

If you ran a MOOC online learning platform like edX or Coursera, how would you keep it organized? In this article, we’ll look at a database model that would do the job.
You’ve probably heard of MOOC (Massive Open Online Course), a trending way to learn online. And if you haven’t, think of a MOOC program as university subjects with all materials, tests, and feedback available online. Two of the most popular online MOOC providers are Coursera (founded by Stanford University) and edX (founded by Massachusetts Institute of Technology and Harvard University). In collaboration with other universities and partners, they provide hundreds of courses to millions of learners all around the world.
In this article, we’ll discuss a simplified version of a database model we could use to run this type of service. First, let’s talk about how MOOCs actually work from a non-technical perspective.
How Do MOOC Platforms Work?
Personally, I’ve used Coursera and I was very satisfied with it. Therefore, my comments in this article pertain mostly to Coursera’s model, although I believe edX follows a similar pattern.
What is the business model?
The idea is very simple. Partners – primarily universities – create materials for online courses, which are usually based on their campus offerings. These materials can include video lectures, readings, quizzes, discussions, projects, online tests, and sometimes final assignments. Much of the material is video-based, so learners get that “human touch”. I enjoyed some courses not only because of what was taught but also because of the lecturers.
Students need to watch or read provided materials, complete assignments, answer quizzes, and take tests. Usually there are also one or more project assignments, and grades from all these assignments make up the final grade. If their final grade is above a certain score (e.g. 70%) students pass the course and receive a certificate. Some certificates are free; others require a relatively small payment. The same goes for the courses.
Related courses can be organized into larger entities known as specializations. Completing the specialization gives the student another certificate (as well as a more rounded skill set) and may be less expensive than completing each course separately.
All courses and specializations can have different sessions. Some will have new sessions each month, while others will have one new session every year. There are also courses that are available on demand.
Online certifications don’t yet carry the same weight as a university certificate, but they aspire to it. Some courses are already approved for college credit, and online study programs are also a reality now.
How many partners, courses, and students are there?
The simple answer is “a lot”. Courses are measured in thousands, partners in hundreds, and students in millions – from almost any country in the world.
What changes can we expect for MOOCs?
The great thing about MOOCs is that they can quickly adapt to change. They are not limited by state or university regulations and don’t have to wait for approval. That is very important, especially for IT-related courses. Some courses and specializations won’t have new sessions: other new courses will appear, and existing courses will go through various updates.
The MOOC Database Model
I’ve split the MOOC data model into three subject areas:
Course detailsSpecialization detailsStudent participation
And there are three standalone tables:
institutionlecturerstudent
The standalone tables are used as data sources for various tables in the subject areas. Since the subject areas contain most of the logic, I’ll explain them first and then move to the standalone tables.
Courses and Materials
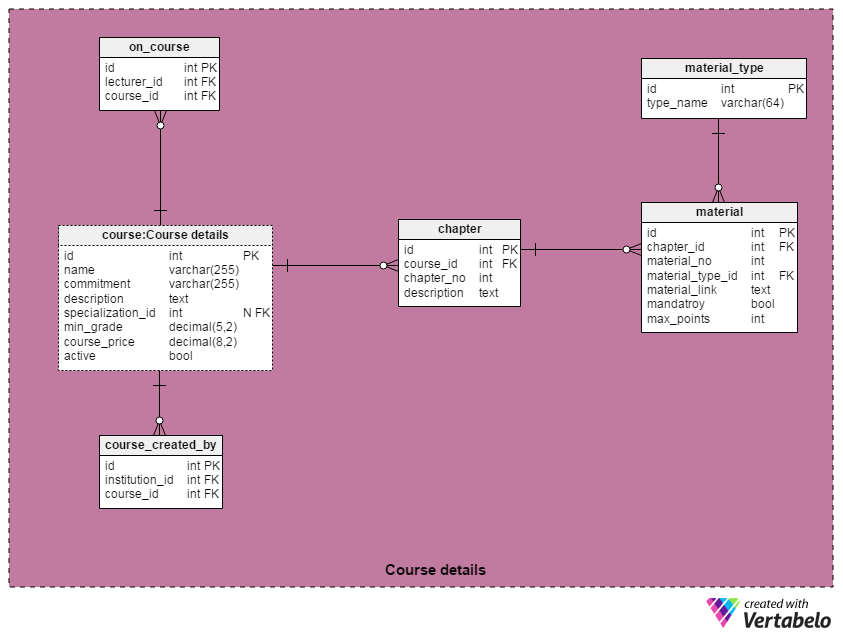
Although people are usually the most important part of any transaction, I’ll make an exception here. Without course materials, there would be no courses and therefore no interest in our MOOC platform. In “Course details”, I’ve grouped all the tables that describe courses, related institutions, partners, and materials.
The most important table in this section is the course table. The attributes are:
name– a unique course namecommitment– a text description of probable commitment, e.g. “5 weeks of study, 5-7 hours/week”description– a description of the coursespecialization_id– a reference to the related specialization, if applicable. Courses can be part of only one specialization. Some courses are not affiliated with any specialization, so this attribute is not mandatory.min_grade– the minimum grade needed to pass a course. Usually that will be measured as a percentage. On most Coursera courses, this is 70%.course_price– the fee you’ll pay for a course.active– an on/off switch that indicates if a course will have future sessions. Active courses will have new sessions, while inactive courses will not.
Notice that the course table is named course:Course details. This is because I’ve used the course table again elsewhere to make the model clearer. To do this, I used Vertabelo’s “Copy” and “Paste as shortcut” options.
Each course is composed of a few chapters. In Coursera, students usually have a week to complete each chapter. A list of all course subsections or chapters is stored in the chapter table. The course_id attribute is a reference to the course table; chapter_no is the ordinal number of a chapter in that course. These two attributes together form the alternate key of the table. The last attribute, description, stores a detailed description for each chapter.
Each chapter is composed of video lectures, readings, quizzes, tests and projects. We won’t create separate structures in the database to store different material types. Instead, we’ll store links to these materials. And that’s where the material table comes in. The attributes in this table are:
chapter_id– a reference to the related chaptermaterial_no– an ordinal number assigned to various chapter materials. Together with thechapter_idattribute, this attribute forms the table’s alternate (unique) key.material_type_id– is a reference to thematerial_typetablemandatory– a boolean value that denotes if the material is required or optional (i.e. for extra credit)max_points– the maximum number of points that the student can achieve after completing this material. If no points will be awarded, we’ll simply use “0” as the value.
The material_type table is a dictionary of all possible material types. The only attribute beside the primary key is type_name and of course it must contain only unique values. Some expected material types are “video lecture”, “reading”, “quiz”, “test”, “final exam” and “project assignment”.
The on_course table relates each course with the lecturer(s) teaching that course. It contains only its primary key and a foreign key pair (lecturer_id and course_id). The foreign key pair forms the unique key for the table.
In the same manner, course_created_by relates a course with all the institutions that were involved in creating it.
Specializations
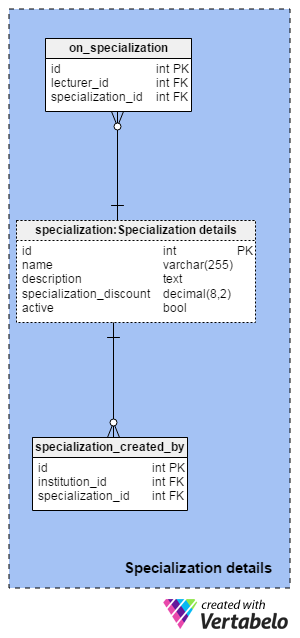
Standalone courses are great, but to master a new skill you’ll need more than one course. Specializations are a step in that direction. They are a series of courses, often four or five, and a final project where you can apply the skills you’ve learned. All specialization-related tables are in the Specialization details area.
The specialization table is the central table of this section. For each specialization, we’ll store a unique name and description. The specialization_discount is the amount a student will save if they enroll in the entire specialization rather than in the standalone courses individually. As before, the active attribute is a simple on/off switch that indicates if the specialization will have future sessions or not.
Notice that the specialization table also appears twice in our model. Inside this area, it’s named specialization:Specialization details.
The on_specialization and specialization_created_by tables have the same purpose and follow the same logic as the on_course and course_created_by tables. Of course, this time they will handle specializations rather than courses.
Students
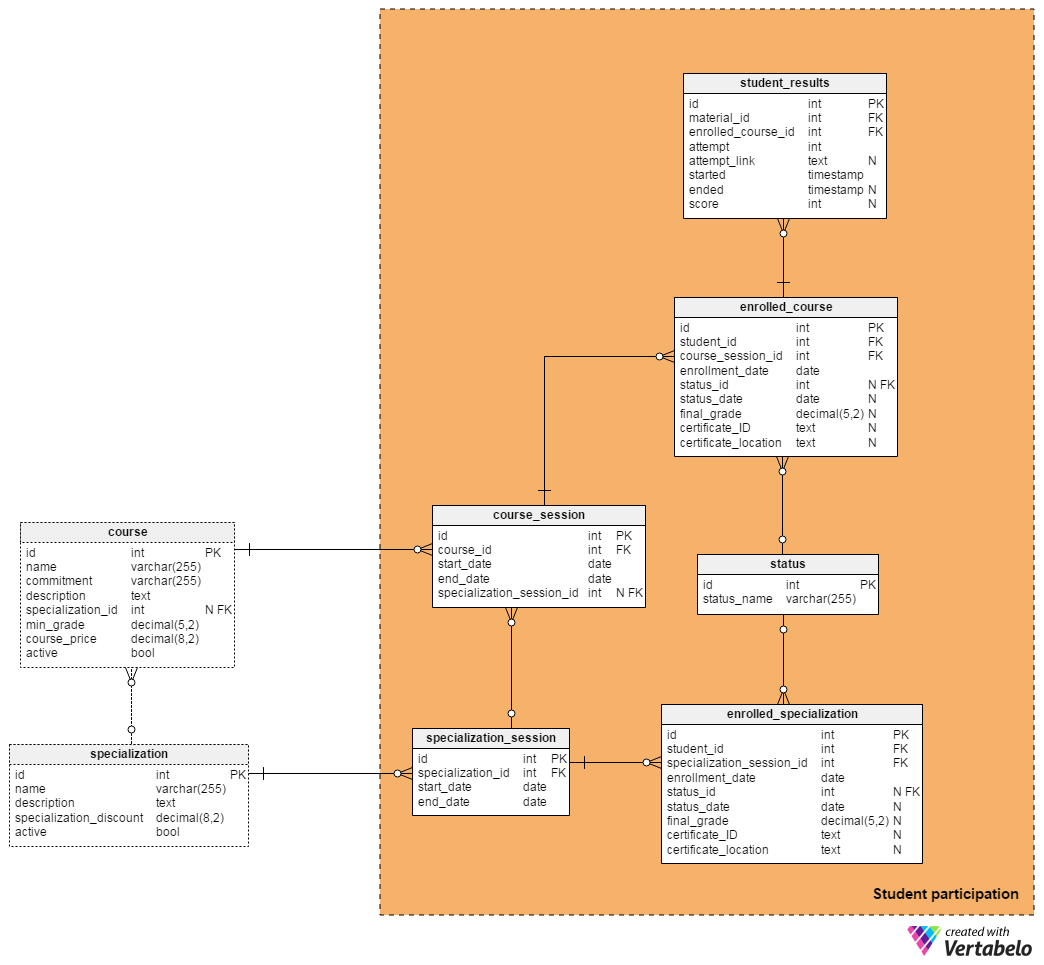
And finally we come to the students section. In the Student participation area, we’ll store records of students, sessions, and student performance.
Each course and specialization can have more than one session, so we’ll need to store when each course and specialization starts and when it ends. For courses, it’s very simple. Each new session is just a new instance of the same course. A new specialization session is a new instance of the entire specialization and all its courses.
Remember that students can enroll in one course from a specialization or in all of them. The course_sessions and specialization_session tables provide us with that information. Besides dates, they contain only foreign keys to the course and specialization_table tables. A foreign key-start date pair forms the unique key in both tables.
Course sessions can also be part of the specialization sessions, so we’ll need to add a (non-mandatory) foreign key.
The status dictionary lists all possible statuses related to student performance during a course. A few possible statuses are “dropped out”, “passed” and “failed”.
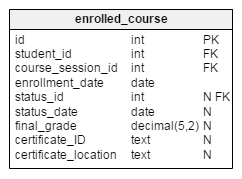
We’ll use the enrolled_course table to store every enrollment in any course session. This table contains two foreign keys, student_id and course_session_id, and together they form the alternate (unique) key for the table. Other attributes in the table are:
enrollment_date– the date when a student enrolled in that coursestatus_id– a reference to thestatusdictionary; this records how a student has performed on that coursestatus_date– the date when a status was assignedfinal_grade– the grade (as a percentage) that the student achieved for that coursecertificate_ID– a certificate identification number that the platform generates when a student passes the coursecertificate_location– a link to the exact location where the certificate is stored

The enrolled_specialization table follows the same logic as the enrolled_course table. The difference is that it relates students with specializations rather than courses.

We’ll use the student_results table to store students’ performances on specific course materials. For each material (material_id) and each student’s enrollment (enrolled_course_id) we could have more than one attempt. Therefore, the attempt attribute is the ordinal number of each student’s attempt. These three attributes together form the alternate key of the table.
In this table, the attempt_link is the location of each instance of tests or projects submitted by students. We can assume that for each attempt we’ll generate a “new” test with randomly-chosen questions. If the material doesn’t require student answers, then the link won’t exist and we’ll store a NULL value here.
Finally, the student_results table stores when a student started and ended an attempt and the score achieved. It can also store performance results on non-graded assignments as well as record which videos they watched and when, which materials they read, etc.
Institutions

The institution table is a simple catalog that lists all institutions that created courses or whose lecturers are involved in courses.
Lecturers

We could go with a much more detailed table here, but storing each lecturer’s first and last name, title, and their university name is enough for our purposes. Not surprisingly, this is all kept in the lecturer table.
Students
I’ll finish the table overview with the student table. Once more, we just need basic attributes here, and they should be self-explanatory.
How Could We Improve This Model?
This model supports the basic functionalities needed to create a MOOC platform. Still, you can probably easily think of many useful additions. Here are a few I came up with:
- Course language and subtitles for video lectures
- Machine grading
- Students reviewing and grading each other’s assignments
- Financial aid
- An option that allows students to resume a course after dropping out of it
It’s also worth mentioning that, according to Wikipedia “... Coursera’s database servers (running on RDS) answer 10 billion SQL queries, and Coursera serves around 500 TB of traffic per month.” This was in 2013. A real MOOC database model might look like the one presented in this article, but there is a lot more work to be done on the modeling and infrastructure!
In this article I tried to show the complexity of the model that lies behind a MOOC platform. I focused mainly on Coursera and edX as my examples. This model contains 18 tables, but it only scratches the surface. Feel free to comment and share the improvements you would implement in the model. If you think I missed something important, please let me know!
Like learning online? Try out LearnSQL.com – interactive SQL courses, available in your browser.
