

Database constraints are a key feature of database management systems. They ensure that rules defined at data model creation are enforced when the data is manipulated ( inserted, updated, or deleted) in a database.
Constraints allow us to rely on the database to ensure integrity, accuracy, and reliability of the data stored in it. They are different from validations or controls we define at application or presentation layers; nor do they depend on the experience or knowledge of the users interacting with the system.
In this article, we will briefly explain how to define the following types of constraint and their usage:
Why Do We Need to Define Constraints in a Database Model?
Although it is not mandatory, defining constraints ensures at database level that the data is accurate and reliable. Having those rules enforced at database level rather than in the application or presentation layer ensures that the rules are consistently enforced no matter who manipulates the data and how it is manipulated. When a customer uses a mobile or web application, when an employee uses an internal application, or when a DBA executes data manipulation scripts, any changes are evaluated at the database level to guarantee that no constraint is violated.
Are Database Constraints the Same in all RDBMSs?
Not all database management systems support the same types of constraints. When they do, there may be special features or considerations for the specific system. The syntax for creating constraints also depends on the specific RDBMS.
Constraints can be defined when we create a table or can be added later. They can be explicitly named when created (thus allowing us to identify them easily), or they can have system-generated names if an explicit name is omitted.
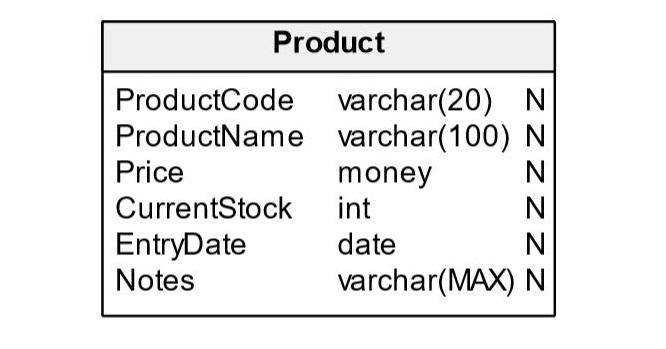
For the examples in this article, we are going to use Microsoft SQL Server as the platform to show the syntax of adding named constraints to an existing table. We will be starting with a basic table named Product with the following attributes:
Note:
You can also read the article “Constraints in PostgreSQL and How to Model Them in Vertabelo” if you want to learn the specifics of PostgreSQL constraints.
Constraint Types
Now, let’s review the different constraint types we can find in most database engines. We are going to start from the most basic then move on to the more complex.
DEFAULT
This type of constraint allows us to define a value to be used for a given column when no data is provided at insert time. If a column with a DEFAULT constraint is omitted in the INSERT statement, then the database will automatically use the defined value and assign it to the column (if there is no DEFAULT defined and the column is omitted, the database will assign a NULL value for it). Defaults can be fixed values or calls to system-provided or user-defined SQL functions.
Let’s look at our example data model. We will start by defining a couple of DEFAULT constraints for our Product table:
- For the column
EntryDate, we will useGETDATE(), a system function that returns the current date. - For the column
CurrentStock, we will use a fixed value of 0.
We need to issue the following two statements in SQL Server to create these constraints:
ALTER TABLE Product ADD CONSTRAINT DF_Product_EntryDate DEFAULT GETDATE() FOR EntryDate; ALTER TABLE Product ADD CONSTRAINT DF_Product_CurrentStock DEFAULT 0 FOR CurrentStock;
And we can see how they are defined using the Vertabelo Data Modeler tool:

Once the DEFAULT is created for a column, we can insert a row in our table without specifying the column:
INSERT INTO Product (ProductCode, ProductName, Price) VALUES (‘S10’, ‘Spoon’, 120.50);
A new row will be inserted, the EntryDate column will have today’s date stored for this row, and the CurrentStock column will have the initial value of 0.
Extra Tip #1
Most database engines (like Oracle, SQL Server, DB2, and MySQL) allow the DEFAULT to be explicitly included in INSERT statements, making it clear that the value to be used is the one defined in the constraint rather than omitting the column(s) in question:
INSERT INTO Product (ProductCode, ProductName, Price, CurrentStock, EntryDate) VALUES (‘S10’, ‘Spoon’, 120.50, DEFAULT, DEFAULT);
Extra Tip #2
Most database engines (like Oracle, SQL Server, DB2, and MySQL) also allow the value to be used in UPDATE statements. If there is a DEFAULT defined, you can use the following syntax to set the column to the DEFAULT:
UPDATE Product SET CurrentStock = DEFAULT;
CHECK
CHECK constraints allow us to define a logical condition that will generate an error if it returns FALSE. Every time a row is inserted or updated, the condition is automatically checked, and an error is generated if the condition is false. The condition can be an expression evaluating one or more columns. It can also include hardcoded values, system-provided functions, or user-defined functions.
Now, we are going to define a couple of CHECK constraints for our table, so that we:
- Do not allow the
CurrentStockcolumn to store negative values. - Do not allow the
Pricecolumn to store zero or negative values.
To do so, we need to execute the following statements:
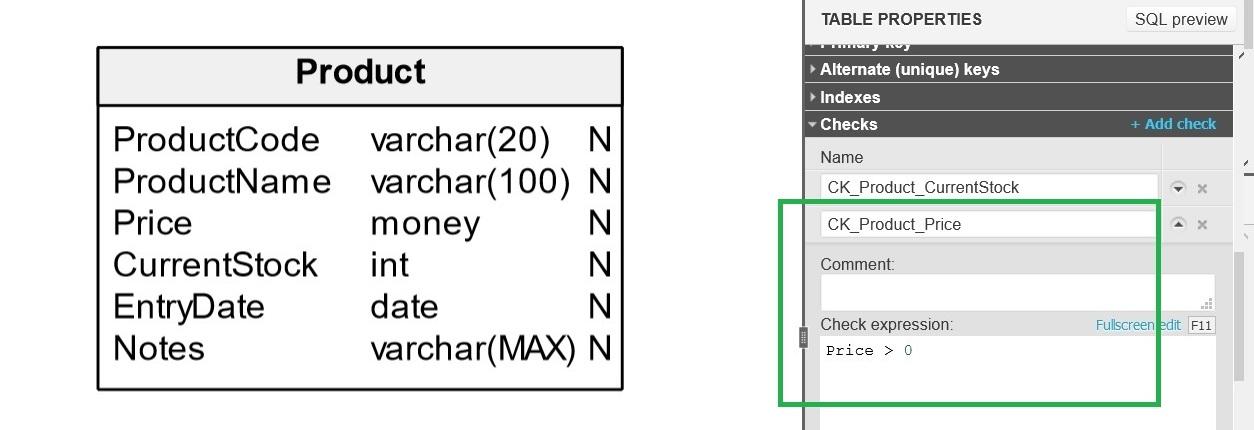
ALTER TABLE Product ADD CONSTRAINT CK_Product_CurrentStock CHECK (CurrentStock >= 0); ALTER TABLE Product ADD CONSTRAINT CK_Product_Price CHECK (Price > 0);
The Vertabelo Data Modeler tool allows us to define CHECK constraints easily:
Extra Tip
CHECK constraints return an error only when the condition evaluates to FALSE. Be sure to consider handling scenarios where the CHECK condition may return a NULL, since the database would not consider that an error. For example, this UPDATE statement will not return an error:
UPDATE Product SET CurrentStock = NULL;
By default, all columns in a table accept NULL values. A NOT NULL constraint prevents a column from accepting NULL values. Unlike other constraints, NOT NULL constraints cannot be created with a name, and they require a different syntax when we want to add them to an existing table.
We will continue enhancing our model, modifying our Product table so that all columns except Notes have a NOT NULL constraint in place by executing the following statement:
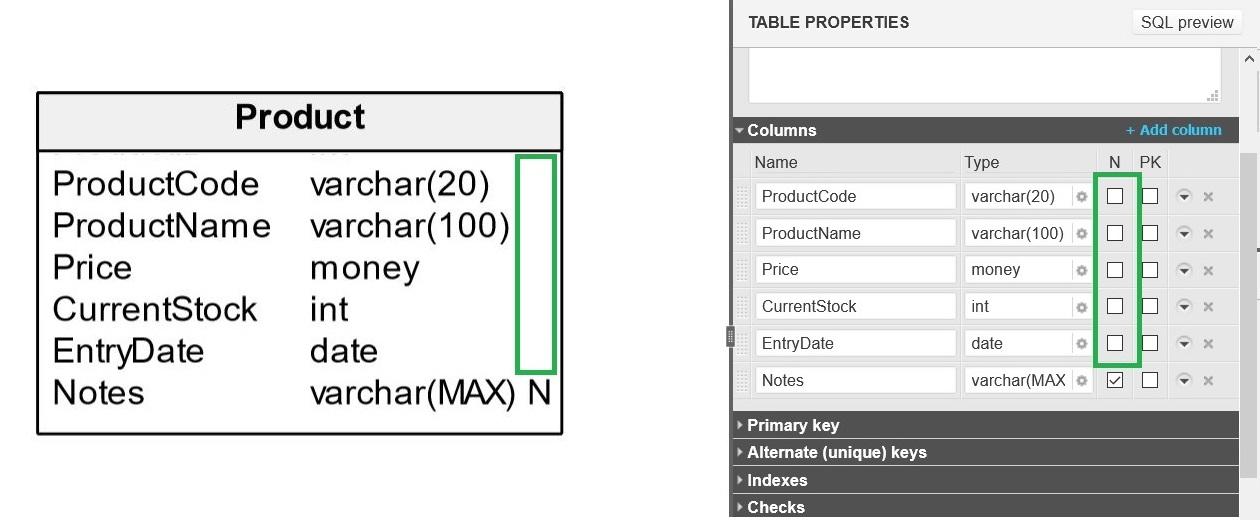
ALTER TABLE Product MODIFY ProductCode VARCHAR(20) NOT NULL, ProductName VARCHAR(100) NOT NULL, Price MONEY NOT NULL, CurrentStock INT NOT NULL, EntryDate DATE NOT NULL;
Columns are defined to be NOT NULL by default in Vertabelo Data Modeler, but you can easily change a column behavior by selecting or deselecting the N[ull] checkbox in the column definition:
Extra Tip #1
Some databases implement the NOT NULL constraint as a special class of the CHECK constraint, with the condition to be checked internally generated as “<ColumnName> IS NOT NULL”. This does not change how the NOT NULL is defined, just how it is handled internally by the RDBMS.
Extra Tip #2
Review your data model and ensure that you do not accept NULL in columns that should not be NULL. This will save you time when debugging errors or issues in the future. It may also have performance impact, since the database engine may use different execution plans depending on whether or not a column has NULL values.
UNIQUE KEY
Unique keys are defined at table level and can include one or more columns. They guarantee that values in a row do not repeat in another. You can create as many unique keys as you need in each table to ensure that all business rules associated with uniqueness are enforced.
We are going to add a couple of unique keys to our Product table to ensure we do not allow duplicate values in the following two columns:
ProductCode. Since we use this value to identify a product, we should not accept duplicate values.ProductName. Since this is the description shown when searching for products, we need to be sure that we do not have two products with the same value.
To create those two constraints, we execute the following statements:
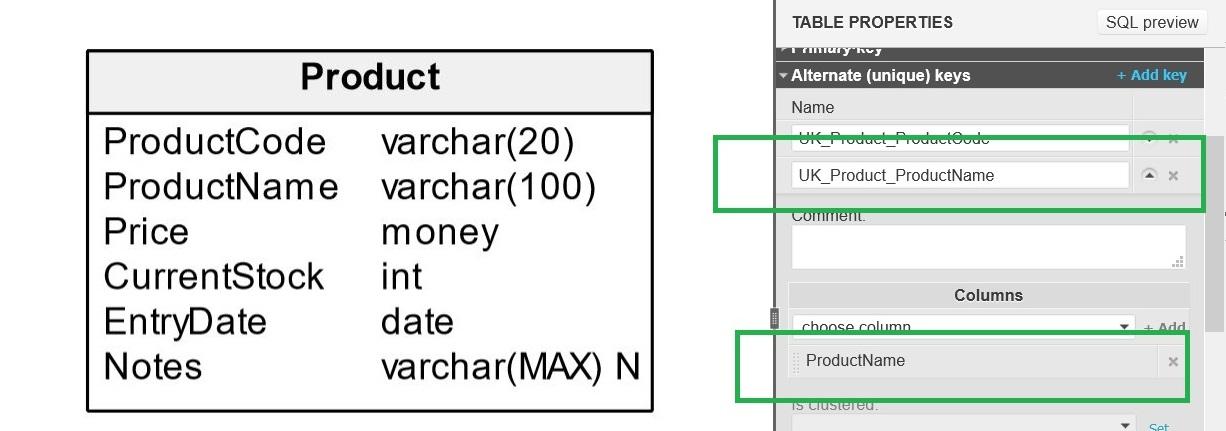
ALTER TABLE Product ADD CONSTRAINT UK_Product_ProductCode UNIQUE (ProductCode); ALTER TABLE Product ADD CONSTRAINT UK_Product_ProductName UNIQUE (ProductName);
Vertabelo Data Modeler allows you to define any unique key in a couple of simple steps:
Extra Tip
Most RDBMSs implement unique keys by using an index to speed up searching for duplicates when a row is inserted or updated. Also, most RDBMSs will automatically create a unique index when a unique key is added. However, you can elect to use an already existing index if one is available.
PRIMARY KEY
A primary key is a constraint defined at table level and can be composed of one or more columns. Each table can have only one primary key defined, which guarantees two things at row level:
- The combination of the values of the columns that are part of the primary key is unique.
- All the columns that are part of the primary key have non-null
So, we can consider the primary key as a combination of the NOT NULL and UNIQUE constraints.
Continuing with our example, we are now going to add a primary key to our table, first adding a ProductID column that will act as a surrogate primary key (please read the article “What Is a Surrogate Key?” to learn about surrogate keys and the differences from natural primary keys) and then adding the primary key. The syntax to add the constraint is:
ALTER TABLE Product ADD CONSTRAINT PK_Product PRIMARY KEY (ProductID);
When we verify our model, we can see that the column ProductID does not accept NULL and is identified as part of the new primary key in the table:
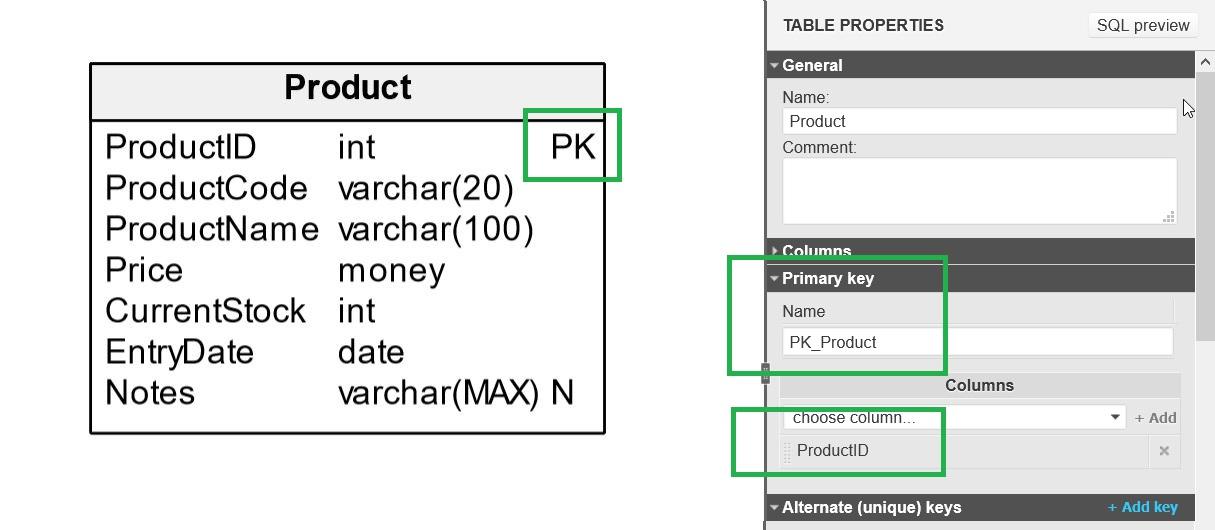
Extra Tip #1
Usually, the columns that are part of the primary key are the ones that are referenced by the foreign keys in child tables (we will explain this a little later in this article). Like any other unique keys, primary keys can be created on a single column or on a set of columns. Choosing the right column or columns for each primary key is a critical task when creating a data model. This topic is discussed in various articles we mention throughout here.
Extra Tip #2
When using surrogate primary keys, we can take advantage of built-in features like IDENTITY to populate the column created for the primary key. But if we use GUID (UniqueIdentifier) or another data type, we can also consider adding a DEFAULT constraint to the primary key column that includes a function like NEWID() to populate the column with system-generated values.
FOREIGN KEY
Foreign keys are vital to maintaining referential integrity in a database. They guarantee that each row in a child table (like Order) has one and only one row associated in a parent table (like Product). Foreign keys are created in child tables, and they “reference” a parent table. To be able to reference a table, a constraint that ensures uniqueness (either a UNIQUE or PRIMARY KEY) must exist for the referenced columns of the parent table.
When a foreign key is defined, the two tables become related, and the database engine will ensure that:
- Every value or combination of values entered at
INSERTorUPDATEin the columns that are part of a foreign key exist exactly once in the parent table. This means that we cannot insert or update a row in the Order table with a reference to a product that does not exist in theProduct - Every time we try to
DELETEa row in the parent table, the database will verify that it does not have child rows associated; theDELETEwill fail if it does. This means that we would not be able to remove a row inProductif it has one or more related rows in theOrder
In our example model, we have created two child tables named PurchaseDetail and OrderDetail, and we need them to reference the existing Product table. Since foreign keys can reference either primary keys (the most common scenario) or unique keys, we are going to use the ProductID column (which is defined as PRIMARY KEY) as reference for our OrderDetail table. However, we will use ProductCode (which is defined as a unique key) as the reference for the PurchaseDetail table. To create the constraints, we need to execute the following two statements:
ALTER TABLE OrderDetail ADD CONSTRAINT FK_OrderDetail_ProductID
FOREIGN KEY (ProductID) REFERENCES Product (ProductID);
ALTER TABLE PurchaseDetail ADD CONSTRAINT FK_PurchaseDetail_ProductCode
FOREIGN KEY (ProductCode) REFERENCES Product (ProductCode);
Foreign keys can be created easily in Vertabelo Data Modeler by relating the parent table to the child table then confirming the columns that define the relationship:
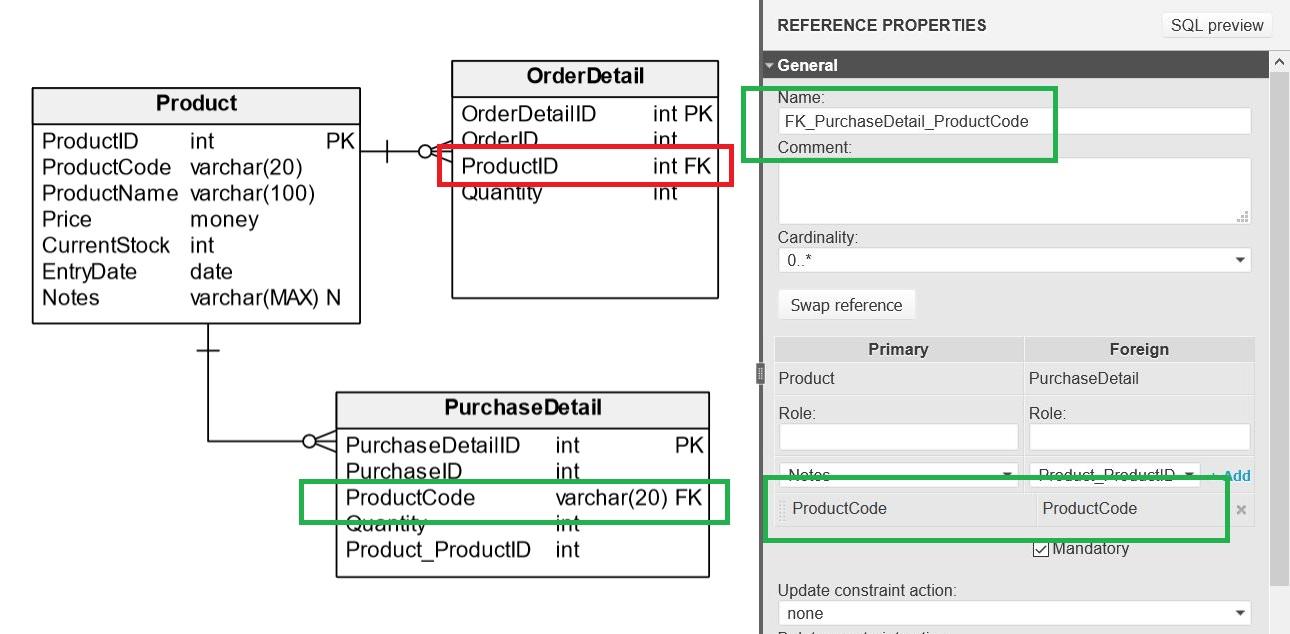
Extra Tip
A foreign key can ensure that a child row points to an existing parent row and also that a parent row is not deleted if it has child rows. There are additional behaviors discussed in the article “ON DELETE RESTRICT vs NO ACTION.” You may want to read this to take full advantage of the foreign key features.
How Database Constraints Are Classified
Constraints are usually either column-level or table-level, and the classification depends on the sections of the CREATE TABLE statement in which they can be defined. Reviewing the CREATE TABLE syntax, we can easily identify those places:
CREATE TABLE table_name ( column1 datatype column_level_constraint1 column_level_constraint2, column2 datatype column_level_constraint3, table_level_constraint1, table_level_constraint2 );
All constraint types we have reviewed can be defined at column level as long as they involve only a single column (the column that is being defined). All constraint types except NOT NULL can also be defined at table level, and this is mandatory when a constraint involves more than one column (like complex CHECK conditions and multiple-column unique, primary, or foreign keys). DEFAULT constraints can involve only one column, but they can be defined at either level.
|
Constraint Type |
Table Level |
Column Level |
|
DEFAULT |
Yes (only one column) |
Yes (only one column) |
|
CHECK |
Yes (multiple columns) |
Yes (only one column) |
|
NOT NULL |
No |
Yes (only one column) |
|
UNIQUE |
Yes (multiple columns) |
Yes (only one column) |
|
FOREIGN KEY |
Yes (multiple columns) |
Yes (only one column) |
|
PRIMARY KEY |
Yes (multiple columns) |
Yes (only one column) |
Database Constraints: What Next?
We have reviewed the six types of constraints available in most RDBMSs and taken a quick look at how to create them using the Microsoft SQL Server syntax. We have also seen examples using Vertabelo Database Modeler as our modeling tool. If you want to learn in depth how to create and maintain constraints using Vertabelo, you should follow this up with reading the article “Database Constraints: What They Are and How to Define Them in Vertabelo”.
