

What are the most important commandments of database design? Find out in this article! Make sure that every one of your designs meets these set of best practices for database design and your database will always run smoothly and swiftly.
To become a database designer, you must invest a lot of time and effort. To learn database design, you must take courses, get a degree, read books, keep up with the latest trends, and practice a lot. Eventually, you’ll become capable of creating data models for any need that is put in front of you.
But even when you’ve come all that way and you’ve dedicated yourself full-time to database design, even when you have acquired all the skills needed by a data modeler, you’re not completely safe from making mistakes. And the mistakes that are made in a database design, when they make their way into a working database, are very difficult and costly to correct.
Therefore, it is a good idea to always have a list of database design “commandments'' at hand. Before you deliver a finished design to become a database, always read that list of commandments – or, to put it more correctly, that list of best practices for database design – and verify that your design complies with all of them.
It doesn’t hurt to print this list of best practices for database design and hang it on a wall in your office so that you always have them in sight. This way, you will not forget to review them every time you are about to deliver a database design. Plus, it will help you with the data modeling challenges you face every day.
So, let’s take a look at the 11 top database design best practices.
The 11 Commandments: Best Practices of Database Design
#1 Create 3 Diagrams for Each Model: Conceptual, Logical, and Physical
Many times, we are tempted to ignore the conceptual and logical diagrams and proceed directly to the physical diagram to save time. That time that you “saved” by skipping the conceptual and logical diagrams will surely be lost in the future, when you have to make modifications to the model. And if someone else needs to modify your model, they will waste much more time trying to understand the functional and conceptual foundations of your data models.
The best practice here is to work first on the conceptual, then on the logical and finally on the physical diagram every time you have to make modifications to a data model. Tools such as Vertabelo promote this good practice by easing the transition from a conceptual to a logical diagram and from a logical to a physical one.
You also should make sure your database diagram is easily readable by anyone who needs to use it. For this, I suggest you read this series of tips for improving your database diagram layout.
#2 Follow a Naming Convention
Before delivering a database design, make sure that the design has an explicit database schema naming convention associated with it. Check that all table, column, view and other database object names conform to that naming convention.
Keeping a naming convention should be among every designer’s list of best practices for data modeling. The importance of a naming convention goes far beyond a matter of aesthetics or neatness. The names of objects in a database cannot be happily changed once the database is operational. Making changes to names can cause failures in the applications that use the database or break constraints necessary to maintain the integrity of the information. In addition, a naming convention makes it easier to understand the data model and simplifies work for the programmers who must write code to access the data.
Earlier I said that the naming convention must be explicit. It is a good idea to use annotations in your ERDs (I guess you know what an ERD is, right?). In these notes, make sure the conventions used in the model are carefully detailed. Vertabelo lets you add text notes to its diagrams, which allows you to embed documentation – for example, the naming conventions used in the design – as an inseparable part of the diagram.
#3 Keep Documentation Up to Date
In addition to always keeping the conceptual, logical, and physical versions of the data model current, you must also keep the documentation that accompanies your data model up to date. This documentation can be a data dictionary in a separate document (which Vertabelo can generate automatically) or it can be in notes attached to your ERDs, such as the in-diagram text notes we mentioned earlier.
The use of notes and additional documentation allows you to accompany conventional database design artifacts (mainly ERDs) with useful information and database modeling tips for developers, programmers, and DBAs. For example, you might include suggestions on how to use views or how to take advantage of indexes. Or you might explain the differences between different versions of a data model.
Many times, we designers create useful elements for developers (such as a view that saves a lot of lines of code). But because of a lack of communication, developers never find out about them. Up-to-date documentation prevents this from happening.
#4 Use Model Versioning
Changes made to a data model should generate a new version of it, keeping the previous version for reference and traceability. The same database can be used by multiple applications, and changes to a database almost always require changes to the applications that use it.
By using model versioning, any developer can see the changes between different versions of a database design. This way, they will know what changes need to be made to applications to adapt them to each new version of the database.
With its automatic version control features, Vertabelo helps you keep these important best practices for data modeling related to model versioning. Its auto-save feature automatically generates new versions of your designs, leaving a record of the time and author of each change.
#5 Set the Appropriate Data Type and Size for Each Column
When generating a physical ERD, you must precisely establish the data type of each column. If it is alphabetic data, you must unequivocally establish the maximum number of characters that the column will admit. If it is numeric, you must set the number of integer and decimal digits – or, in the case of floating point numbers, the number of precision digits. A basic database designer skill you should have is the ability to determine the best data type and size for each field in a database.
There is no option to set approximate sizes. If you define a column with less capacity than it requires, errors will occur in the applications that use the database. If you define a column with an excessive capacity, then the space occupied by the database will be greater than necessary, which may present performance problems.
#6 If Transactional, Normalize; If Dimensional, Denormalize
Data models can be designed to be transactional or dimensional, depending on their intended use. Transactional models are created to support systems that handle online transactions, such as e-commerce or ticket booking applications. Dimensional models, on the other hand, are designed for data analysis applications, such as Business Intelligence or financial analysis tools. Different database modeling tips apply to each of these two types of models.
In transactional models, it is vital to preserve the integrity of the information and avoid anomalies in the data insertion, update, or deletion processes. That is why normalization should be applied to any data model for transactional applications, making sure the model is normalized in 1nf, 2nf, and 3nf. This avoids integrity problems, reduces redundancy, and optimizes the storage space occupied by the database.
In dimensional models, the most important thing is to simplify and speed up access to the summarized information. Database insertions, updates, and deletions are carried out by automatic and controlled processes, so these operations are unlikely to damage the integrity of the data. To achieve simplicity and speed in obtaining information, denormalization techniques are applied; these add redundancy to simplify queries.
#7 Give All Tables a Primary Key
Primary keys are used to uniquely identify each row in a table. If you leave a table without a primary key in your data model, you run the risk of duplicate rows appearing in that table, which will cause queries on that table to return incorrect or inconsistent information. In addition, duplicate rows in a table can cause failures in applications that use the database. For more information, read about what a primary key is and what it does.
The primary key does not support null values in its component columns. When defining a primary key in a table, the database management system automatically generates an index by the fields that compose the key, which helps to improve query performance.
Technically, you can dispense with the primary key by using unique indexes and non-nullable columns. You can even get the same results in terms of performance and integrity. But even so, your tables should still have their primary key.
The primary key of a table facilitates the interpretation of the data model. Any programmer who must write code that interacts with the database will have a better understanding of how to access a table by seeing what its primary key is.
And don’t think that your data model is immutable; you’ll have to make changes to it at some point. When it’s time to make modifications, the existence of primary keys in all tables will save you headaches in migrating the schema and its data to a new version.
#8 Use Surrogate Keys When It Makes Sense to Do So
There are several reasons that justify adding a surrogate primary key to a table:
- The table does not have a set of columns that can uniquely identify each row.
- The columns that make up the natural primary key are very numerous or complex in terms of their data types.
- The natural primary key is very large (e.g. a VARCHAR of 1000 characters).
- The data making up the natural primary key is susceptible to frequent changes.
- The data that makes up the natural primary key represents sensitive or private information.
In addition to the above conditions, adding a surrogate primary key can improve index performance. Primary keys are always accompanied by an index. If the indexed data is simple and small (for example, an INT data type), the index is much more efficient and takes up less storage space than if the indexed data is complex or large.
Some designers directly opt to add a surrogate primary key to all tables, regardless of whether they need it or not. This saves the work of deciding in each case, but has the disadvantage of generating duplicate information – i.e. identical rows that differ only in the surrogate key. This can cause similar data inconsistency problems as if there were no primary key. That is why the decision to use surrogate or natural primary keys is not trivial. It must be carefully analyzed according to the particularities of each table you design.
#9 Define Foreign Keys for Relationships
When two tables are related by one or more columns, a foreign key constraint must exist between them. If the term “foreign key” is new to you, you may want to first read about the ins and outs of foreign keys.
The existence of foreign keys between fields of related tables ensures the fulfillment of several conditions:
- For each row in the relation’s secondary table, there is one and only one corresponding row in the main table. In a one-to-many relationship, the main table appears next to the "one" side and the secondary table appears next to the "many" side.
- Rows in the main table which have related rows in the secondary table cannot be deleted.
- The main table has a unique index formed by the column or columns that link it to the secondary table.
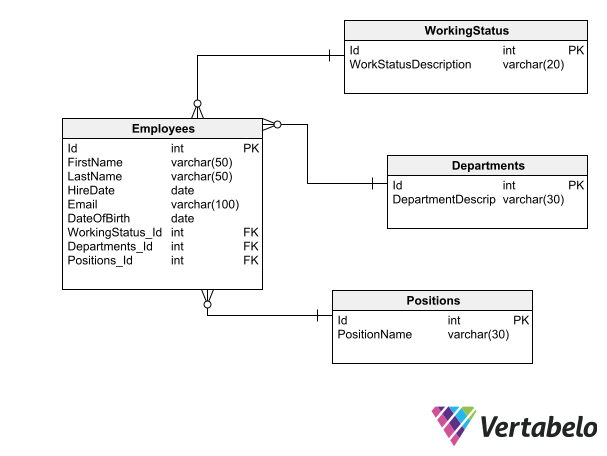
Foreign-key constraints help keep integrity within schemas with related tables. In the above example, the constraints will not let you delete rows from WorkingStatus, Departments, or Positions if there are related rows in Employees.
These conditions guarantee the information’s integrity and consistency by linking both tables, which in turn ensures that the functional requirements that gave rise to the relationship between the tables are met.
#10 Add Indexes to Plan for Performance
Indexes are data structures that allow you to locate information more quickly within the table. Just as the index of a book allows the reader to go directly to a certain page, an index allows you to find a row within a table without having to search through all the rows. Read about what a database index is for more information on the subject.
Indexes can be created when a database is already running, i.e. to fix slowness problems. This requires examining the database activity, determining which queries are causing slowdowns, and analyzing which tables and columns are being accessed by those queries. However, the database designer can anticipate this situation by defining in advance indexes on certain tables and columns.
How can you anticipate the need for indexes when designing a database? To begin with, all primary and foreign keys should have indexes associated with them. This is usually taken care of automatically by the database engine. But if your engine does not handle it automatically, it will be necessary to create indexes for all primary and foreign keys in the schema.
Then it is necessary to consider tables and columns with high cardinality. For these tables, it is necessary to analyze which columns are candidates to be used as search filters, selection criteria, or grouping criteria. Once the columns have been determined, you can create indexes with the relevant subsets of those columns. For example, in an Orders table that gets many queries by Customer and by Date, it will make a lot of sense to create an index for each of those two columns.
Vertabelo lets you include index definitions in your ERDs; when you generate the DDL scripts to create the database, index creation is included in the scripts.
#11 Partition Large Schemas
When a schema grows to such an extent that it becomes difficult to read and understand, it is time to partition it. Partitioning a schema allows you to group the objects that compose it into areas.
For example, in a schema that supplies data to multiple applications, partitions can be established to keep the objects related to each application together. This could be in addition to a partition that groups objects common to all applications.
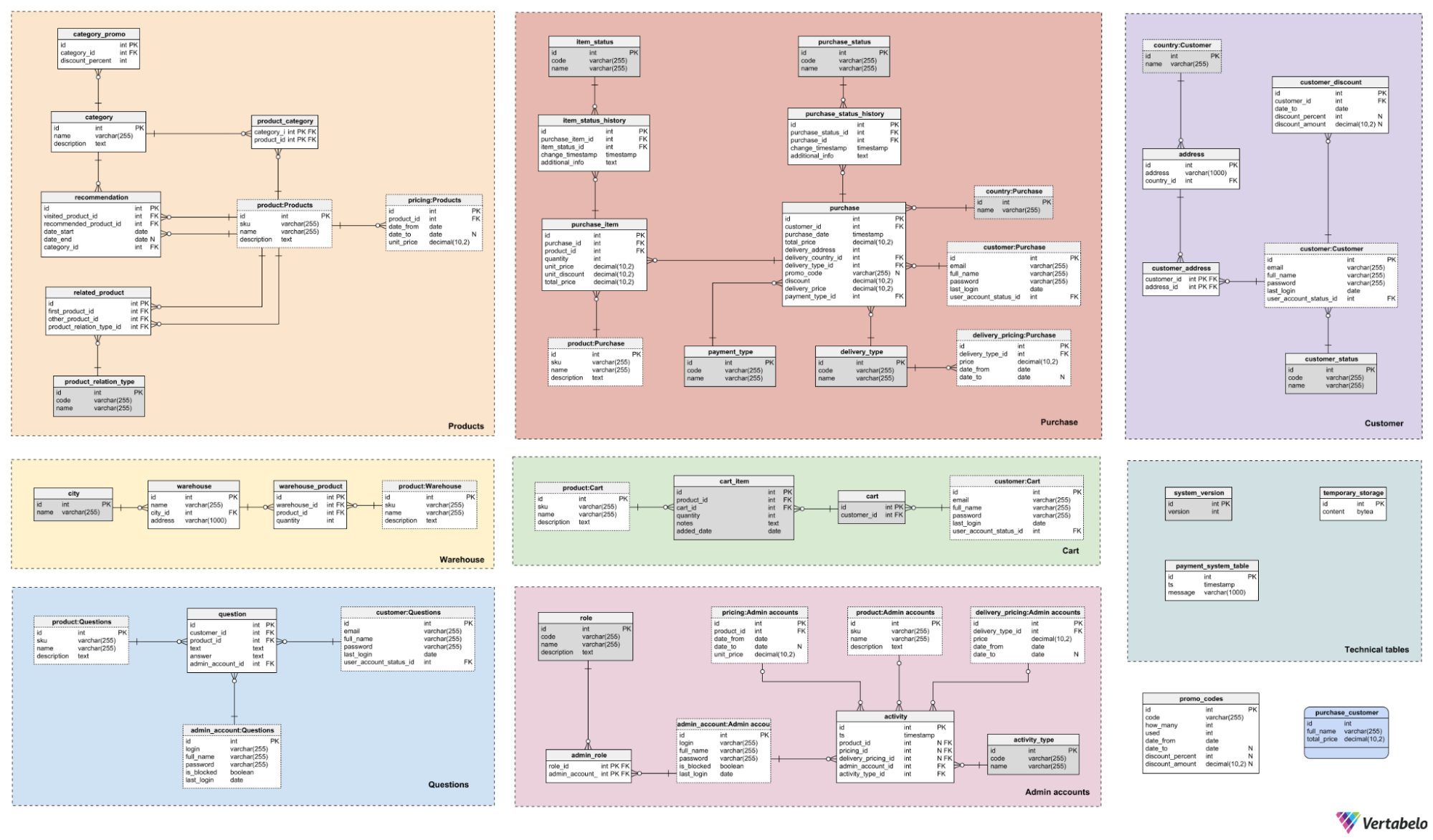
The use of colored subject areas in Vertabelo simplifies the creation of partitions in a database schema.
Partitions can also be used to group objects according to their update frequency. For example, all tables that are updated very frequently can be grouped in one area. All tables that are updated infrequently can be grouped in another area, and all tables that are rarely updated in a third area. This partitioning will be useful when, for example, a DBA needs to place the database tables on different storage media with different levels of performance, capacity, and reliability. Or they might need to set up different backup plans for each partition. Any DBA loves a partitioned ERD that simplifies their work.
Vertabelo makes it easy to partition a schema by grouping tables into subject areas. Each subject area is identified by a name and a color, which provides a visual aid to easily determine the partition to which each table belongs.
Great Database Modeling Is an Ongoing Commitment
With this list of database modeling best practices, you can be confident that your database designs will be robust and durable.
However, to stay on track for success, you must apply these best practices to more than just new schemas. You must also verify that they continue to be followed for every modification you make to any of your existing schemas. So print this list out and remember: to be a great data modeler requires ongoing commitment!
