

How does all that public opinion data get stored? We check out an opinion poll data model.
Everyone wants to know what the public thinks, from politicians and companies to individuals who want to know what others think on a certain topic. This kind of job is usually performed by agencies that specialize in that type of research.
Today, we’ll take a look at a data model such an agency could use to store all relevant poll data, from questions and predefined answers to the actual feedback. This data would be later used to create various reports. So, let’s start.
Idea
Polls can be created anywhere. They could be well-planned and include a representative sample of the public (based on demographics). Or you could do them on the spot, e.g. if you want to predict election results based on a sample (like an exit poll), you’d probably ask people at the polling station how they voted.
On the other hand, if you want to create the same poll prior to the election, you’d probably select a sample and contact individuals by phone or in person. Usually, there are only a few questions for this type of poll – some to cover demographics, and others to cover what we’re really interested in.
Polls can also be much more complex, e.g. if you want to know the public opinion on a certain product, covering everything from its performance to its packaging.
In this article, I won’t discuss how to select a sample set of people; rather, I’ll focus on the poll itself, its questions, and the responses.
Data Model
Public opinion agency data model
The model consists of three subject areas:
PollsQuestions & AnswersResult
We’ll describe each subject area in the order it’s listed.
Polls
Before we start asking questions, we need to define what we’re interested in. We’ll define polls and questionnaires in this section, then add questions and answers in the next one.
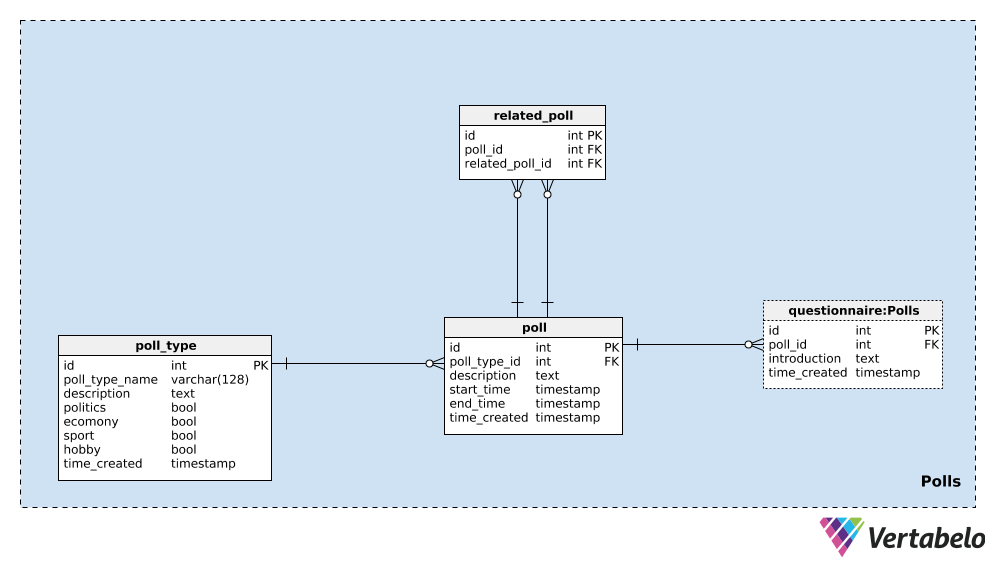
We’ll start with the poll_type dictionary. We can expect that we’ll mostly repeat polls of the same type. The most common type is probably election polls, but we want to be able to add new poll types along the way. For each poll type, we’ll store a UNIQUE poll_type_name and use the description attribute to provide additional details.
Four flags – politics, economy, sport, and hobby – are used to denote the type of poll. A poll could cover one or more of those topics; if needed, we could split these categories into a separate dictionary and have a many-to-many relationship between that dictionary and the poll_type table.
The last attribute in this table is time_created. It denotes the moment when a row is inserted into this table.
The next thing we need to do is define a single poll. This is a single instance, e.g. “2020 United States presidential election – April 2020 poll”. For each poll, we’ll store the following details:
poll_type_id– A reference to thepoll_type.description– All details related to this poll, in textual format.start_timeandend_time– The defined start and end times, during which this poll is taken.time_created– The actual moment when this poll was created.
Polls can be related to each other. In the example of the “2020 United States presidential election – April 2020 poll”, we could do the same poll the next month to see the most current opinions. We would call this “2020 United States presidential election – May 2020 poll”. These two polls are related because their results show trends. To establish that relationship, we’ll use the related_poll table in our model. It contains only the UNIQUE pair of poll_id – related_poll_id, denoting the poll and its predecessor.
Note that we could use this table to store all polls that are related in any manner, not just predecessors/successors. If we wanted to define different relationships, we’d need to add another dictionary – but we won’t go that way in this article.
The last table in this subject area is the questionnaire table. In most cases, each poll will have exactly one questionnaire, but I want to leave the option that we could have more than one if needed. Therefore, I’ve used a separate table. In this table, we’ll store only the ID of the related poll (poll_id), an introduction describing that questionnaire, and the timestamp when the record was inserted (time_created).
Questions & Answers
Now we’re ready to create all the questionnaire details. We can also list all the questions we want to ask as well as all predefined answers.
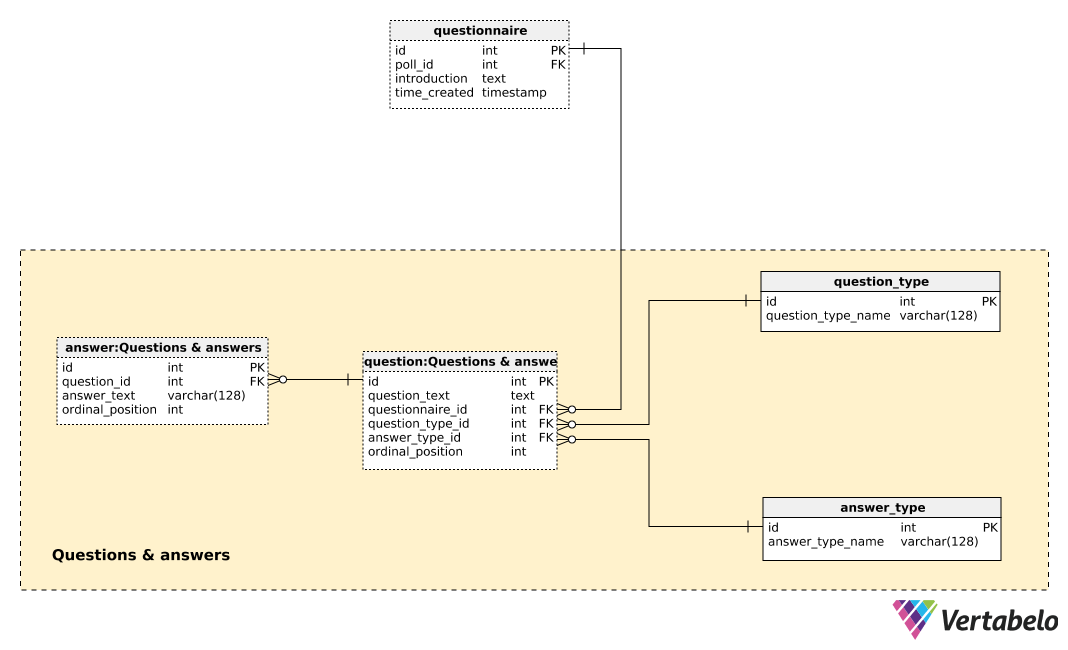
The central table in this subject area is the question table. Each question is defined by the following details:
question_text– A text that will be displayed to each individual being polled.questionnaire_id– A reference denoting the questionnaire of this question.question_type_id– A reference denoting thequestion_type, which is UNIQUELY denoted by thequestion_type_name. These are basically categories, e.g. “demographics”, “opinion”, “control”, etc. These would allow us to separate demographic and opinion questions and find a correlation between them.answer_type_id– A reference to the type of answer that will be used for this question. Eachanswer_typeis UNIQUELY defined by theanswer_type_nameand denotes how the answer is displayed. Some expected types are “open”, “list”, “checkbox”, and “multiple”.ordinal_position– This value denotes the position of this question in the questionnaire. Together with thequestionnaire_id, it forms the alternate key of this table.
A list of all predefined answers is stored in the answer table. If the question type is not open (i.e. text will not be entered by the individual), we’ll have a set of predefined answers. For each answer, we’ll define the question it belongs to (question_id), the answer_text, and the ordinal_position of that answer inside that question. Once more, a UNIQUE pair – this time question_id – ordinal_position – forms the alternate key of this table.
Result
In the previous two subject areas, we’ve defined everything we need to create the poll and start asking questions. Now we need to define a data structure to store actual answers.
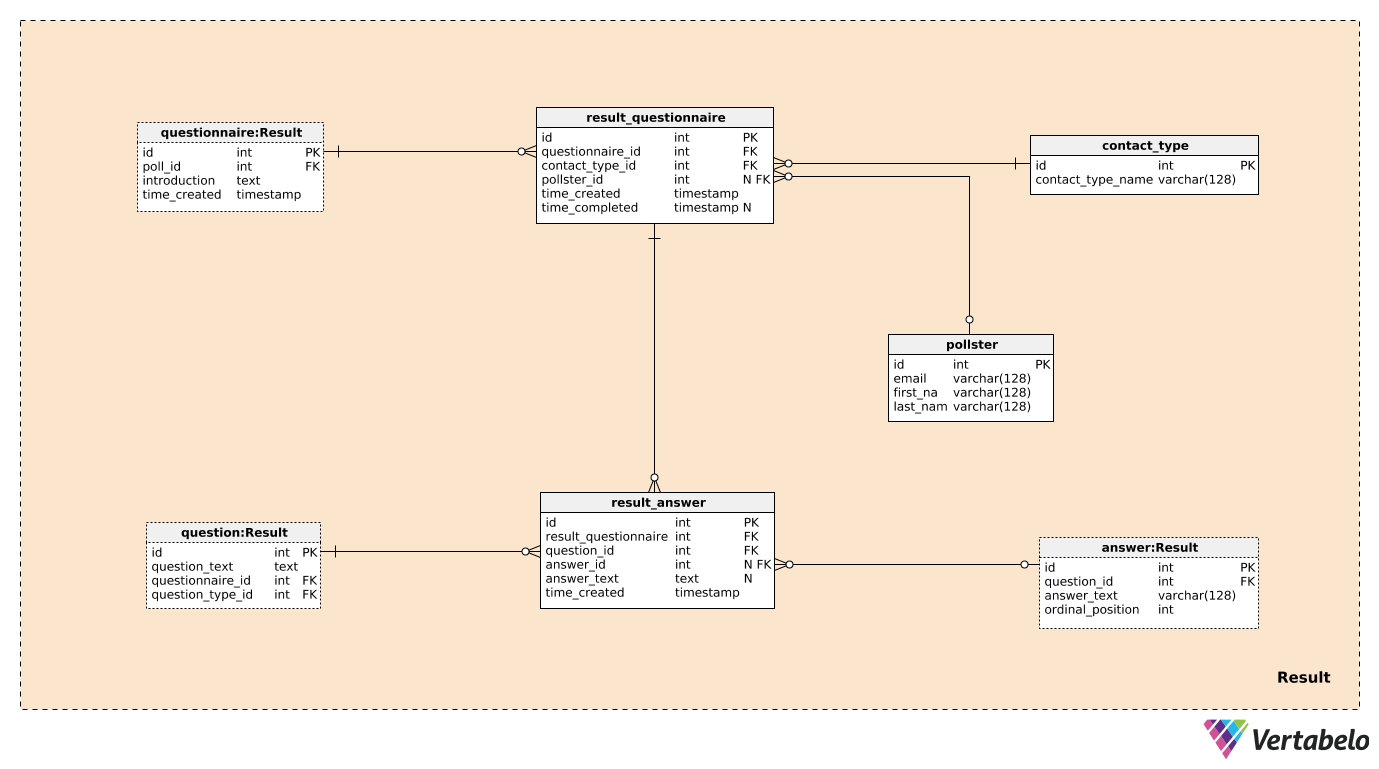
Three out of the seven tables in the Result subject area were previously mentioned and described. These are questionnaire, question, and answer. The remaining four tables are used to store what we’re really interested in.
We’ll create one record in the result_questionnaire table for each individual taking part in the poll. The questionnaire_id provid esus with all the information about the relevant poll. The contact_type_id is a reference to the contact_type dictionary. Values in this table describe the way we’ve interacted with this person. These values are UNIQUELY defined by the contact_type_name value and could be something like “phone”, “in-person”, “email”, “webform”, etc.
The pollster_id attribute is a reference to the pollster table, which provides the info of who conducted that actual poll. For each pollster, we’ll store only their UNIQUE email and their first_name and last_name. The time_created attribute denotes the actual time when this record was created, while the time_completed will be set at the moment this survey is completed. (Until that time, it will be NULL).
The last table in the model is the result_answer table. As its name suggests, this is where we’ll store the actual responses we got from survey-takers. For each record in this table, we’ll have:
result_questionnaire_id– A reference to the relevant questionnaire.question_id– A reference denoting the question answered by this response.answer_id– A reference to the answer that was used to reply to this question. This attribute will contain a NULL value when the question is of an “open” type (because there were no predefined answers to choose from).answer_text– The text that was inserted to answer this question. This attribute will contain a value when the question was “open”; in all other cases, it will be NULL.time_created– The actual time when this answer was inserted into our system.
Possible Improvements
So far, we’ve covered how we could store poll data. We haven’t discussed what we would do with the data after the poll is closed. We can expect that we won’t need the old data in the future, at least not in our operational database. Therefore, we could do two things:
- Store a poll summary in a separate table in the operational database. This would keep such information at our disposal if we wanted to see what happened with a similar poll.
- Store all poll data in a backup database that had the same structure as the operational database. This would allow us to access the details when we needed them.
We could also create a data warehouse to store poll results, but that wouldn’t be necessary if we had already done the tasks described in the two bullet points.
What Do You Think of Our Opinion Poll Data Model?
We would like to hear your opinion of what we could change to improve the opinion poll data model. Do you have industry experience? Do you think we missed something? Would you add or remove something? Looking forward to hearing your opinions.
