

Database design – including where and how to use constraints – is essential to the correct function of your database. To properly implement database constraints in SQL Server, you must understand all the requirements and execute them accordingly. How would you do this? This article will explain it in detail!
To design your database, you need a database blueprint, database constraints, indexes, database design software like Vertabelo – and more.
In this article, we are first going to prepare our database blueprint. Then, we’ll discuss SQL Server’s database constraints:
- Primary key (PK)
- Foreign key (FK)
- NOT NULL
- UNIQUE
- DEFAULT
- CHECK
For each constraint, we’ll examine its definition, usage examples, and design process in Vertabelo.
Finally, we’ll cover database indexes because of their relevance to the database design process.
To have a look at SQL database constraints in general, check out the article Database Constraints: What They Are and How to Define Them in Vertabelo.
Let’s get started!
Getting Started with SQL Server Database Design in Vertabelo
When you create a physical database model, Vertabelo lets you choose a target database at the start. Let’s briefly go through the steps for the SQL Server database engine.
- Choose Create new document from the toolbar.
- Find Physical database model and click Create.
- Enter the model name. Select Microsoft SQL Server and its version from the Database engine drop-down menu. Finally, click Start Modeling.


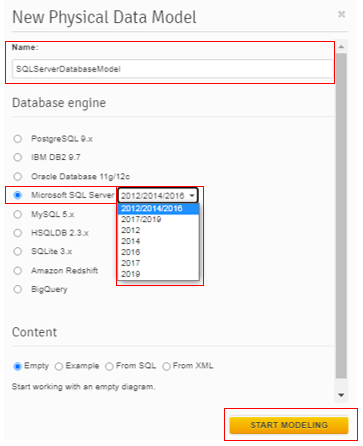
Check out this article on How to Create Physical Diagrams in Vertabelo to find out more about the creation of physical diagrams.
Now we can create our database blueprint in Vertabelo!
Creating the Database
Let’s create a database with tables that will be used throughout the remaining sections of this article. The database will look like this:
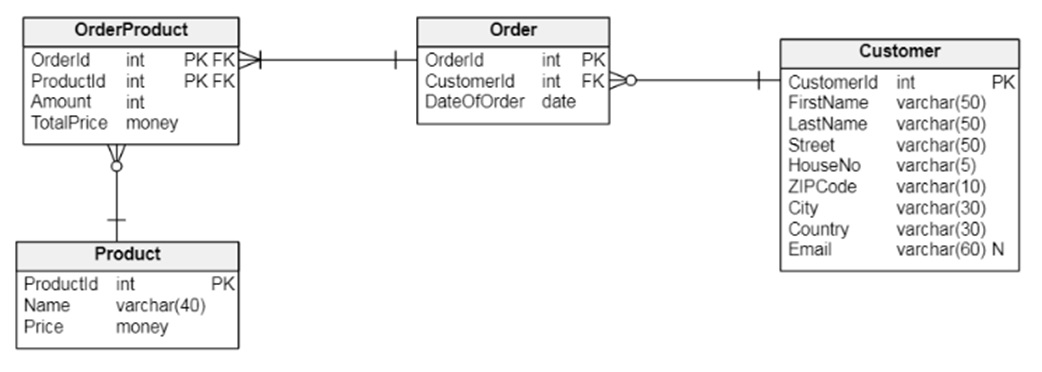
The main table of our database is Order. It stores order IDs, customer IDs, and order dates (when the order was placed). The Order table is linked to the Customer table, which stores all the customers’ details. Order is also linked to the OrderProduct table, which allows each order to consist of many products. The OrderProduct table is also linked to the Product table, which stores all the product data.
Each order is identified by an OrderId column value in the Order table. In this table, the CustomerId column is a foreign key that comes from the Customer table. Each customer can have zero or more orders and each order must have exactly one customer.
Each order can have one or more products. This is ensured by the connection between the Order and OrderProduct tables. The OrderProduct table’s primary key is a composite primary key that consists of foreign keys from the Order and Product tables.
Now that we have our database blueprint ready, let’s start implementing database constraints.
Primary Key Constraints in SQL Server
The primary key is one of the most basic database constraints. The primary key column(s) uniquely identifies each row in a table. This constraint is a combination of the UNIQUE and NOT NULL constraints; it means that the values in the column or set of columns making up the primary key must be unique and cannot be NULL.
Let’s look at an example of a primary key using the Customer table:

The CustomerId column is the primary key for the Customer table. Each customer has their own identifier stored in the CustomerId column. The CustomerId column must be unique and must contain a value.
| CustomerId | FirstName | LastName | Street | HouseNo | ZIPCode | City | Country | |
|---|---|---|---|---|---|---|---|---|
| 1 | Lisa | Johnson | Adams Park | 24 | 00987 | New York | USA | lisa@email.com |
| 2 | Andreas | Black | Mottram Way | 12 | 67543 | Chicago | USA | a.black@email.com |
| 3 | Betty | Taylor | Heather Ride | 56 | 45876 | London | UK | betty@email.com |
Customer table
Now, let’s look at an example of a composite primary key in the OrderProduct table.
The OrderId and ProductId columns uniquely identify each row in the OrderProduct table. To give it a physical meaning, each product can be present in many orders; hence, the ProductId column can store duplicate values. Also, each order can have many products; the OrderId column can also store duplicate values. However, the combination of OrderId and ProductId columns is always unique because a given product can be assigned to a given order only once. (Using the Amount column value allows us to order multiple items of one product, ensuring that each ProductID appears only once per order.)
| OrderId | ProductId | Amount | TotalPrice |
|---|---|---|---|
| 5 | 100 | 10 | 100.00 |
| 5 | 200 | 5 | 500.00 |
| 6 | 200 | 15 | 300.00 |
| 7 | 300 | 20 | 1000.00 |
| 7 | 400 | 25 | 2000.00 |
OrderProduct table
Although both the OrderId and ProductId columns store duplicate IDs, the combination of both of them is unique. That makes it a proper primary key for the OrderProduct table.
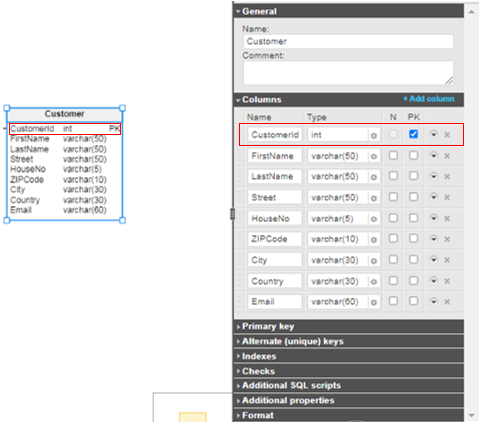
How to Model Primary Key Constraints in Vertabelo
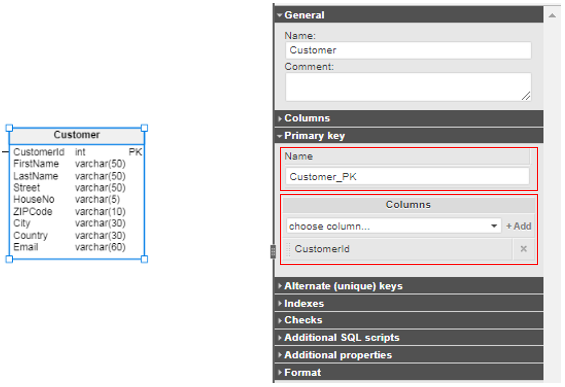
The easiest way to implement a primary key constraint in Vertabelo is to check the PK box next to the column name. Then the column is marked PK on the diagram.
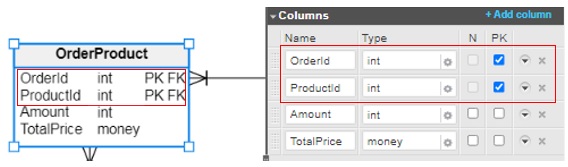
For a composite primary key, simply check the PK box for each of the columns:
In the Primary key section, you can give a name to your primary key constraint and also add or remove columns:
That’s not all! Vertabelo generates a SQL code for you when you click on SQL preview:
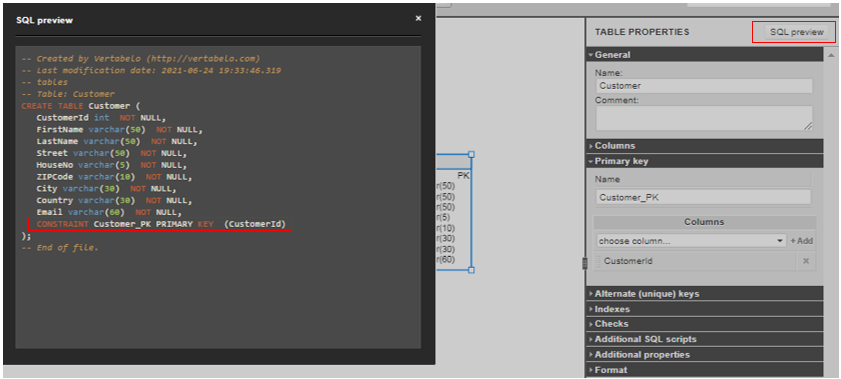
The primary key constraint is generated within the CREATE TABLE statement.
To learn more about generating an SQL script in Vertabelo, visit our article How to Generate a SQL Script in Vertabelo.
Foreign Key Constraints in SQL Server
The foreign key constraint lets you link the data in different tables. It works by using the primary key or UNIQUE column(s) of one table as foreign key column(s) in another table. That’s how the link is created. Unlike primary key constraints, there can be multiple foreign key constraints in one table.
Let’s take the Product and OrderProduct tables as an example. The ProductId column is the primary key column in the Product table. The Product table is linked to the OrderProduct table via this column. The ProductId column is the foreign key column in the OrderProduct table, and it is also part of the composite primary key there.
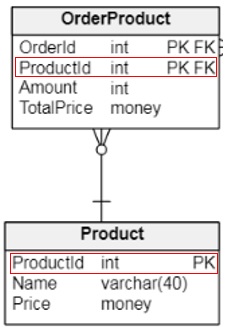
This is the OrderProduct table, with its composite primary key highlighted:
| OrderId | ProductId | Amount | TotalPrice |
|---|---|---|---|
| 6 | 1 | 20 | 600.00 |
| 6 | 2 | 30 | 1200.00 |
| 7 | 3 | 15 | 1500.00 |
| 8 | 3 | 10 | 1000.00 |
This is the Product table, with its primary key highlighted:
| ProductId | Name | Price |
|---|---|---|
| 1 | Calculator | 30.00 |
| 2 | Headphone | 40.00 |
| 3 | Speaker | 100.00 |
The columns marked in red are the primary keys for the respective tables. The relationship between these tables is one-to-many. For each record in the OrderProduct table, there can be only one record from the Product table assigned. However, each record of the Product table can be used in many records of the OrderProduct table.
The foreign key constraint can be a bit tricky when it comes to deleting or updating the primary table rows. Fortunately, you can use the ON DELETE and/or ON UPDATE clauses to specify what happens to a foreign key when the primary key value changes or is removed. In SQL Server, there are a number of ON DELETE/ON UPDATE constraint actions to choose from when defining the foreign key constraint:
NO ACTION:
No changes to the primary key values are allowed. The user trying to change the PK receives an error message and a rollback of this operation is performed.CASCADE:
All the corresponding rows from the foreign table are deleted/updated after the primary table’s rows are deleted/updated.SET NULL:
When the PK values in the primary table are deleted/updated, the corresponding values from the foreign key table are set to NULL – but only if all the foreign key columns allow NULLSET DEFAULT:
When the PK values in the primary table are deleted/updated, the corresponding values from the foreign key table are set to their default values. Important: To use this option, a default value must be defined for the column(s) in the foreign table.
During the replication process, it might happen that the foreign key relationship is broken between the tables, i.e. because of sending the tables for replication in different batches. To avoid this, the NOT FOR REPLICATION option can be added with the ALTER TABLE statement. (See the following subsection for details.)
How to Model Foreign Key Constraints in Vertabelo
To connect two tables, make a reference between them by selecting (4) Add new reference from the toolbar.
Drag the line from the primary table to the foreign table. Once the link is created, select it and set the foreign key’s name, cardinality, columns, and update/delete constraint actions.
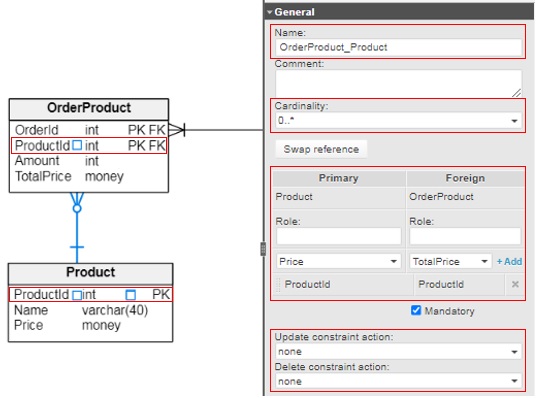 We can generate an SQL code to see how the foreign key constraint is incorporated into it:
We can generate an SQL code to see how the foreign key constraint is incorporated into it:
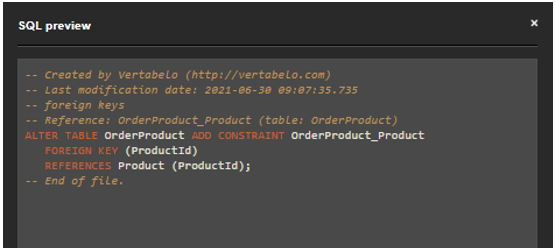
The foreign key constraint is generated after the CREATE TABLE statement using the ALTER TABLE statement.
To set the NOT FOR REPLICATION option, go to the Additional properties section, as shown below:

The code is generated at the end of the ALTER TABLE statement.
NOT NULL Constraints in SQL Server
This couldn’t be more straightforward! When implemented on a column, the NOT NULL constraint prevents it from storing NULL values. If we want a column to always have a value instead of a NULL, this constraint is the way to go.
We definitely want to know the address of each customer so we can correctly ship their order; hence, the Street, HouseNo, ZIPCode, City, and Country columns in the Order table should all have the NOT NULL constraint.
Also, we need to know each product’s name and price. So the Name and Price columns of the Product table should utilize the NOT NULL constraint as well.
Let’s see how to implement NOT NULL in Vertabelo for the SQL Server database engine.
How to Model the NOT NULL Constraint in Vertabelo
Remember how you implemented the primary key constraint in Vertabelo? It’s similar for the NOT NULL constraint, but in reverse: Each column implements the NOT NULL constraint by default. To make the column nullable, you should check the N box, as shown below.
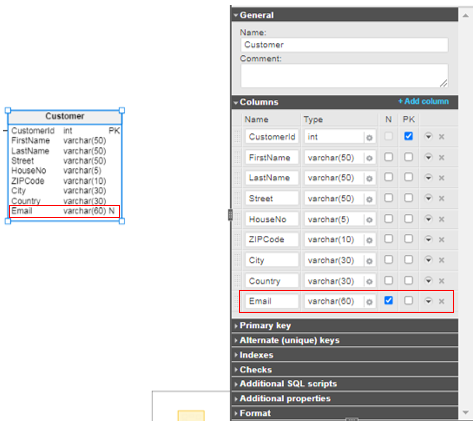
We could allow customers to omit their email addresses. They would then receive all their notifications, messages, and order confirmations by post. After checking the N box next to the Email column, the N letter appears in the diagram that marks the column nullable.
There is nothing new in the code except the change in the Email column definition:

Both NULL and NOT NULL appear in the CREATE TABLE statement, next to the column definition.
UNIQUE Constraints in SQL Server
The UNIQUE constraint ensures that no duplicate values are stored in the column. You can implement this constraint on one or more columns. If the UNIQUE constraint is implemented on multiple columns, the individual columns can contain duplicate values; the combination of both columns’ values must be unique.
By default in SQL Server, the UNIQUE constraint creates a non-clustered index. However, you can specify a clustered index. What’s the difference?
- A clustered index sorts the table data based on the key value, i.e. the values of the column on which the index is implemented. There can be only one clustered index per table because the data in the table is stored sorted according to the index.
- A non-clustered index uses pointers (i.e. row locators) that point to the key value in the table.
As you already know, the UNIQUE constraint creates a unique index on the table. The WITH clause allows you to specify the index options. The ON clause lets you specify the partition scheme name, filegroup name, or default filegroup. An extensive description of the WITH and ON clauses’ arguments is available in the SQL Server documentation.
Let’s look at an example using the Email column in the Customer table.
This is correct:
| CustomerId | FirstName | LastName | Street | HouseNo | ZIPCode | City | Country | |
|---|---|---|---|---|---|---|---|---|
| 1 | Lisa | Johnson | Adams Park | 24 | 00987 | New York | USA | lisa@email.com |
| 2 | Andreas | Black | Mottram Way | 12 | 67543 | Chicago | USA | a.black@email.com |
| 3 | Betty | Taylor | Heather Ride | 56 | 45876 | London | UK | betty@email.com |
This is not correct:
| CustomerId | FirstName | LastName | Street | HouseNo | ZIPCode | City | Country | |
|---|---|---|---|---|---|---|---|---|
| 1 | Lisa | Johnson | Adams Park | 24 | 00987 | New York | USA | lisa@email.com |
| 2 | Andreas | Black | Mottram Way | 12 | 67543 | Chicago | USA | a.black@email.com |
| 3 | Betty | Taylor | Heather Ride | 56 | 45876 | London | UK | a.black@email.com |
The Email column implements the UNIQUE constraint to avoid having different customers with the same email address.
How to Model UNIQUE Constraints in Vertabelo
To implement the UNIQUE constraint in Vertabelo, use the Alternate (unique) keys section. In this section, you can specify the unique constraint’s name, column(s), clustered or non-clustered option, and the WITH and ON clauses.
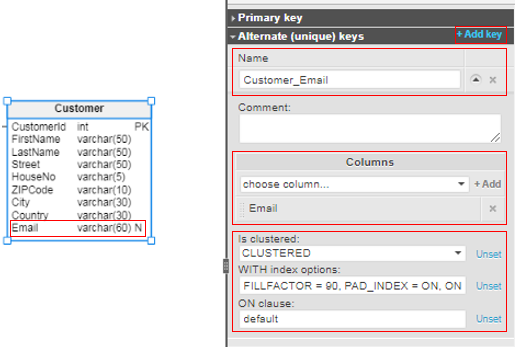
In the example above, the index is defined as clustered. The index options used are:
FILLFACTOR = 90
The leaf level of each index page during index creation or rebuild can be filled up to 90 percent.PAD_INDEX = ON
According to the fillfactor, 10% of the storage space left out is used for the intermediate-level pages of the index.ONLINE = ON
This specifies that the tables and associated indexes are available for queries and data modification during index operations.
An ON clause defined as default specifies that the index is created on the same filegroup or partition scheme as the table.
Let’s generate an SQL code for the UNIQUE constraint:
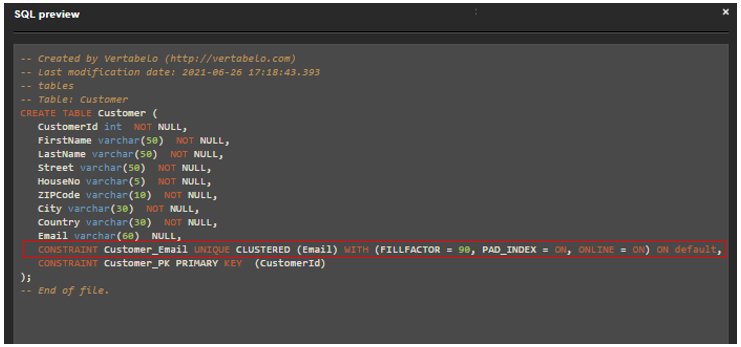
This constraint is generated within the CREATE TABLE statement.
DEFAULT Constraints in SQL Server
The DEFAULT constraint is quite handy. It allows you to set a default value for a column. This default value is applied when a user does not provide any value for this column during row insertion.
In our case, it would be useful to define the default value for the DateOfOrder column in the Order table. When a customer places an order, the date of placement is by default the current day.
Let’s see how to implement this in Vertabelo for the SQL Server database engine.
How to Model DEFAULT Constraints in Vertabelo
To assign a default value for a column, expand the column definition and insert its default value:
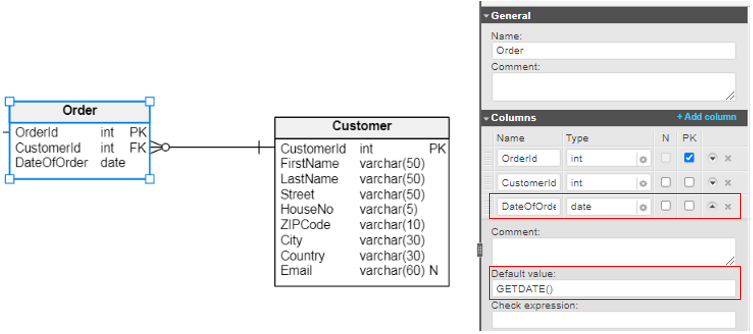
The GETDATE() function ensures that today’s date is picked up for the DateOfOrder column.
Let’s generate the SQL code:
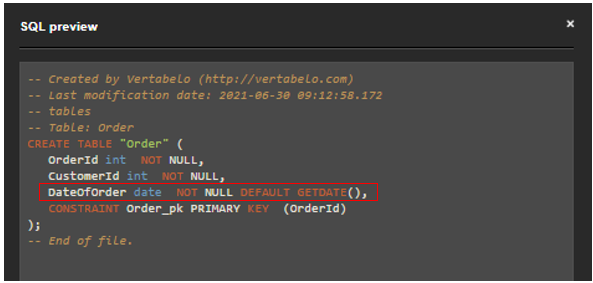
The DEFAULT constraint is generated within the CREATE TABLE statement, next to the column definition.
CHECK Constraints in SQL Server
The CHECK constraint allows you to impose any condition on a column or set of columns that must be obeyed when inserting or modifying the table’s rows.
We could implement a CHECK constraint on the Amount column in the OrderProduct table to always be greater than 0, or on the DateOfOrder column of the Order table to never be a future date.
The CHECK constraint can be implemented on more than one column at a time. For example, a CHECK constraint on the Customer table could look like the following:
Email LIKE '_%@_%._%' AND
ZIPCode LIKE '[0-9][0-9][0-9][0-9][0-9]' AND
HouseNo LIKE '[0-9]{1,3}'
This CHECK constraint makes sure that the email address format is correct, the zip code contains 5 digits, and the house number is an integer having from 1 to 3 digits.
A multicolumn CHECK constraint in SQL Server provides a NOT FOR REPLICATION option. It is similar to the same option provided for the foreign key constraint. By using this option, the replication of the CHECK constraint is disabled.
How to Model CHECK Constraints in Vertabelo
Let’s start with implementing a single column CHECK constraint. As with the DEFAULT constraint, this is done in the column definition.

The generated SQL code includes the CHECK constraint within the CREATE TABLE statement, next to the column definition.
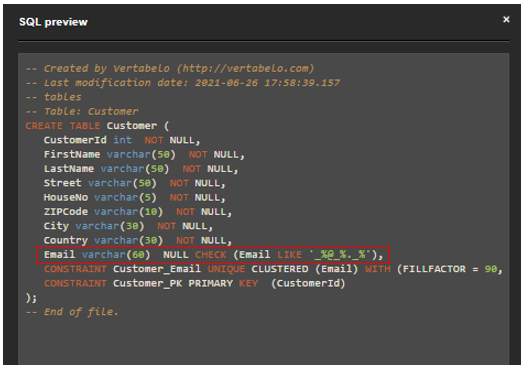
Creating a multicolumn CHECK constraint is different. To do that, you should go to the Checks section and provide the CHECK constraint’s name, the check expression, and (if you’re using it) the NOT FOR REPLICATION option.
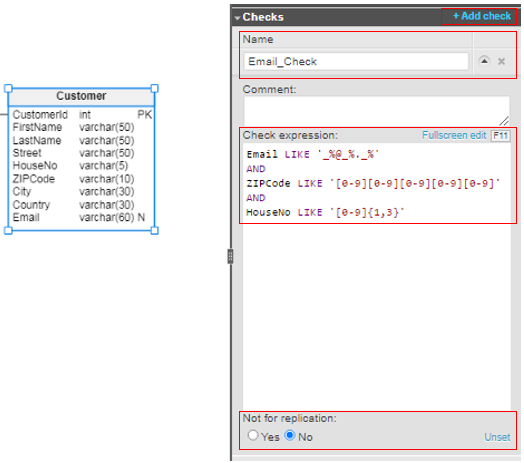
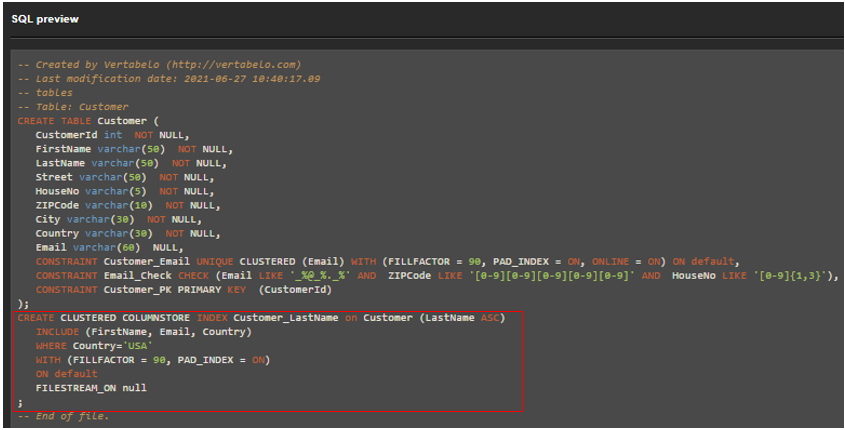
Let’s generate an SQL code for the multicolumn CHECK constraint defined above:

The generated SQL code is within the CREATE TABLE statement.
Bonus: Indexes in a SQL Server Database
Indexes are a very useful feature because they allow you to sort data in an organized way. Thus, you can find the desired data faster without going over all the data in the table. It is much like the index section at the end of an encyclopedia, where you can find the key words and page numbers for a topic you want to look up.
Let’s go through some of SQL Server’s basic options for indexes:
COLUMNSTOREis a type of index that was introduced in SQL Server 2012. As opposed to all the then-existing indexes, which were row-based, aCOLUMNSTOREindex is column-based. In other words, it stores data based on columns instead of rows. Its advantage is that it increases query performance and can be used on large workloads like data warehouses.- The
INCLUDE (column [ ,... n ])clause allows you to add non-key columns to the index. The key columns are present in the index tree, but the non-key columns are present only in the leaf levels, thus saving on performance costs. Suppose that you want to run a query and select columns A, B, and C, but the index is created only on columns A and B. In such a case, you would have to add the C column to the index, which would degrade Instead, you can use theINCLUDEclause to add this non-key column to the index, ‘covering’ all the columns in the query. WHEREin an index works like a standardWHEREclause: you can specify a filter condition so that only certain rows are included in the index. The rows that do not fulfill the given filter condition are not included in the index.- The
WITHclause allows you to specify index options. An extensive description of the arguments of theWITHclause is available in the SQL Server documentation. ONspecifies the filegroup on which the index is defined. There are three options:ON partition_scheme_name ( column_name ):
The partition of a partitioned index is mapped on the filegroups specified by the given partition scheme.ON filegroup_name:
The index is created on the given filegroup.ON "default":
The index is created on a default filegroup specified for the current session.
FILESTREAM ONspecifies the storage location ofFILESTREAMdata when a clustered index is created. It can be defined as NULL if there is no column that storesFILESTREAM
To define an index in Vertabelo, go to the Indexes section. You can add the index and specify the options described above:

And the generated SQL code is as follows:
The CREATE INDEX statement follows the CREATE TABLE statement.
A Review of SQL Server Constraints
And that’s it – you know enough about database constraints in SQL to start using them. You’re ready to design your SQL Server database!
With your enriched knowledge of database constraints and indexes, you can come up with your own implementations to meet the requirements that must be fulfilled by data, columns, or tables. Before we go, let’s quickly summarize what we’ve learned.
Each table must have a primary key to uniquely identify its rows. Foreign keys are used to link data between tables. The NOT NULL, UNIQUE, and DEFAULT constraints are very straightforward and ensure that your data complies with requirements. And the CHECK constraint is like a guard for a database table; unless the CHECK condition is fulfilled, the row will not be inserted into that table.
There are so many database engines available nowadays. That’s why we have more articles on database constraints in other database engines:
- Constraints in PostgreSQL and How to Model Them in Vertabelo
- Constraints in MySQL and How to Model Them in Vertabelo
Now, you can choose whatever suits you best.
Good luck!
