

There’s a lot to keep in mind when you’re designing a database, and very few of us can remember every valuable tip and trick we’ve learned. So, let’s take a look at some online resources that feature database design tips and best practices. As we go, I’ll share my own opinions on the ideas presented, based on my experience in database design.
Obviously, this article is not an exhaustive list, but I’ve tried to review and comment on a cross section of sources. Hopefully, you’ll find the information that best suits your needs and goals.
As a side note, I was surprised to find that many articles related to database design practices had very few examples; the online resources that I reviewed for the article on errors and mistakes had a higher percentage of them. This lack is a drawback, because examples are extremely important for getting the point across.
Database Tips for Experienced Designers
First, let’s start with sources featuring advanced database design tips and best practices. These are for designers who are already working in data modeling and have been for some time. Some articles are aimed at a more intermediate level, but if they discuss advanced concepts, I’ve included them in this list.
Database Guidelines (RDBMS/SQL)
by Steve Djajasaputra | SOA, Java, Software Development – BlogSpot | January 16, 2013
This article from Mr. Djajasaputra is quite impressive: he lists numerous tips for the schema, indexes, and views; he also provides quite a detailed naming convention. And his tips go on (and on). The breadth is impressive, but there are almost no examples. Some of his points might be considered debatable, but overall this is a very solid presentation.
In particular, I was impressed that he gives a precise rule about using natural versus artificial (i.e., surrogate or generated) primary keys. He keeps this nice and simple, specifying that we should prefer a natural key because it’s meaningful. He also provides guidelines for the best use of an artificial key –specifically, when the natural key is not unique or when you need to change the value of the natural key. In his own words:
As his list of tips is so long, I can’t imagine remembering them all. But each section could be referenced when you are working on database design, performance, stored procedures, and versioning. There is also a section on Oracle-specific points that would be useful if you are working with or planning to support Oracle.
All in all, this is a very worthwhile and comprehensive resource.
9 Tips for Better Database Design
by Jeffrey Edison | Vertabelo Blog | September 22, 2015
I will indulge in a little self-promotion here.
This article of 9 tips for better database design is based on my experience as a designer and architect. I also found additional insights from researching others’ best practices for database design.
My list represents some of the main issues that can happen when working with data models. I organized the tips in the order they occur during the project lifecycle (rather than by importance or how often they arise) since that would be most useful, at least in my view. Readers can follow this checklist of best practices through the lifecycle of a project.
From the article:
By paying attention to these tips, I have found that databases become better designed and more robust. While none of these activities will take an enormous amount of time, each can have an enormous impact on the quality of your data model.
I hope that my list of tips is useful for intermediate and advanced designers.
20 Database Design Best Practices
by Cagdas Basaraner | Code Balance – BlogSpot | July 24, 2011
Mr. Basaraner presents us with an interesting list of 20 database design best practices. I would have preferred it if he had grouped some of these; for example, the first four items could all be covered under “Use Good Naming Conventions”.
In addition, he states that using a synthetic, generated (integer) ID as the primary key of all tables is a best practice. In fact, this is still a debated subject, with arguments for and against. Some of his best practices are quite generic, like “For … mission critic [sic] database systems, use disaster recovery and security service …” I do not disagree with this point, but it is very high-level.
On the plus side, this article was one of the few that mention using an object-relational mapping (ORM) framework. Some commenters disagreed with how the tip was worded, but at least using an ORM framework is mentioned:
Still, this list could have been improved. It should clearly identify points that are specific to only some database management systems (for example, SQL Server). Precise statistics regarding performance, heuristics, or the importance of spending time on design rather than on maintenance and re-design would have been good. More examples were needed as well, but that is an issue for most of these articles.
If you are working with SQL Server, considering using an ORM framework, or needing a bulleted list of tips rather than a long and detailed article, then this piece is for you.
(Note: this article also appeared on several other sites, including CodeBuild, Java Code Geeks, and DZone.)
Database Design Essentials. 10 Things You Absolutely Need to Do
by Michelle A. Poolet | SQL Server Pro | March 1, 2011
A portion of Ms. Poolet’s tips are quite standard and can be found in many other resources, but there are a few rather uncommon points as well. Among her generic points, she promotes the use of sub-types and super-types (with which I strongly agree) as this mirrors object-oriented design and can be easily understood by developers. From her article:
Don’t be afraid to include supertype and subtype entities in your design in the CDM and onward. The subtypes represent classifications or categories of the supertype… Entities are represented as subtypes when it takes more than a single word or phrase to categorize the entity.
If a category has a life of its own, with separate attributes that describe how the category looks and behaves and separate relationships with other entities, then it’s time to invoke the supertype/subtype structure. Failure to do so will inhibit a complete understanding of the data and the business rules that drive data collection.
Some of her comments make specific reference to MS SQL Server even if the comments are actually generic issues. One main point that Ms. Poolet makes is very SQL Server-specific: “Store code that touches a database’s data as a stored procedure”.
This is fine if you are only planning on supporting a single database management system, such as SQL Server. But for portable implementations, this would not be good advice. Generally, I design for portability to at least two management systems with different stored procedure language support. Therefore, I would avoid this practice.
This article is most useful for people developing for SQL Server and focusing on the American market (rather than an international system). As an American living abroad, though, I found that some of her examples are a bit too “USA-centric”. For example, a non-American might not understand what a Zip+4 domain is and therefore would have no understanding of why a this domain should have a NOT NULL characteristic.
To illustrate this, I made a data model for both American non-American addresses. We’ll assume that our data model might require entities to be linked to more than one address: for example, one for billing, one for shipping. The first address would be associated with a payment method; in this case, the address would be used to verify your right to authorize that payment. The shipping address, obviously, is where the order will be delivered.
Let’s create an American address as part of a customer-order database model. (Note: this is not a complete model, but an example of storing product orders.)
Wise Coders Solutions recommends defining separate fields for house numbers and street names and setting these fields as NOT NULL; this would disallow any address that does not have a house number and a street name. But what about people who use PO boxes? Their addresses are usually written as “PO Box 123”. Should we force them to put the PO Box number as the house number and “PO Box” as the street name? I don’t think so.
Instead, we will use a form with “Address Line 1” and “Address Line 2”. Several people have argued against using numbers in field names, but to me this is a rather obvious solution. Also, I’ve defined maximum field lengths (35 and 70 characters) that are typical in international payments.
Notice that the US and the non-US designs both have a field for regions within a country, but the US design requires that a 2-character state abbreviation is included. Also, notice that the US design does not allow for addresses in other countries.
If you have concerns about the global usage of your database, you need to think globally during the design phase. Are our databases prepared for the multi-national usage of our applications?
Lessons Learned from Poor Data Warehouse Design
by Michelle A. Poolet | SQL Server Pro | June 15, 2009
This article takes a look at the Data Warehouse (DWH) and some of its design and implementation issues. There is a slight focus on SQL Server, but it’s a fairly orthodox overview of designing for data warehousing and business intelligence. Having buy-in and creating user-friendly interfaces may not be the most useful of tips, but I don’t disagree with them – I just don’t think they are part of DWH design.
Ms. Poolet states that the extract-transform-load (ETL) process should perform data quality checks and potentially “clean” data until there is an acceptable standard of data quality. In my opinion, this risks creating a data warehouse that does not properly mirror the information extracted from the source system. Data cleaning should be performed in the source systems. ETL should only transform data so that it can be loaded into the data warehouse.
On a positive note, the recommendation of recycling or creating reusable ETL routines is highly relevant. In addition, I agree with Ms. Poolet about scalability. Her comments about risk management and compliance, particularly the Sarbanes-Oxley Act, seem quite specific; I assume that these come from her area of business.
Finally, she has a nice checklist of points relating to dimensions, fact tables, and schema choices during OLAP (online analytical processing) design. These appear to be very relevant during the database design process. I would have liked this list to be longer, with more details or examples, but I was happy that these practical tips were included.
11 Important Database Designing Rules Which I Follow
by Shivprasad Koirala | Code Project | February 25, 2014
I really like the sensible and clear advice at the beginning of this article. Concepts like ‘consider the nature of the application’ and ‘break your data into logical pieces’ are spot on. These are important helps when creating your data model. As Mr. Koirala says:
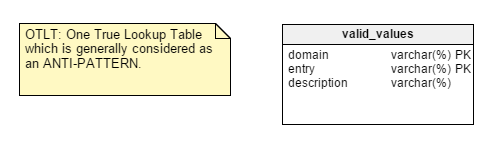
However, there are a couple of points that leave me unconvinced. For example, take centralizing Name-Value pairs into a single table. This One True Lookup Table (OTLT) design is debated, but it is generally considered a bad practice or at least anti-pattern in design. I side with the anti-OTLT group; these tables introduce numerous issues. We might employ the software development analogy of using a single enumerator to represent all possible values of all possible constants as an equivalent to this practice.
To remind you, the OTLT table typically looks something like this, with entries from multiple domains thrown into the same table. I agree with anti-OTLT group; these tables introduce numerous issues.
In addition, some points seem a bit esoteric, like “watch for data separated by separators”. While this is a valid point, it is not one that I usually think of when creating a new data model.
Mr. Koirala has a couple of OLAP design items that are generally not mentioned in other best practice lists. His inclusion of a dimension and fact design may be useful, but it could also be dangerous for newbie designers.
This article is interesting if you are moving from beginning into more advanced data modeling. It will help you consider the analytic versus transactional nature of your future models.
Big Data: Five Simple Database Design Performance Tips
by Dave Beulke | davebeulke.com | March 19, 2013
Mr. Beulke’s article looks at performance-focused design tips. He shows how to check for proper normalization: neither too much nor too little. (Over-normalization will have a negative impact on database performance.)
Also, using natural business keys rather than generated primary keys is sound advice when you want to avoid translating from a business key to a generated row ID for each database access.
Using proper naming standards and column types is also good advice. The point about the overuse of nullable columns is sound: creating all columns as nullable is a mistake, but defining a column as nullable may be required for a particular business function. In the author’s own words:
Mr. Beulke’s tips are all very solid, even if somewhat unoriginal. I would’ve liked more Big Data items – that is, after all, the title of the article. In the end, I felt that the article lacked both depth and breadth, and had no examples to clarify the points. However, he does offer valuable advice related to normalization and natural keys.
10 Database Design Best Practices
by Ann All | Enterprise Apps Today | July 15, 2014
Ten Database Design Best Practices is actually presented as a series of slides. Ms. All includes information from seasoned developers, such as Michael Blaha. He encourages the reuse of your best practices and patterns. These are understood and proven, and in that respect preferable to data models that must be created from scratch. From Ms. All’s article:
This is a short slide show that data model designers can quickly scan through and glean the tips that resonate with them. For me, the re-use tip is one of my favorites.
Database Best Practices
by Cunningham & Cunningham, Inc.
These best practices started off just fine, but then got into some sticky issues. I am not convinced the advice offered is always on point.
On the positive side, there are very nice descriptions of controversial “best practices” like always using auto-generated surrogate keys and using or avoiding stored procedures. As an example:
(Author’s Note: I have not been able to find this “previous author” when searching for these two sentences on Google.)
And a link to a summary article about the main arguments on each side of the Auto Keys versus Domain Keys debate is provided.
On the other hand, I found the tips to “divide operating system, data, and logging onto different physical disks” and “use RAID” a bit arcane. Don’t get me wrong – this is probably sound advice in some circumstances, but I would not include it in my Top 20 list.
Database Design Tips
by Wise Coders
There are a few unique and interesting tips in this collection, such as a recommendation to close transactions as soon as possible.
However, I do not completely agree with all of the design tips here. For example:
This is controversial, to say the least – other sources recommend against employing “secret codes” like this. Instead, use a separate table to store these status codes.
In addition, the statistics associated with performance hints are questionable, and there are no examples in the article.
On a positive note, this is a nice short list of tips that should be accessible to intermediate database modelers.
Resources for Beginning Database Designers
Now let’s examine a few articles for those who are just getting started in database design.
The Basics of Good Database Design in Web Development
by Kayla Knight | Onextrapixel.com | March 17, 2011
Here we get a bit more advanced, with advice ranging from functionality to modelling tools.
Ms. Knight walks us through an introduction to database design. Her article is interesting because it emphasizes databases for web development. Even so, her points are fairly universal and can be applied to database design in many situations.
The article starts off with asking us to think broadly about functionality, not just the database:
From there, Ms. Knight takes the reader into database design tools and the steps involved in the process. Her article gives examples and links to other resources.
I think that this article would be a great introduction for beginning database designers, and it should work well with the Geek Girl’s series.
Exploring Database Design Tips
by Doug Lowe | For Dummies
Mr. Lowe’s “Dummies” list is a broad series of basic design tips. You can find many of these elsewhere, but it’s useful to have them in one place. You won’t find anything unique or highly controversial, except for a recommendation to use stored procedures. I always question this strong statement, as I am very concerned about data model portability for multiple DBM systems.
Here is one of Mr. Lowe’s common-sense tips:
These recommendations are most appropriate when working with SQL Server.
Five Simple Database Design Tips
by Lamont Adams | TechRepublic | June 25, 2001
The key word for this resource is “simple”. You can find this information, with more explanation and examples, in other articles.
However, Mr. Adams’ advice to “Take the user’s keys away” is an interesting point, rarely mentioned in other places. He continues:
Mr. Adams’ meaning is that you should consider the user’s potential requirement to edit fields when deciding which fields to use as keys. I would have liked more explanation regarding alternatives, such as synthetic/generated keys, but the concept is good.
I did disagree with the final point. He recommends a “fudge factor” for each table you design:
In my mind, this is basically “adding a couple of extra text fields to the end.” This seems to contradict some of Mr. Adams’ other tips, specifically those regarding understanding business needs and using meaningful names. These extra fudge fields would just be called something like “extra1”, or “extra2”. What is their business need? And how are these meaningful names? While I like most of his design tips, this “fudge factor” is not something that I adhere to.
Database Design: Honorable Mentions
Obviously, there are other articles that describe database design tips and best practices. You can find additional material in the following links:
Relational Database Design: A Best Practices Primer | by Digital Ethos | December 24, 2012
Best Practices for Database Schema Design (Beginners) | by Jim Murphy | March 28, 2011
IT Best Practices: Database Design | by the University of Nebraska–Lincoln
Online Database Design Resources: Where Would You Go?
As mentioned, this list is definitely not meant to be an exhaustive examination of every database design article on the Internet. Rather, we have identified several articles that we think are useful or that have a particular focus that you may find helpful.
Please feel free to recommend additional articles.
