

Feeling overwhelmed by the amount of time it will take you to learn to be a database designer? Read about the essential skills and talents you’ll need – it’s not so terrible!
When you walk down the aisles of the supermarket, shopping cart in one hand and grocery list in the other, what are you thinking? If you're like me, you're imagining how to improve the organization of the shelves so that your weekly shopping is less time-consuming. Or maybe you feel the same desire to organize and structure information when a friend shows you their large collection of magazines. Or maybe it strikes when you’re managing your playlists to better suit your preferences. If you go through life thinking about how to represent reality in terms of entities, attributes, and relationships, then your vocation is to be a database modeler.
Maybe you’re not quite as extreme but you are still attracted to the idea of pursuing database design as a career. Either way, you will need to master a few new skills. Some of them are purely technical; you can learn these skills by studying or reading and deepen them through work experience. Other skills involve non-technical knowledge that you can learn through courses, blog articles, or by observing others.
Here is a summary of the essential knowledge and skills that every database designer needs to have.
Hard Skills Database Designers Need
Hard skills are those that are acquired through study and honed through practice. If you can demonstrate with concrete evidence that you have mastered a hard skill, it means that you are capable of performing any task that involves it.
In terms of database knowledge, hard skills include the fundamentals of database theory and the various techniques used to apply theoretical concepts to solve concrete problems. Let’s look at each of the hard skills that database designers need.
Database Theory
Database theory is full of abstract concepts that can be difficult to understand if they’re not associated with real-life facts. The relational model, domains, attributes, relations and relationships, primary and foreign keys, entity integrity, referential integrity, and domain constraints are just a few examples. If you add even more complex matters (such as relational algebra or relational calculus) you may wonder if it wouldn’t be better to choose a career dealing with concrete things like gardening or gourmet cooking.
Don't panic. Thorough knowledge of database theory is important if you plan to teach college classes or invent a new way to organize information. But to design databases, you only need to master the theory concepts that apply to solving real-life problems. The most important one – the ABC of database design – is the relational model.
The Relational Model
College professors will tell you that the relational model is a data organization mechanism based on set theory and predicate logic. But that won't do you much good in your day-to-day work as a database modeler. In practice, you need to know that the relational model is an intuitive and straightforward way of organizing data in the form of tables – called relations – which are composed of rows (which are also called tuples). Each table (or relation) is defined by its attributes (or columns).
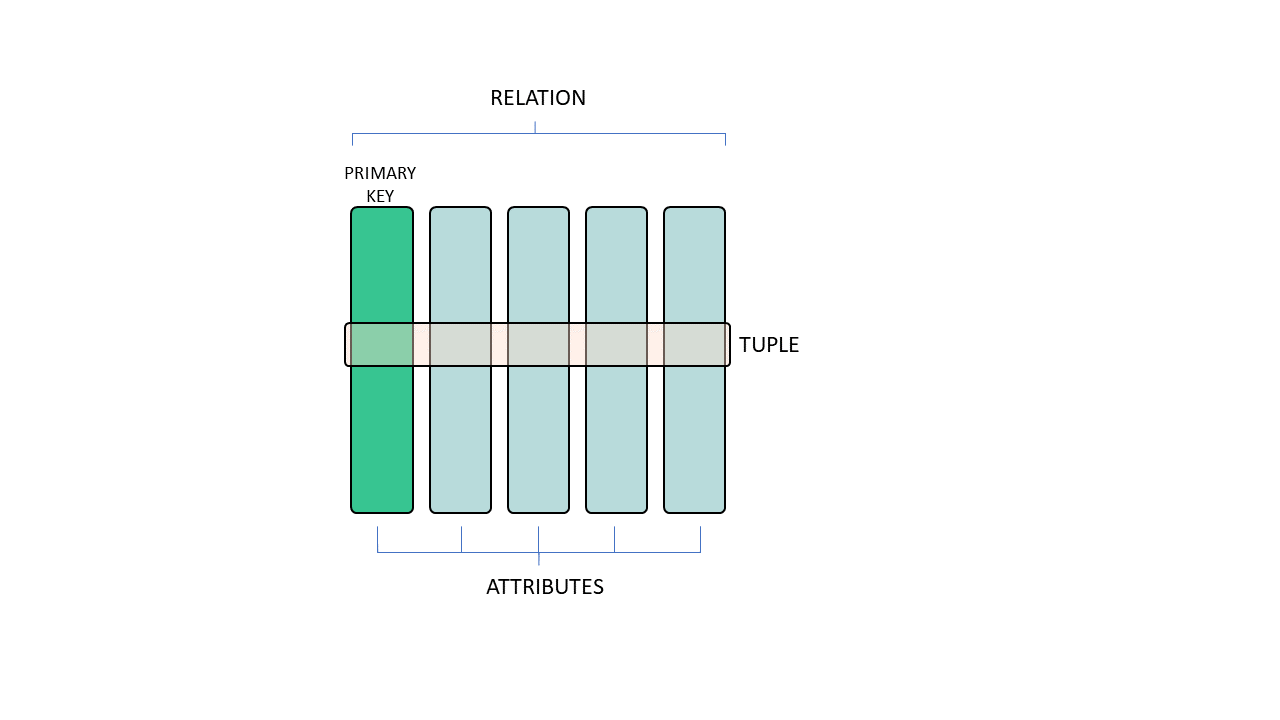
Fundamental concepts of the relational model.
All relations should have one or more outstanding attributes that represent a unique identifier for each tuple. In database slang, that’s the key of the table. Non-key attributes are key-dependent in the sense that each key value determines a single possible value for each attribute.
Imagine a table of vehicle information in which the key is the license plate. The license plate determines the attributes of each vehicle (such as the manufacturer, model, owner, etc.), since the rules of the domain prevent two different vehicles sharing the same license plate.
Relational Databases
Relational database management systems (RDBMSs) implement the relational model, respecting its principles. They offer ways to retrieve information through queries and update information through transactions. For the information in a relational database to reflect real-life facts and situations, you can define conditions or constraints specific to the domain to which the database applies. For example, in a table that stores information about school students, a constraint can be imposed so that the dates of birth do not allow future dates or dates that are too far in the past.
The organization of tables in a database is commonly referred to as the database schema. In addition to tables, the schema details constraints involving pairs of tables called relationships. A relationship connects two tables by imposing the constraint that the values in the field of one of the tables correspond to values in the primary key of the other table.
Database schemas are usually represented by the entity-relationship diagram (ERD), a common tool for any database designer.
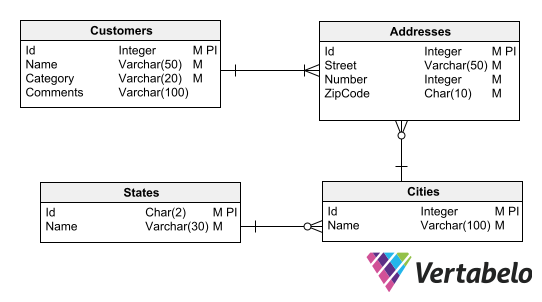
An ERD representing a customer data model.
Anomalies and Normalization
All the concepts we’ve discussed so far are fairly clear, right? Now we can talk about the anomalies that occur in databases due to defective or inadequate design (i.e. the database does not adequately reflect the reality it is trying to represent).
Anomalies occur when an insert, update, or delete operation generates inconsistencies in the data. For example, suppose you have a table to store sales data. For each sale (i.e. in each record of the table), the name and address of the customers is recorded. The anomaly is as follows:
- If the customer's address is modified in one of the sales, and
- The same customer has other sales,
- The other sales will have an outdated address.
To avoid anomalies, you can apply a design technique called database normalization. This involves decomposing tables and columns (i.e. breaking them into smaller parts) to avoid design flaws like:
- Columns that hold more than one piece of information (e.g. an item’s ID number as well as its name).
- Storing the same information more than once in the same table.
- Fields that depend on other non-key fields.
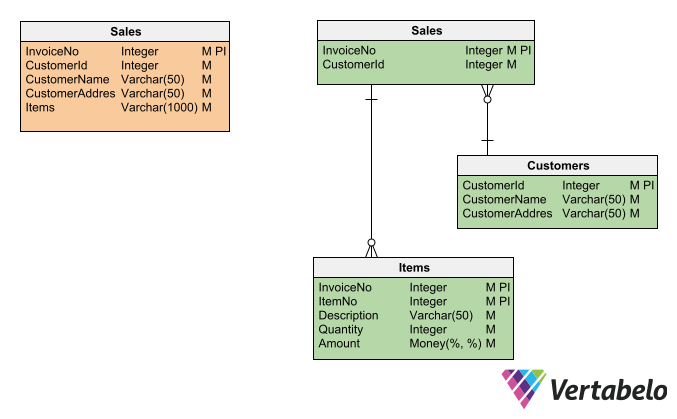
Non-normalized table (left) versus normalized schema (right).
Data Warehouses and Denormalization
Some databases are used for querying large volumes of information instead of online transaction processing (OLTP). These databases are called data warehouses.
The information in a data warehouse does not come from user interfaces (e.g. entered directly from an e-commerce ordering system). It comes from batch processes that collect information from different sources, process it, clean it, and store it in tables. For this reason, we can assume that data warehouses are not exposed to the same anomalies as conventional databases.
Because of that, data warehouses do not need to maintain the same normalization conditions as an OLTP database. On the other hand, it’s more important to optimize query efficiency in data warehouses. This is why denormalization is applied in a data warehouse; this technique uses a certain amount of redundancy to simplify queries and avoid cluttering schemas with an excessive number of tables.
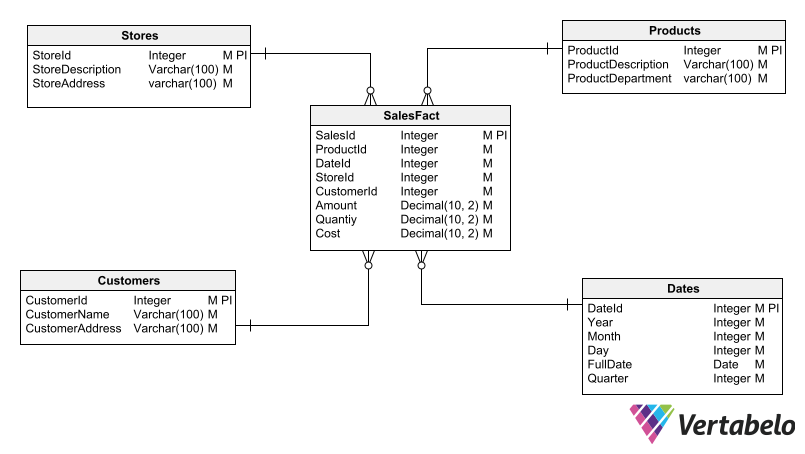
A typical data warehouse schema.
Big Data
Like data warehousing, the concept of Big Data refers to repositories that house large amounts of data. However, there is an important difference between the two concepts. A data warehouse is designed for a specific purpose and is aimed at generating reports whose behavior and format are known in advance.
Big Data, on the other hand, aims at collecting large volumes of data that’s generated at high speed from different sources – e.g. information from social media, microtransactions, or smart sensors. This massive amount of information can be used for exploration and analysis or for training machine learning models.
In Big Data database design, storage space economy and data partitioning (among other things) are prioritized to enable parallelism and real-time data capture. In addition, non-relational or NoSQL database systems are used, which offer better alternatives for handling unstructured information.
Technologies such as NoSQL and the concept of Big Data itself are relatively new compared to relational databases, which are already more than 40 years old. That is why, as a database designer, you must be attentive to new developments in this area. Keep in mind that Big Data is also big business. Many companies want to take a leading position in it and are developing new tools and technologies to do so.
Database Administration
Once a database is up and running, someone has to take care of its daily management. This means doing routine tasks so that the database never becomes a bottleneck for the applications that use it. Administration tasks include maintaining backups, monitoring storage space consumption, detecting crashes between processes, and fixing data problems that prevent applications’ normal operation.
The person who has the database skills to take care of these tasks is the database administrator, or DBA – when there is one. In very small organizations – or in development environments where the operation of the databases is not critical to the business – the responsibility for database maintenance may fall on the database modeler. Therefore, you should have some knowledge that will allow you to take over from the DBA in certain situations. However, under no circumstances should you accept the responsibility of administering a database in a production environment that supports business or mission-critical applications.
Administration tasks vary greatly depending on the database system and the infrastructure on which it is mounted. For example, the tasks of managing Microsoft SQL Server databases are very different from those of managing MySQL or Oracle databases. And managing a server that you have running locally on your notebook is very different from managing one that runs in the Cloud.
I don’t recommend dedicating a lot of effort to learning how to manage a particular database server, since you’ll deal with very different databases and environments throughout your career. It won't do you much good to specialize in just one.
Concurrency and Transaction Management
Concurrent access to a database can cause problems in applications when several users try to access the same resource at the same time. We might think that, as designers, this is none of our business and that it is the DBA's responsibility to deal with these problems. We may also think it’s the programmers’ fault for creating applications that allow them.
However, designers can do their part to minimize potential concurrency problems by designing schemes that avoid them.
Many concurrency problems occur when long and complex transactions are executed on a database; while the transaction is being processed, the tables involved are blocked for other processes that need them to read or write information. To avoid this kind of problem, the best thing you can do is to ensure that your designs comply at least up to the third normal form. Then it will be the programmer’s responsibility to think through the transactions correctly to avoid deadlocks.
But you can also use strategies that avoid concurrency, such as partitioning schemas or grouping tables according to the function that each one fulfills.
Let's imagine a database for an e-commerce site. You can place the master data tables for products, stock, and prices in one schema and orders and sales in another, together with views or read-only replicas of the tables from the first schema. This helps avoid errors when executing transactions that update the master data.
Database Design Tools
If you understand the relational model, entity-relationship diagrams, and normalization techniques, you can design databases with no other tool than pencil and paper. However, your performance will be greatly enhanced if you use an intelligent tool, especially one that can automate certain design tasks like the relocating or modifying objects in a diagram, detecting design errors, generating SQL scripts to create or update a database, and reverse-engineering an existing database design.
Mastering a specialized tool such as the Vertabelo platform will allow you to work much faster. And it will allow you to stand out from other designers who do not have this help.
SQL and Programming
We would all like to be able to deliver a database design, say proudly “My work here is done” and leave for a well-deserved vacation. But usually, that ideal situation never happens. Once you’ve finished your design, the application programmers will need to use it, and they’ll need to have you around to help them.
One way you should continue to assist in a development project is to write views, triggers, stored procedures, and other things in SQL (Structured Query Language) to solve particular application needs. Another way is to supervise the programming tasks that are carried out with something called Object-Relational Mapping (ORM).
ORMs are intended to abstract data access from a particular RDBMS. The good side of this is that programmers don’t have to worry about the specifics of the database they will be using – in other words, they don’t need to care if the RDBMS is MySQL, Oracle, IBM DB2, MS SQL Server, or something else.
The downside of ORMs is that the database design objects – tables, attributes, and relationships – are defined in the code of a high-level programming language like Java, Python, R, or C#. In other words, they’re where we database designers cannot see them.
The solution to this problem lies in Agile development methodologies and their collaborative philosophy. These promote designers and programmers working together over the course of a project, so you’ll want to maintain a good relationship with the programmers. You should be willing to sit next to them, look at the programming code, and jointly write the definitions of the data objects.
Soft Skills Database Designers Should Have
In addition to the theoretical and technical knowledge specific to database design, a designer should ideally have other skills known as ‘soft skills’. These skills – like being a good communicator and understanding the business’s vision for the final product – impact the success of your work indirectly. The ones I mention below are just a few examples, but there are many more soft skills that are greatly valued by potential employers.
Business Vision
When you design a database, you are representing the reality of a business in terms of interrelated data objects. We’ve seen that the design must meet standardization conditions and that it must avoid inconsistencies, anomalies, and concurrency problems. But just as important – or perhaps more so – is that the design is aligned with the business vision of whoever is paying your salary.
Understanding the business vision will allow you to better grasp the importance of each requirement and guide your decisions so that your designs are better aligned with the organization’s objectives.
Here’s a simple example of how understanding the business vision will shape your work. You may think that using a surrogate key in a table clutters your design, adding an unnecessary and annoying element. But by omitting the surrogate key, you may slow queries on that table because an INTEGER-type key could give superior performance. If the business vision is to provide fast queries, then the surrogate key is the way to go.
Communication Skills
It’s not enough to make great designs. You must also be able to explain why your design works. The way to do this is to know how to present it, both discursively (spoken or written) and visually.
Make a list of the strengths of your design so that they stand out. Think about the decisions you made to create it and write down the reasons for those decisions. Be prepared to defend your decisions and your design to those who don’t understand it or who want to change it, making it imperfect or flawed.
But you must also be willing to accept constructive criticism and consider points of view that are different from your own. Sometimes a programmer may spot a problem you didn’t see and give you good advice. Don’t dismiss your coworkers, thinking they don’t have database knowledge.
Interpersonal Skills
I have commented above on the advantages of having a good rapport with programmers. No matter how advanced you are in your area of expertise, it’s important that you maintain an attitude of companionship with all team members, whether it is a tester who detected a defect that forces you to rethink part of your design or a project manager who needs you to accomplish a task by a certain date. In short, you must be a team player. Nobody wants to have prima donnas on their team who feel irreplaceable and want to impose their rules.
It may happen that you are not the only database designer in a development team. Maybe you must lead a subgroup of your colleagues. To do so, you must demonstrate leadership skills and act as a project manager, ensuring that the team of database designers meets its objectives and stays motivated.
How to Learn Database Design Skills
You can acquire the skills you need to be a database designer from university degrees, courses, books, and specialized articles. The advantage of university courses is that they give you all the knowledge you need and endorse that knowledge with a recognized degree. The disadvantage is that they require a large investment of time and money.
If you prefer to learn on your own by reading books and articles, you will save time and money – but you will need a guide to lead you through the essential topics and to evaluate your knowledge. And you’ll have to demonstrate your knowledge in a practical way, since you won’t have a degree to back it up.
In any case, whether you learn by taking courses or reading, that knowledge will only serve as a foundation. You will learn the most by creating models, facing real problems, and observing the actions of your colleagues and coworkers.
