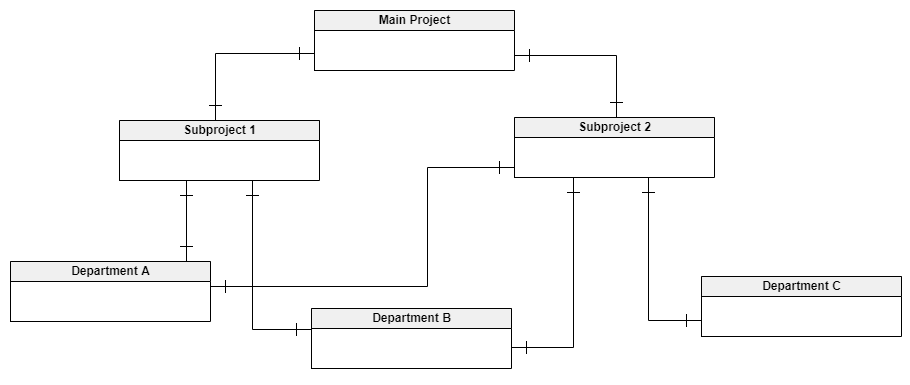
Though not very widespread in the commercial scene, the network data model is at the base of many mainframe computers built in the early days of computer networking in the 1970s. Today, relational databases have replaced most network data model databases.
The Relational Data Model
The relational data model has been the most widely used data model since its appearance in the late 1970s. Its key characteristic is that data is stored in tables and columns. Each table contains information relevant to a single logical entity, like a store for example, and the link between these tables is represented by a relationship.
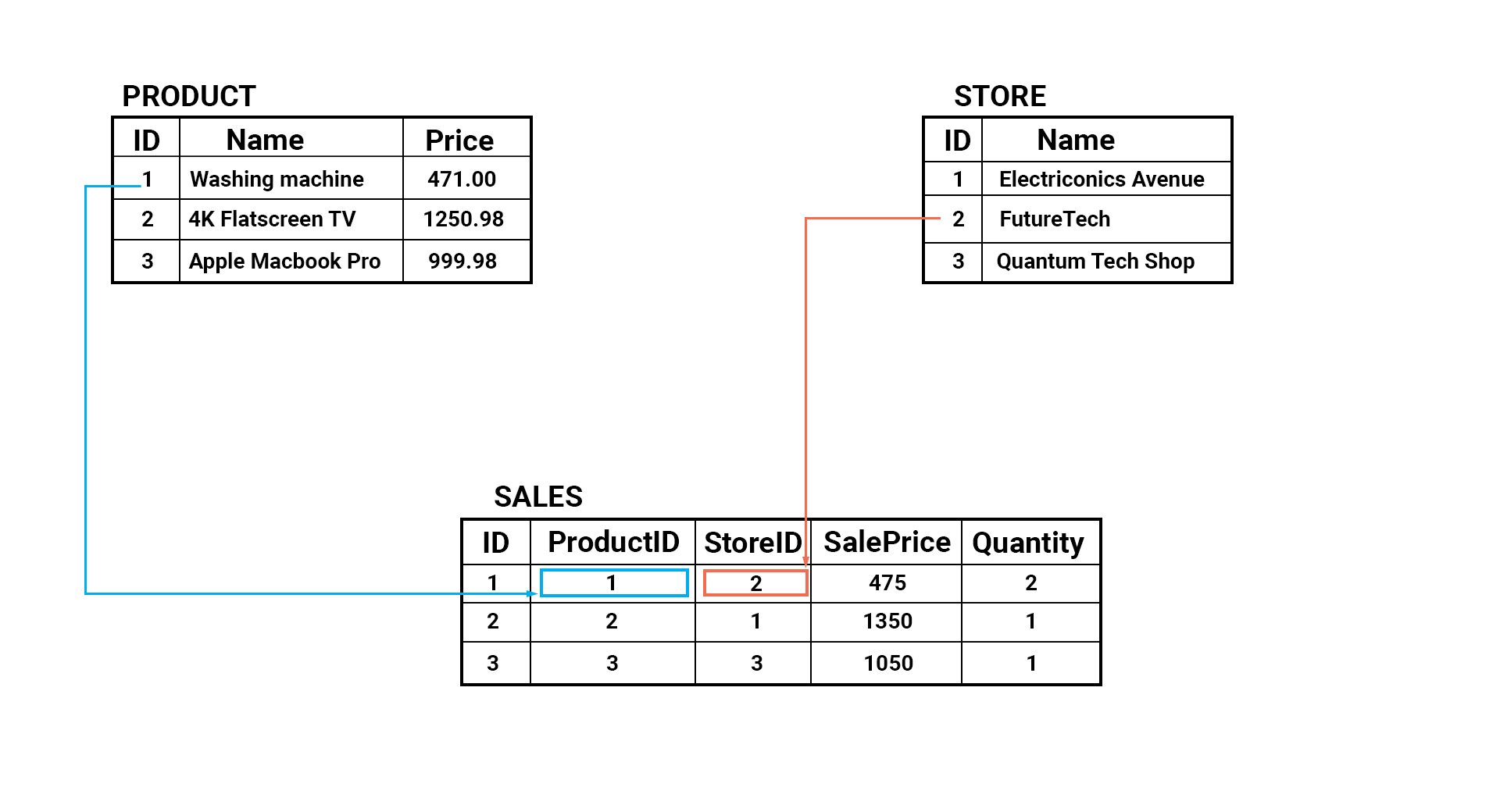
A relationship is represented by a column containing the unique identifier of the main entity as shown in the diagram above.
The Entity-Relationship Data Model
The entity-relationship data model is a variation of the relational model and is widely adopted in enterprise applications built on top of a relational model. It has minimal redundancy among its entities and clearly defined relationships.
The entity-relationship data model is designed to be very efficient in capturing data and updating processes. Its key components are:
- Entities that represent objects, events, people, or concepts on which data is processed from the application and stored in tables.
- Entity attributes, the characteristics unique to a given entity, stored as data in columns.
- Relationships between entities, the logical links between those entities. They may also represent business rules or even constraints.
Most modern applications are built on an entity-relationship data model. We have already seen one in the section on the logical data model.
The Dimensional Data Model
The dimensional data model is also a variation of the relational model. Just like the entity-relationship model, it has attributes and relationships. However, the dimensional data model has only two main categories of attributes for an entity or table: facts and dimensions.
The fact attributes are measurements of a certain activity represented by a dimension. For example, a fact may represent a transaction between a customer and a store. Facts are generally of the numerical data type, and fact tables are highly normalized with very little redundancy.
The dimension attributes are in tables containing the definition of the business item measured by the fact. Dimensions are usually descriptive and of the text data type rather than numeric. They represent the concept, not its measurement.
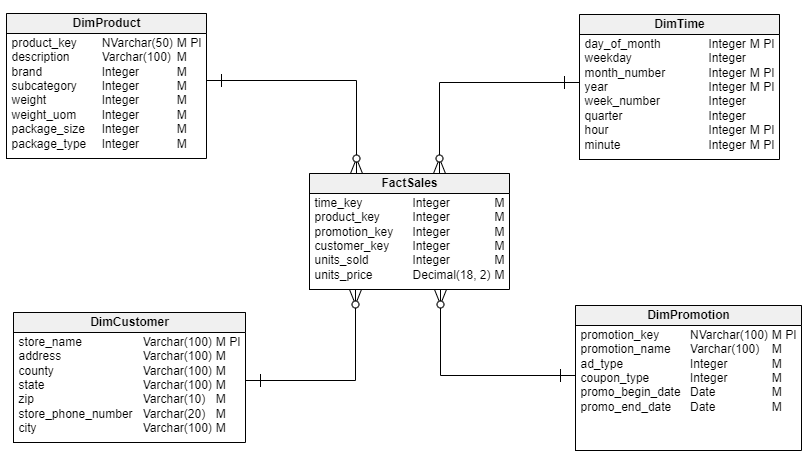
The dimensional data model is widely used in the business intelligence and analytics domains. It’s often called the star schema, with a fact table connected to multiple dimensions.
Get Ready to Apply Data Modeling Techniques!
As we have seen, there are many data modeling techniques for building databases and data structures to hold your application data. It’s not always easy to find the right model for your database; it always depends on the context and your requirements. It is a challenge to build a data model from scratch for a new application, but it can be fun!
