

“The discipline of writing something down is the first step toward making it happen”, said Lee Iacocca, the famous automobile executive. So if you want a thorough database schema, you should start by writing it down.
Database designers can suffer from blank page syndrome – the problem writers have when they don’t know how to start a novel. But luckily, we designers can go down a more methodical path. Unlike writers, we don’t need to wait for a sudden inspiration to propel us forward. And the result of our work is not a book. It is as database schema – a necessary artifact for building and maintaining a database.
What Is Relational Database Design?
Relational Database Design (RDD) gives structure to a set of information so that it can be stored in a database and used efficiently for querying or processing purposes. The visible form of that design is an entity-relationship diagram (aka ER diagram or ERD), which is often used to create a database schema. This diagram shows the tables that make up a schema and the relationships between them.
But database design is more than just an ERD. Its importance lies in being able to document and explain the structure of a database. A database schema acts as a bridge between the requirements of a system and the operational database. A database built without a thoughtful and well-documented design leads to serious and expensive problems. Thus, it’s important to do methodical work and follow the database design process that results in an effective ER diagram.
Steps to Designing a Database Schema
Identifying the Entities
Database designers start working a list of needs – sometimes written as a narrative – that a system must satisfy. This list is the result of a requirements analysis.
Requirements analysis is usually the task of a systems analyst. However, data modelers should also participate in this task, even if only as listeners. Why? So they can receive first-hand information from users and stakeholders. This way, the designer can correct errors, biases, or misinterpretations that can later impact the database schema. You might want to read about tips for better database design and the most common database design errors to get the full picture.
Once a list of requirements has been defined, the database designer must identify the entities that will be part of the conceptual schema. To do this, it is useful to visually parse the sentences in the list of requirements and identify the relevant elements of each sentence. Each noun in the sentences is a candidate to be a primary entity in the conceptual schema. (Did you think that the language and literature classes at school were a total waste of time?)
For example, suppose you need to create a schema for a database that meets the requirements of a personnel control system. The systems analyst wrote the following list of requirements:
- Record the start time of each employee’s workday by reading it from an employee time clock.
- Assign each employee a task to perform during the workday. Each employee’s supervisor determines the task to be performed.
- Record the end time of each employee’s workday by reading it from an employee time clock.
Using a highlighter, you can identify the pertinent nouns in the previous sentences:
- Record the start time of each employee’s workday by reading it from an employee time clock.
- Assign each employee a task to perform during the workday. Each employee’s supervisor determines the task to be performed.
- Record the end time of each employee’s workday by reading it from an employee time clock.
To begin sketching your conceptual schema, you can start by creating entities for the highlighted elements in the sentences.
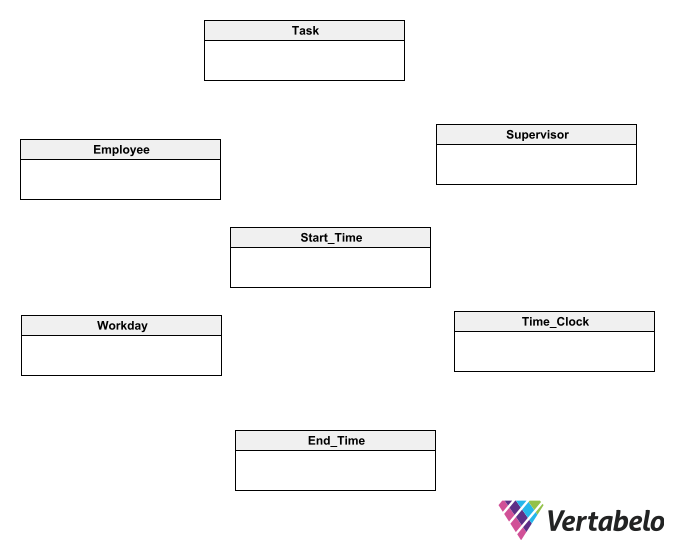
To create the first draft of your schema, draw a box for each entity identified in the requirements document.
When drawing a conceptual database schema, you don’t need to dwell on details such as attributes, primary keys, or foreign keys. You’ll deal with that later, when it’s time for detailed diagrams. This list of entities is not even definitive – it’s just a first draft.
Associating Entities
If you wanted to create a class diagram to define the behavior of the entities – so that a programmer could then implement it in the code of an application – you’d have to identify the verbs to know what actions each object performs. But what you are modeling right now is the database schema, so you don’t have to pay much attention to entities’ behavior; you need to focus on the associations or relations between the entities.
The relations may not be explicitly stated in the requirements. Therefore, you should infer them by common sense and by asking the users. For example, you might ask how workdays and employees are associated and how tasks and employees are associated (and so on). For each relation, you must specify its cardinality: one-to-one, one-to-many or many-to-many. After drawing the relations, your diagram should look something like this:
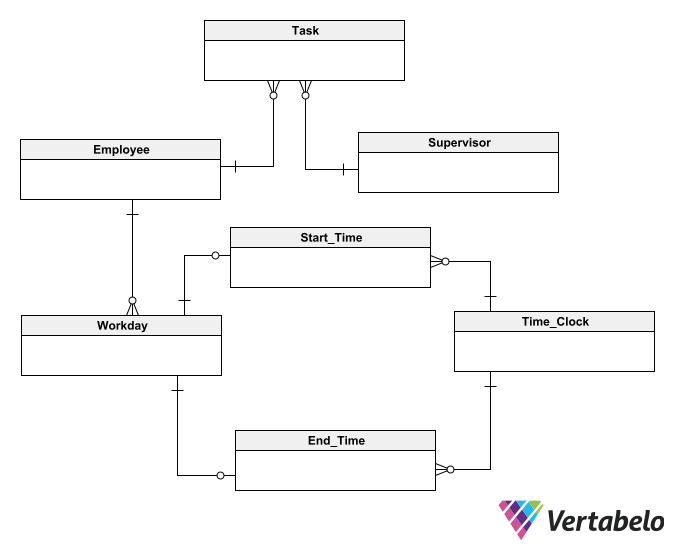
Once you add the relations, you will have a conceptual diagram you can validate with the users.
During the requirement-gathering phase, it is a good idea to go to the meetings with paper and pencil. In this way, you can quickly sketch the database schema during the interviews and use that sketch to obtain an initial validation of the model.
Moving From Conceptual to Logical Diagram
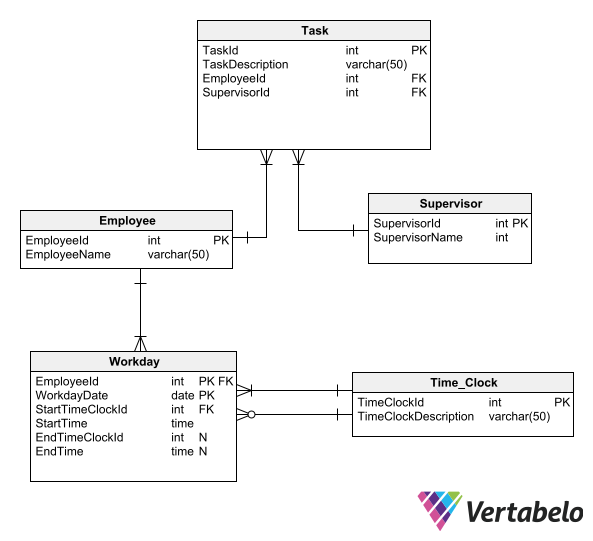
The conceptual schema lets project stakeholders know that you understood the requirements, at least at a general level. With that validation, you can add elements to the conceptual schema to turn it into a logical schema. The logical ERD diagram will show that all the entities in the schema have all the necessary attributes to describe them completely. It should also show that each attribute has the correct data type assigned to it. So your next step is to add attributes to the conceptual diagram’s entities.
Adding Attributes to the ER Diagram
Just as with relations, attributes are not always clear in the requirements. Once again, you should use your common sense and participate in meetings with users and stakeholders so you can ask them all the necessary questions. Each entity’s attributes must cover all its relevant characteristics. At the most basic level, these are its name, data type and mandatory nature. These three parts must be very clear. They cannot be left undefined. At most, they can wait to be defined during the next revision of the model.
Name
Attribute names must be chosen with care, since they will be maintained throughout the lifetime of the database. All names should follow a naming convention agreed upon by the software development team. If the same attribute appears in different entities, it should have the same name.
Data Type
A data type restricts the type of information that the attribute can store: numeric (integer, floating point, decimal), string (together with its maximum number of characters) or date (date, date and time, timestamp).
While there are databases that support compound data types, it is best to avoid them in your schema at this point. This is because the logical model should not be linked to any specific database engine. Just use simple, basic data types.
Mandatory or Nullable
For each attribute, you must decide whether or not it will support null values. This decision is not trivial; if you make it incorrectly, the database could be populated with inconsistent information or it could generate errors, e.g. if someone tries to assign a null value to a column that doesn’t allow it.
How can you decide correctly? For each attribute, think about whether there’s a point where that data doesn’t exist or isn’t known. For example, the end time of a workday will remain undefined until the employee finishes working. So the end time attribute should allow for null values.
Setting Primary and Foreign Keys
Knowing the attributes that shape each entity, you can begin to identify the subsets of attributes that uniquely identify each instance of an entity. For each entity, you will need to find a unique piece of data that serves as the primary key. If no single attribute or set of attributes serves as the primary key, you can add an attribute to act as a surrogate key. The surrogate key can also be useful if the natural key is very complex – i.e. if it consists of many fields, very long character strings, or combinations of data of different types.
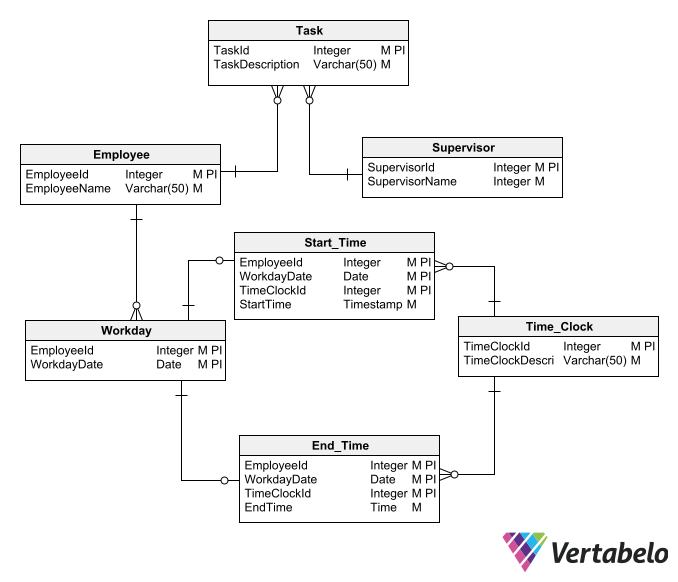
Be sure to add all the necessary attributes to the entities to cover their relevant characteristics.
Now that you have the attributes, you can better specify the associations between the entities sketched in the conceptual diagram. If two entities are associated, you must specify the corresponding attributes in each of them. If you do not find a suitable attribute in any of the entities, you’ll have to add one.
Validating and Normalizing Your Database Schema
A logical diagram can have design flaws that, if not resolved, will cause problems in operational databases. For example, an entity may lack a primary identifier, two tables may have the same name, or two related attributes may have different data types.
In small schemas of a few tables, design flaws are obvious; you can spot them just by browsing the ER diagram. But when a schema grows beyond a dozen entities, spotting flaws can be difficult. That’s when design tools (like Vertabelo’s Live Model Validation) that automatically validate diagrams become indispensable.
In addition to detecting flaws that violate the principles of the relational model, you will want to normalize your model so that it does not accept inconsistent information. The normalization process makes changes to your table schema so you can optimize storage and avoid redundant or anomalous data.
The normalization principles you’ll apply will depend on whether your schema will be used for transaction processing (OLTP) or analytical processing (OLAP). There are different levels of normalization, which are known as normal forms. For transactional processing, it is common to normalize schemas to the first, second, and third normal forms.
In analytical processing, the update is usually done through an automated process. This means you can relax normalization to some extent and add some redundant elements to allow for better querying performance. This practice is known as denormalization.
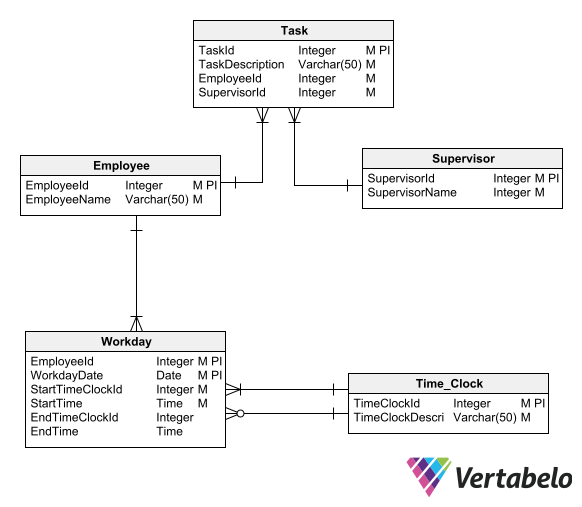
A normalized schema reduces the chances of inconsistencies and the volume that the database will have.
Generating and Implementing a Physical Model
Once you have finished designing your logical diagram, you will need to generate a physical version of it. This is the version you’ll use to implement it on a database engine. This step requires practically no effort on your part, since the transition from logical diagram to physical diagram can be done automatically with a database design tool like Vertabelo. You only need to decide which RDBMS you will implement your database on. Vertabelo offers many options: MySQL, PostgreSQL, IBM DB2, MS SQL Server, Oracle Database, SQLite, HSQLDB, Amazon Redshift, BigQuery, and Snowflake.
In the physical diagram, each column of each table is assigned a specific data type for that database engine. You can automatically generate the SQL DDL (Data Definition Language) scripts to actually create the database on the RDBMS via the database design tool. If you choose the right engine and learn how to generate a SQL script in Vertabelo, you can be sure that the DDL script will run smoothly.
To create the physical diagram, you just need to choose a target database engine. Vertabelo takes care of the rest.
A Database Schema Is a Work in Progress
After your database schema has been implemented as a physical schema on top of an RDBMS, the moment of truth will come. The floodgates will open and the data will begin to flow and populate the tables you created. In the best-case scenario, the information will fit perfectly into the tables with no errors. But be prepared to discover that there were errors made in some of the previous steps. Your database may begin reporting problems like duplicate keys, non-existent foreign keys, null values in fields that don’t support them, or information of a different data type than expected.
If you work in an Agile team, these problems will come to light during testing. They’ll be solved in the next iteration, preventing them from reaching the end user. To adapt to this way of working and promote good change management, it is essential that you have the right database design tool. If you use Vertabelo, you will be able to save versions of the database schema for each change you make. This will allow you to retrace your steps, make corrections, and generate change scripts to migrate a database schema from one version to another.
