

Some people enjoy recycling houses, furniture, or cars. Why not also enjoy recycling databases?
Imagine you inherit an old house. At first, that seems like good news: suddenly you own something that could be important and valuable. But before you celebrate, you might want to inspect the house carefully. See if it is structurally sound, if it has any foundation issues, if it is built to last... Once inspected, you might happily maintain it and even feel fortunate to have inherited it. Or, maybe you find out you will be cursed with problems that will consume your life, and it might be best to tear it down and build something new in its place.
The situation is not much different if, instead of inheriting a house, you inherit a database. That database may be a beautiful thing to work with, and you may be grateful you got your hands on it. Or, working with it may be a torture that will last for the rest of your professional life – or until you can replace it with a completely new database. Yes, legacy databases can be a great blessing or an eternal curse.
What Are Legacy Databases?
The term legacy database commonly refers to a database that has been in use for many years and is therefore unsuitable for modern apps and environments. Examples include databases based on flat files and those that reside on old, monolithic servers.
But just because a database is legacy does not mean it is obsolete. There are many applications that use it and need it to be operational. This is difficult to do for one or more of the following reasons:
- The data model is not properly documented with diagrams or data dictionaries.
- The database presents design and/or data quality problems.
- It depends on old infrastructure and, possibly, one without vendor support.
- Any changes to its structure represent a great risk for the applications that use it.
The difficulty in modeling legacy databases translates to difficulty in upgrading or updating the applications that use them. And anyone who has spent some time in the world of software development knows all applications must be upgraded sooner or later for various reasons: new requirements, changes in technological infrastructure, migrations, mergers, among others.
This means you cannot remain indifferent to the database you inherited. You must do something with it. One option is to maintain the status quo, that is, to keep using it, adapting it to a new environment so that it can continue to be useful. The other option is to replace it with an entirely new database.
Either path involves a major challenge. It is a matter of determining which path is more desirable based on the efforts and risks involved in each.
Adopting a Legacy Database
If you’re still reading, it’s because you like a challenge. Congratulations! Let’s take a look at the good and the bad of adopting a legacy database, so you can decide which path to go down: renewal or replacement.
The main positive aspect of a legacy database is that it works. Even with all the problems it may have, it works, and users know it. Retaining a legacy database avoids a common software engineering problem: resistance to change. Many users are highly suspicious of system changes, so they would rather continue to put up with the shortcomings of their current systems than change to something entirely new, no matter how promising.
Another positive aspect of legacy databases is that their problems are known. Over time, all sorts of workarounds have been implemented to deal with those problems.
They also have the whole history of data. Even if its design is flawed, the database has years of accumulated data, surely valuable to the applications and to the organization. Think of it as a marriage of many years: there is a long common history between the spouses, each knows the other’s annoying habits well, and has learned to live with them to the point of regarding them as something tolerable.
Legacy Versus Greenfield
The opposite of the legacy database is the greenfield database, which is built from scratch with no preconditions. When you do database modeling in a greenfield-like project, everything looks new and shiny. It sounds like the ideal situation to work in, but there's a catch: if you design a database from scratch, the errors in the design are your fault. Those who inherit your database will know you as the one who made the database modeling mistakes they now have to fix.
Also, greenfield design projects can have an effect on the designer similar to the blank page syndrome for writers or the white canvas syndrome for painters. They have everything to do, but they are not sure how to take that first step to start their work.
With everything said so far, we’ve tipped the scales in favor of modeling legacy databases, and you might be convinced to do the work to keep it running in an up-to-date environment. But before you get down to work, take some time to evaluate the effort involved in the refactoring required to address the shortcomings of what you have inherited.
Giving Visibility to the Problems
So, there is no ERD describing the structure of the legacy database? Then your first task as its new owner is to build a data model. If you’re not sure about the benefits of having an updated data model, I suggest you read about why you need data modeling to get an idea.
If you generate an ERD automatically with the help of a tool that allows you to reverse engineer the legacy database – such as the Vertabelo platform – you get an idea of what condition your design is in and what errors it has. The ERD allows you to easily see if there are tables with no primary key, incorrectly typed attributes, isolated tables, and other design problems.
Once you have an ERD of the legacy database and understand the flaws, you need to develop a strategy to correct them. Keep in mind that the changes you make to the database structure should not affect its information. This is precisely what refactoring a schema is about: introducing changes to improve its design without affecting its semantics.
How to Fix Legacy Database Design Problems
Keep an aspirin handy when you look at the database design you inherited, and be prepared to run into problems such as:
- Nonexistent or ineffective naming conventions.
- Inconsistent key determination strategy (natural or surrogate).
- Lack of standardization.
- Failure to meet current business requirements.
These are just a few examples, but there are other common database design errors and ER diagram mistakes you have to deal with. To put together a strategy that allows you to solve your legacy database design problems, I suggest you read about the usual steps in database design and then browse the following checklist.
Work Incrementally
“There is only one way to eat an elephant: one bite at a time,” goes a famous quote attributed to pacifist Desmond Tutu. So, if the task of correcting your legacy database seems daunting, the only way to tackle it is one area at a time.
In your legacy database ERD, establish functional or application groups, and sort these groups in order of priority (highest to lowest) and effort (lowest to highest). To do this, consult with those responsible for the applications which areas need to be corrected most urgently. Among the highest priority, choose the ones that require the least effort, and start working on those.
Subject areas help you work incrementally on your legacy database issues.
Create Views to the Legacy Schema
Views allow you to apply a “cleaning layer” to the legacy database. With views, you can simply enforce a naming convention by creating views that replicate the tables exactly but with names that conform to a convention. You can unify the tables from the legacy schema with new tables. You can enable read-only access to the legacy data, as explained below. You can do these and anything in between.
But don’t think that views are the silver bullets that will solve all of your problems. They can lead to performance problems or become difficult to maintain, as we will see below.
Create a Transitional Schema
There is a way to apply refactoring on the legacy database design. You generate a transition state in which applications accessing the original schema and those accessing the new, corrected schema, coexist.
This particular case of refactoring is that of column replacement. New columns are created to replace those to be corrected, adding triggers that update the new columns by applying a conversion on the data written to the original column. A transition period must be established to give developers time to adapt the application code to the new data model design. Once the transition period is over, you can remove the original columns and the trigger, leaving only the refactored table.
You can see an address data table in the following example, in which the phone numbers and the ZIP codes are integers. To correct this problem, new fields of the varchar type are created, and triggers are added to the table to automatically update the new fields with the data written to the old fields. After the transition deadline, a script must be run to convert all the data that has not been automatically corrected, and the triggers and the old fields should be deleted.
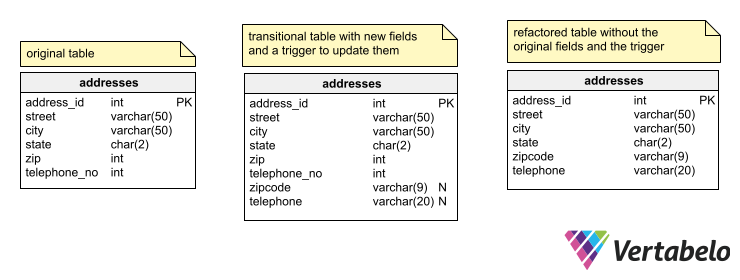
Three versions of a legacy table: original, transitional, and refactored.
This is only one of the many data model refactoring techniques that can be used to improve the design of a legacy database. The details are beyond the scope of this article; however, the key is to define a time frame for maintaining the transition elements, during which the database can be used with both deprecated and upgraded applications. Once the transition period is over, all applications should run with the refactored schema, and the transition support elements should be removed.
Consider Implementing Read-Only Access to Legacy Data
Writing data to a legacy database involves greater risk and greater complexity than just reading data from that database. The writing actions must preserve their semantics, and you may not get a complete understanding of the semantics unless you take the time to analyze in depth the original systems that write to that database. In addition, if you need to support both reads and writes to the legacy database, you need conversion rules that work in both directions.
To avoid writing to the legacy database, you may want to generate a new schema, parallel to the old one, with tables you can update without risk. Obviously, the idea is to have the new schema not present any of the design errors of the legacy schema nor add new errors.
As you add tables to the new schema, the applications that update the legacy database should be redirected to the new tables to keep the legacy schema as read-only. You can create views that consolidate the legacy and the new tables, so that the applications read each combined view as a complete entity.
Consider a Batch Approach to Legacy Data
Using views to access legacy data is not always feasible. For one thing, it can lead to performance problems from data type conversions or from limitations in generating indexes. Also, when the number of tables to be accessed in the legacy database is very large, maintaining views that point to all of them could become messy and hard to maintain.
It may be more convenient to develop ETL (extract, transform, load) processes that copy the data in batch to a new database in such situations, instead of covering the legacy database with a layer of views. You can include a staging database to clean up the legacy data in these processes. If the legacy data needs to be updated, then the ETL process should work both ways.
The main advantage of this approach is that legacy data issues can be resolved without the applications even being aware of them. The main disadvantage is the additional complexity of the ETL processes.
But keep in mind these processes are only transitional. A timeline must be established to upgrade applications to a new schema. Once they are upgraded, you can discontinue the ETL process with its staging schema and possibly archive the legacy database, leaving only the new one.
Apply an Error Handling Strategy
Be prepared to encounter quite a few data quality errors when you start analyzing a legacy database. There are several possible strategies for dealing with this problem, and you should choose the one that best suits your business needs. The options are to correct or convert the bad data, archive and delete it from the database, or just log the errors and expose them in a report.
Giving New Life to Old Data
Just as there are people who are attracted to restoring old houses into something new, beautiful, and functional, there are data modelers who enjoy recycling seemingly obsolete data models to keep them working and extract the hidden value. If you are one of them, you will earn the friendship of many users who will be happy to see you can give new life to their old data.
