

Bus and train travel hubs are full of activity: the crowd, the rush, the lines, the race to the platform or terminal. Clearly, such places require a lot of organization! In this article, we’ll describe a database model that could keep a transport hub organized.
And that’s not easy. There are many parameters to account for: lines, stations, passengers, tickets, compositions (i.e. buses or trains), and the number of available seats on any given trip. Plus, before selling tickets or doing any similar action, we need to be sure that the result is the desired one.
So let’s look at the problems transport hubs face as well the data model to solve them.
Three Perspectives on Transport Hubs
Before we start the technical stuff, we’ll consider the issues facing travel hubs from different perspectives. For each one, we’ll explain what actions are required.
-
The Passenger
As a passenger, we want to get from point A to point B. We know our departure station and our arrival station as well as the travel date. We may also have to get to the arrival station at a certain time.
Passengers want to buy a ticket from station A to station B, for a certain date, economically but without sacrificing comfort. They’ll need to search all operators that go from station A to station B for price, departure and arrival times, number of available seats, etc. They can do this (plus buy tickets) at a station or online. In the first case, passengers get their info on the spot; in the second, they’ll use a searchable web form that shows which trips meet their criteria and allows them to buy a ticket.
-
The Employee
For station employees, the perspective is a little different. When a customer asks a question – either for information, a ticket, or both – employees use the same web app or a similar system. They enter search parameters and communicate the results to the customer and hopefully sell the a ticket. When a sale is made, a record will be stored that contains trip info and the ID of the employee who made the sale.
-
The Management
The hub manager needs to have more insight and control. They should be able to add new operators, lines, or destinations; define schedules; and generate reports. Whatever data the manager adds to the database is used by other employees, primarily to filter results and to sell tickets.
On the other hand, a manager will mostly relate sales data with other parameters in the system, particularly when creating reports. They’ll use many different forms, and their actions will change the data in various database tables. We’ll plan for this in our model, which you can see in the next section.
The Data Model
Our data model consists of four main subject areas:
LocationsLines and schedulesCompositionsTickets
There is one table that is outside all the subject areas: the operator table. Please note that the schedule table is used twice in our model. The original is in the Lines and schedules subject area; a copy is outside any subject area and is used to avoid relations overlapping in the model.
I’ll start with the Locations subject area because that is what travel is all about. Then we’ll define schedules in Lines and schedules and bus and trains compositions in Compositions. Finally, we’ll explain the Tickets subject area, which enables us make and tracks sales.
Section 1: Locations
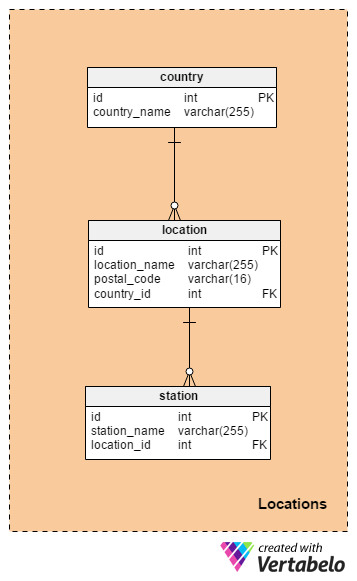
The Locations subject area consists of three tables that are used to define all possible locations: all stations, all departure and arrival points, and the operators’ locations.
The country table is a simple dictionary that lists all countries that could be assigned to an operator or a location. The only attribute in this table (besides the primary key) is country_name, which can contain only UNIQUE values.
In the location table, we’ll store all the towns and villages where the bus/train will stop. For each location, we’ll have its name, postal code, and country. All attributes in this table are mandatory.
The last table in this section is the station table. We’ll store every station’s name and location here. Notice that a location can have more than one station – e.g. a city such as Paris has many stations.
Section 2: Lines and Schedules
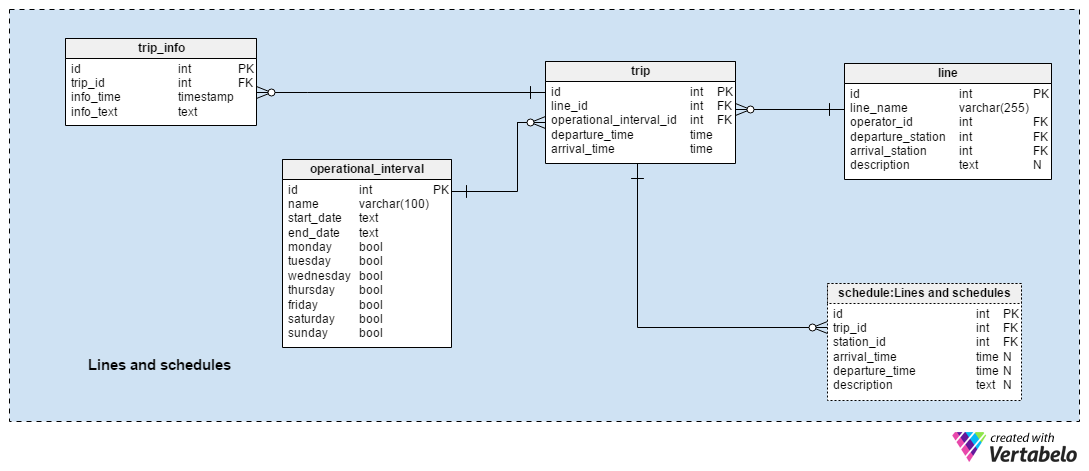
After we have defined locations and stations we’ll need to define all lines that operate from our hub. For each line, we need to know every station on its route, plus their departure and arrival time. We also need to know the line's schedule, which can change.
A list of all lines operating out of our hub is stored in the line table. We know each line's starting point – the departure_station – and its end point – the arrival_station. Lines also have an operator_id attribute that stores the name of the transport service that operates that line. Each operator may define their own unique designations for a line; these are stored in the line_name attribute. The line_name – operator_id pair forms the UNIQUE key of the table. Any additional description is stored in the description
Before we move on, there are a couple things to know about lines and operators. A line operator shouldn’t use same designation twice, but two different operators might. Also, the same service could operate on the same line several times a day and the designation would still be the same.
The days a line operates can change by season and for different days of the week (e.g. it operates more often on weekdays than on weekends). This information is usually recurring. Obviously, we need to relate these different schedules with the days when they are valid. We’ll store that information in the operational_interval table. The attributes in this table are:
name– This designates a period of time, e.g. "Fall 2016, weekends only", or "Summer 2016, weekdays".start_dateandend_date– These define interval dates during the year. Both these attributes are TEXT data types because the year is not included. This provides us with the flexibility to write these days in any format.- The days in the table (i.e. “Monday”, “Tuesday”, etc) are all Boolean data types. These attributes just show if a line operates on that day of the week.
Each record in the trip table is related to a record in the operational_interval table and a record in the line table. From these relations, we’ll know:
- the departure point
- the arrival station
- if the line operates on a certain day or not
For each record in the trip table, we’ll define only the departure_time and the arrival_time. We’ll also state if that line operates between the same departure and arrival points more than once a day. We can add records too that denote when that same line is on its way back to the departure station.
The three tables mentioned so far provide us with full information about departure and arrival stations and times and the days when each line operates.
A list of all stations on a line route is stored in the schedule table. Notice that the table is actually named schedule: Lines and schedules because a copy of this table is used elsewhere in the model. The attributes in this table are:
trip_id–This is the ID of the related record in thetriptable.station_id– This is the ID of the relevant station on a route.arrival_timeanddeparture_time– These are times when the bus/train arrives and departs from a station. Both can contain NULL values but only in two special cases: anarrival_timedoesn’t exist for the first station on the route, while adeparture_timedoesn’t exist for the last station on the route.description– This field contains an additional description, if needed e.g. a platform where the bus or train picks up passengers.
Notice that we could insert the same route two or more times in the schedule table if the bus/train travels the same route multiple times in the same day. Also, a station could be on the same route more than once (e.g. if we have a circular route or if the route simply has to go through that station a few times).
The last table in this section is the trip_info table. This is where we’ll store all the non-structured information that helps define a trip's statuses. An example of what we’d store here is “train is 15 minutes late”. For each item, we’ll store its insert time and the related text. Notice that this information is related with the trip table. We can easily relate all previous and future data with trips rather than just specific schedule records.
Section 3: Compositions
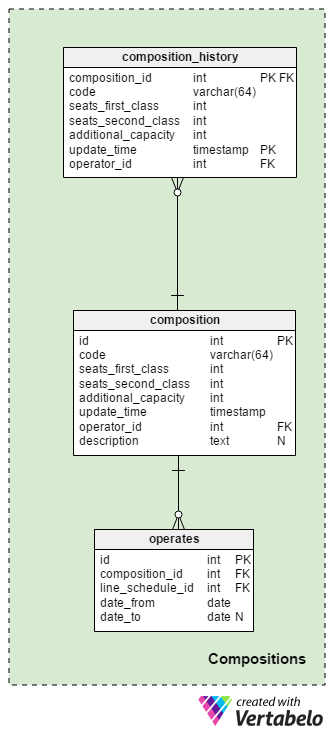
So far, we have defined locations and schedules. Now it’s time to describe the vehicles that operate on our lines, which might be composed of different parts. Thus, we call them compositions. In a bus hub, a composition is a single bus; in a train hub, it could well be a train with many cars. Have in mind that compositions can change over time.
All parameters that are relevant for each composition are stored in the composition table. Let’s take a look at the attributes:
code– This is a composition code that is unique to each operator.seats_first_classandseats_second_class– This stores the number of seats in first and second class, respectively.additional_capacity– This is the amount of additional seats or standing areas.update_time– This is when a composition record was inserted or most recently updated.operator_id– This is the ID of the operator that owns the composition. Together with thecodeattribute, it forms the UNIQUE key of this table.description– This is an additional description of the composition (e.g. manufacturer, production date, number of cars in a train composition), if needed.
When we insert or update a composition, we’ll store the same record in the composition_history table. This becomes important if the composition (and its number of seats) changes. When this happens - e.g. a railway company adds another car to an existing train - then the season schedule likewise changes. So I decided to go with the history table here. The attributes' names and purposes are the same as the related ones in the composition table.
The last table in this section is the operates table. For each composition, we’ll define a time period (date_from to date_end) when it operates on the related line (trip_id).
Section 4: Tickets
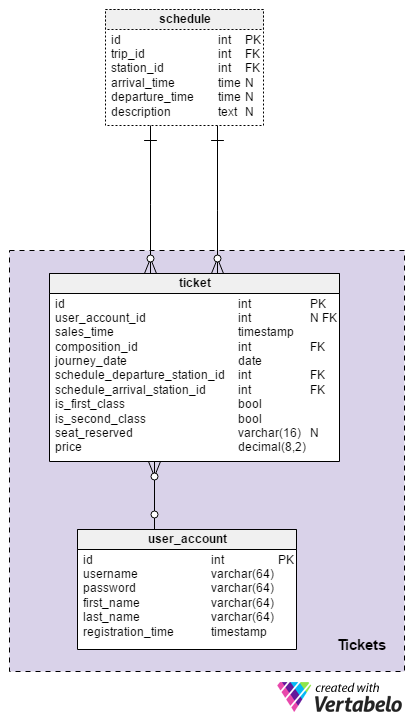
In this section, we’ll relate lines and compositions with ticket sales. Notice that the schedule table used here is really copy of the schedule table from the Lines and schedules subject area. We're using a copy to simplify the model and reduce relations overlapping.
The user_account table is a simple catalog that stores all the employees who sell tickets. All of the attributes are self-explanatory, and the username must contain only UNIQUE values.
Actual ticket sales are stored in the ticket table. The table is much easier to understand once we describe its attributes:
user_account_id– This is the ID of the user who made that sales. Notice that this attribute can contain NULL values, for instances when a ticket is bought online.sales_time– This is when that sale was completedcomposition_id– This is the ID of the composition involved in the sale.journey_date– This is the date when the ticket is validschedule_departure_station_idandschedule_arrival_station_id– These are the starting and ending points of the journey. We could also find thecomposition_idfrom these attributes. Still, I would keepcomposition_idas a separate attribute to simplify finding relations between tickets and compositions. Probably the query that checks the number of sold first and second class tickets for a specific composition will be run frequently. This setup would make this much easier.is_first_classandis_second_class– These fields denote if the ticket sold is for a first-class or a second-class seat. Only one can be set at a time. Before we make a sale for any class we should check the number of tickets sold so far and compare it with a number of available seats in thecompositiontable.seat_reserved– This is a designation for a reserved seat, if any.price– This is the ticket price.
It’s important to note that we can’t sell tickets for a composition that is completely full. On the other hand, if a passenger wants to buy a first-class ticket and none are available, maybe we could offer them a second-class tickets or tickets for additional seats. Both of these situations require SQL queries that will check departure and arrival stations and all stations on that line. If another passenger is traveling from the departure station to a point a couple stops down the line, their seat will become free for the remainder of the trip. We should have that information available.

We haven’t mentioned the operator dictionary yet. It’s pretty simple - it uniquely defines the operator by operator_name and country_id. The “headquarters” attribute is a text description where the operator's headquarters is located. We could add more operator-related data, but there is no need to do it for this model.
What Would You Add to This Transport Hub Data Model?
To run a transport hub, we need to have actual and accurate schedules. With this model, we can manage lines and stations on various routes, change schedules, add compositions and relate them with lines, and sell tickets. We can do this for the hubs’s location, but we can also sell tickets for any station on any route. These functionalities should be enough to perform all required checks and generate reports. But what could we add or change in this data model? We’ve stored the changes of compositions across time. We could do the same for the operational intervals. We could also add a reservation system. Please comment on what you would add and how you would improve this model!
