

In order to optimize the value of any website, information about the number of site visitors and their user behaviors is needed. There are a few tools which, with just a few minor changes to your site, will actually do this work for you, the most popular such tool is Google Analytics. While this article will not help you install and use Google Analytics, its goal is to help you understand the data model that may lie behind it --So, let’s get going!
What should be included in our data model?
We’ve already hinted at the kind of data collected for web analytics, but we’ll answer a few more questions before we move to the model.
-
Why might we need to analyze our webpage traffic?
The answer is pretty obvious, but let’s go ahead and lay it out. Websites fall into two basic categories – sites for which the content is the product and sites for which the content is used primarily to present products and services.
In the first category you may have a news portal, online course, or an entertainment site such as YouTube or Netflix. Income for these sites is probably generated through ads on or subscriptions. In either case you need to have as many unique visitors as possible in order to keep the site profitable.
If, on the other hand, you use your site (and content) to promote products and/or services, you’ll also want to have as many visitors as possible.
Basically, visibility is everything. If you have the best content, product or service, but nobody knows about it – you might just as well not have it at all!
-
What do we want to know?
In order to perform analysis, we should know visitors’ behavior on our site as well their demographics. The most important thing is to track the number of visits to our site. We should capture each individual session, distinguish whether it was a unique visit, and store all pages that received a clicked during the session. Utilizing tools like Google Analytics allows for precise tracking and analysis of various metrics, including site speed, user behavior, and content preferences. To enhance your expertise, consider pursuing the best Google Analytics certifications offering comprehensive data analysis training to improve website performance.
We could use any of a variety of parameters in order to assess our demographics, but perhaps the most important are location, language, age, gender, income, and interests. Technology allows us to collect some of these, but others are not accessible (and, in the interest of confidentiality, shouldn’t be).
-
How could we use collected data?
Let’s take the example of a site for which the content is the final product, e.g. news portal. If you publish a lot of articles each day, you’ll be interested, of course, to see which of them perform better. In most cases, the better performance will correlate closely with the higher number of clicks. In some cases, however, it could be a combination of two or more parameters (e.g. higher click numbers plus specific demographic details) that signals high performance.
After we have the data for analysis, we should be able to create models that will help us improve future site performance, by producing more content similar to that which has shown better performance, for example.
-
What is the final result of this whole analysis?
All gathered data plus analysis should lead to improvements in website quality --and possibly to technical improvements if some problem, such as slow site speed (which directly impacts users’ willingness to hang with the site) is indicated. Statistics is a pretty exact science. If you see a pattern, for example that 80% of your users prefer a certain type of content, then you’ll probably adjust accordingly, providing more such content, for example.
-
What should we expect in our data model?
This model will be different from most other relational models we have discussed. Most relational data models will collect data, of course, and use these for further analysis. But in our experience the process has generally included limitation of new data using existing data (using values from dictionaries, certain rules etc.). Basically, in most cases, existing (old) data interacts with the data being inserted (new data).
This is not the case with our web analytics data model, due to the fact that this model will be used primarily to gather data. New (inserted) and old (existing) data won’t interact with each other, and there are no limitations or rules. We’ll insert what we get, and that’s it! We can expect that we’ll have tremendous numbers of inserted records and that we’ll use these values in our analyses (groupings based on many different conditions).
The Data Model
The data model consists of four subject areas:
Location dimensionsSystem dimensionsPersonal & acquisition dimensionsPages & sessions
Notice that this model shares an obvious resemblance to the model presented in this article. We could compare our session table to a fact table and all tables outside the Pages & sessions subject area to dimension tables. This is not a data warehouse, however, because:
- We don’t aggregate data in the
sessiontable, - We don’t populate “dimension” tables on a regular basis,
- We have two additional tables that don’t correspond to any part of the data warehouse.
So yes, it’s pretty similar to the data warehouse, but it’s not quite the same.
Now we’ll take a look at each of these four subject areas in the same order they were listed.
Section 1: Location dimensions
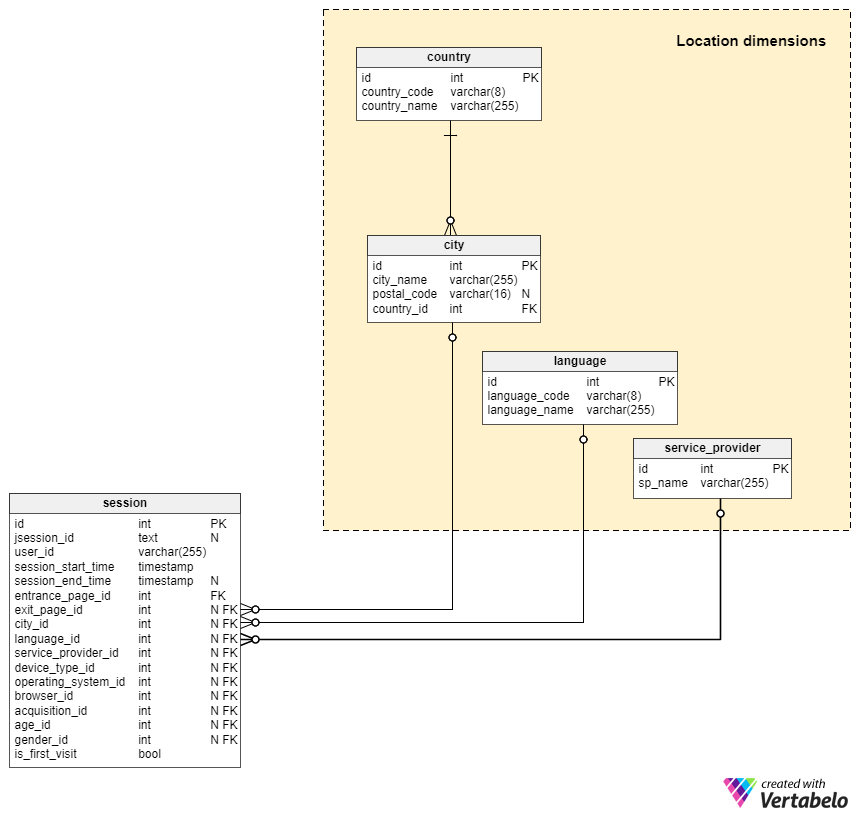
Our first subject area is the Location dimensions subject area. It contains four tables, functional dictionaries, used to reference details closely related to the location from which a site visitor connected.
Two tables, the country and city tables, are used to store data about “real” locations. In the country table we’ll store the list of all the countries in the World. This list must be updated to reflect geopolitical changes such as the emergence of new countries and/or dissolution of existing ones. The “id” is the primary key of this table and it will, of course, hold UNIQUE values only. But the remaining two attributes, the country_code and the country_name will also hold UNIQUE values only. The intended content of our country_name attribute goes without saying, while country_code will hold the 2 or 3-letter country code, e.g. ”GB” or “GBR” for the United Kingdom.
The list of all possible cities, towns, villages, (localities) is stored in the city table. We’ll store the name and postal_code for each locality, as well as the id of the country in which it’s located. The addition of new and removal of old which is necessary, in the case of geopolitical change, for our country table is not appropriate for our city table. We should check to see if a user’s indicated locality is already in our database. If so, we will reference it, and if not, we must first add it before referencing it.
The next “dictionary” in this subject area is the language dictionary. It will contain the list of all possible languages. For each language we’ll store a UNIQUE language_code (e.g. “en-us” or “en-gb”) and UNIQUE language_name. We’ll use it to indicate the language set on the computer from which a visitor accessed our site.
The last table in this subject area is the service_provider table. We’ll store only the UNIQUE sp_name in this dictionary.
Please note that all relations are NOT mandatory. This is due to the fact that we’ll know certain values in some cases and not in others. Therefore, we’ll store whatever values we do have.
Section 2: System dimensions
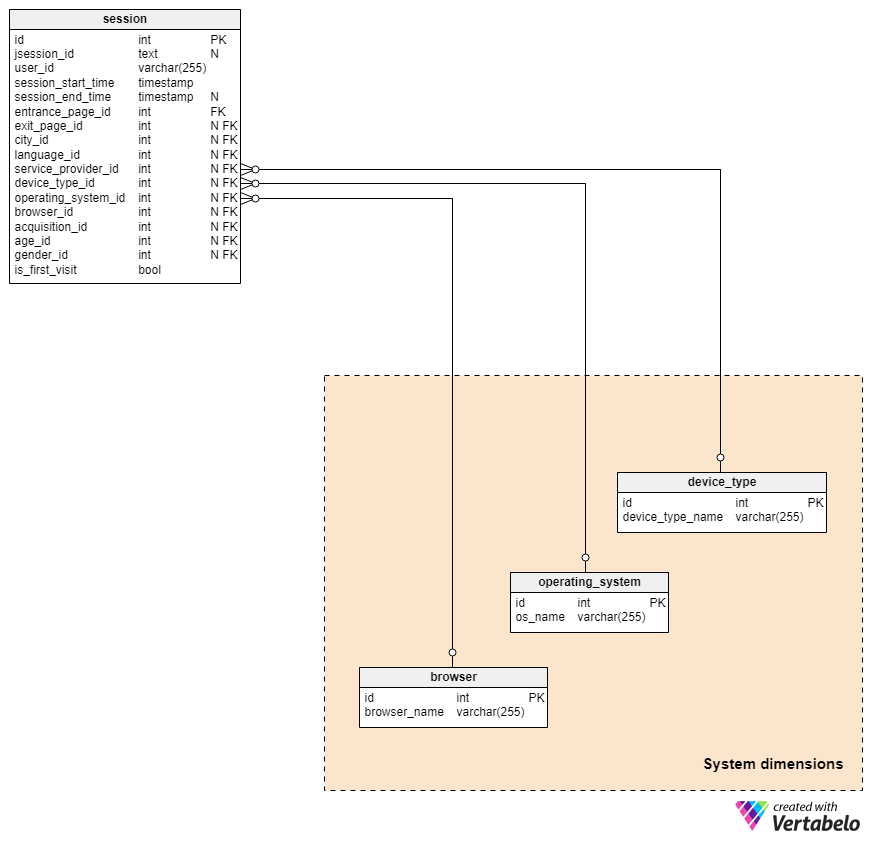
The System dimensions subject area follows the same pattern as the Location dimensions subject area (just described). It contains three dictionaries with values that are referenced in order to describe a single session.
All three tables have only the primary key attribute id and the name attribute that can contain only UNIQUE values.
In the device_type dictionary we’ll store a list of all UNIQUE device types a site visitor might use. Some expected values here are “desktop”, “tablet” and “mobile”.
The operating_system dictionary will contain -- you guessed it! -- a list of all possible operating systems. Some expected values here are “Linux”, “Windows”, “Macintosh”, “Android”, “iOS”, and “Chrome OS”. The model is not designed to store different versions of a particular operating system. We won’t distinguish Windows 10 from Windows 8, for example.
The last dictionary in this subject area is the browser dictionary. As expected, we’ll find here the list of all possible browsers. Some expected values are: "Internet Explorer”, “Edge”, “Chrome”, “Firefox”, “Opera”, “Safari” and “Yandex”. But there are also numerous other well-known and less-known browsers. Some of the less-known are: “UC Browser”, “QQ Browser” and “Sogou Explorer”.
Once more (no we don’t open the door ☺ ), these relations to the sessions table are NOT mandatory! We’ll store whatever data we have about the session, and values we don’t have shall contain NULL.
Section 3: Personal & acquisition dimensions
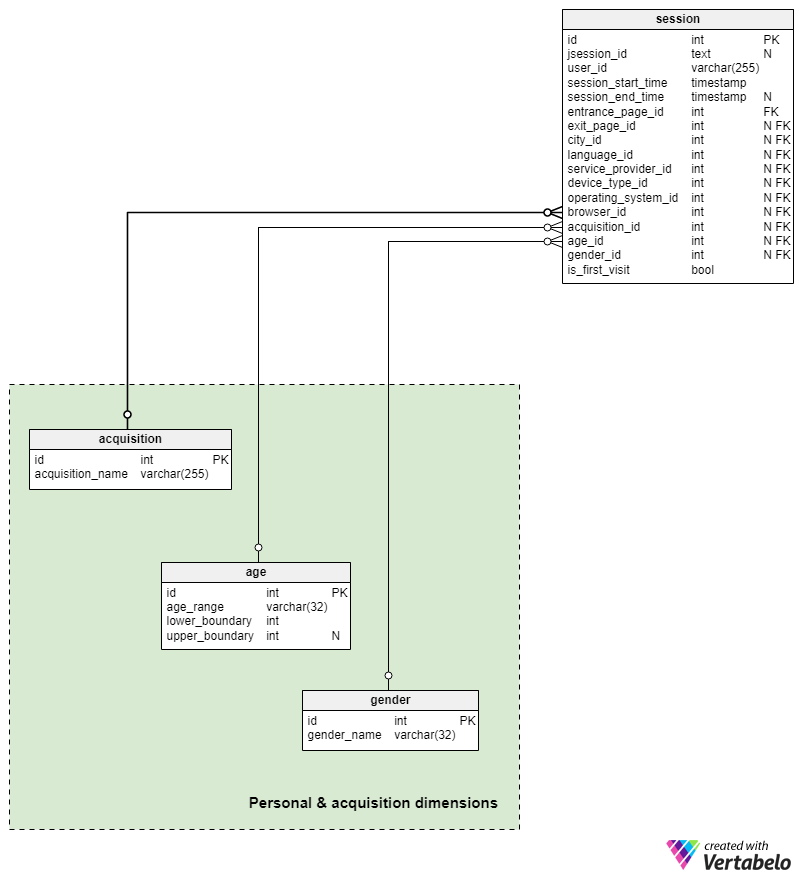
The last dimension subject area is the Personal & acquisition dimensions subject area. Here we’ll store details that are much more specific to a particular use: dimensions personal to him, more detailed than previous ones. Certainly there are even more personal dimensions than these, but we are limited in what data we are able, as well as in what we are allowed, by law, to collect.
I’ll start with the gender table. We could expect one of two UNIQUE values here.
The age dictionary contains a list of UNIQUE age groups. Each group will have its UNIQUE age_range and values for the lower_boundary and upper_boundary. An example group might be a range of “18-24” with the obvious lower and upper boundaries 18 and 24. The upper_boundary attribute can contain a NULL value, if the group is “65+”, for example.
The last dictionary table in the model is the acquisition table. Values stored in this table are used to denote the path which led a visitor to our page. This could be: “direct”, “google”, “facebook”, etc.
Section 4: Pages & sessions
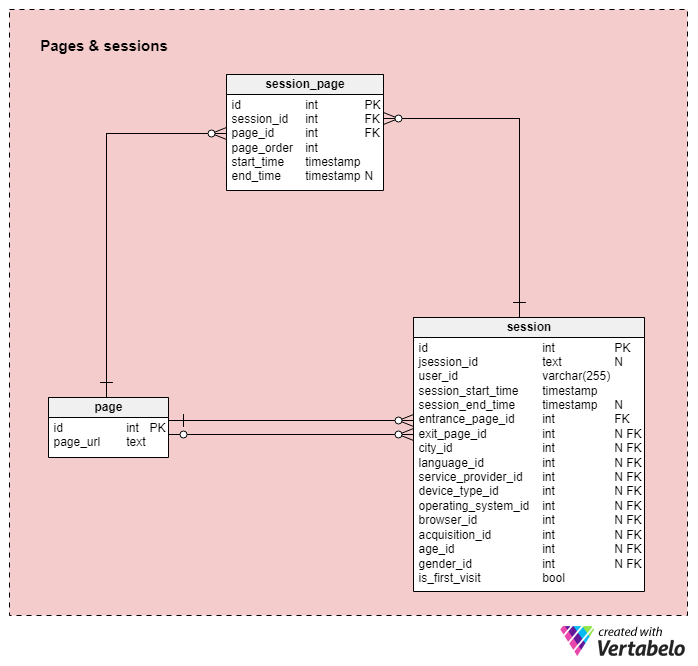
The last subject area in our model is the area that contains data about all pages and sessions. It’s composed of three tables, page session_page, and session.
In page,” we’ll keep a list of UNIQUE page_url values. Here we’ll store identifying information for each page we want to analyze. This may be limited to pages for only one website, assuming we have a separate instance of the database for each site we want to analyze. For this model, I’ll go with that assumption.
Now we’re ready to describe the central table of the model. In the sessions table we’ll store information on every site visit any visitor has ever made. For each session/visit we’ll store the following details:
jsession_id: a cookie generated automatically by the server. It’s used in session tracking, and we’ll store the generated value in this attribute.user_id: an id used to distinguish users. This enables us to know whether we have a first-time or repeat user.session_start_time&session_end_time: the start and end times for this session. Start time is the timestamp when a visitor loaded our page, and end time is the timestamp when she closed it.session_end_timewill contain a NULL value as long as the session is active and until the user closes the page.entrance_page_id: identifies the page initially reached by a visitor during her session. In most, but not all cases, this will be our main page. This information is especially important if we have promoted a subpage or post, because we would like to know to what extent that promotion is successful.exit_page_id- the page last active before a user closed our website. This value will contain NULL as long as the session is active. This value may clue us in as to which page is the “mood killer” ?? Or, if many users are entering and exiting the same page with short session time, we may assume that our content is not as engaging as we would like.is_first_visit– A flag indicating whether this is the first visit by this user during a predetermined window of time, a day, for example. We must know whether we have had 20 visits from 20 different users (Nice!) or 50 visits from a single user (Not so great). If you sell ads on your page, advertisers, too, will want to see a high number of unique visitors.- All remaining attributes are references to dictionaries used to describe that single session. Each of them could be NULL but we’ll try to gather as many values as possible.
The last table in our model is the session_page table. This is the place where we’ll store all pages (subpages on our webpage) that were opened during each session. For each record, we’ll store:
session_id&page_id: identifications of the session to which the record is related and the page opened by means of a particular click.page_order: order in which our website pages were opened. For each session, we’ll start with the value 1 for the 1st page opened and increment for each new click. This information allows us to track a customer’s progress through our site from one subpage to another.start_time&end_time: times when a single subpage was opened and closed. Theend_timewill contain NULL value until the subpage is closed.
Model Discussion
I have already mentioned that the website data analytics (WDA) model is quite different from most relational models, but that it shares much resemblance with the data warehouse (DWH). The WDA session table is comparable to the DWH fact table while WDA dictionaries could be compared to DWH dimension tables. With this in mind I want to make a few important points related to performance:
- Tables
sessionandsession_pageare the most critical tables, considering the number of records stored in them. Thesession_pagetable will contain the largest number of records in our database, as we can expect millions of records here. We need an approach allowing us to handle such large tables. - One such approach could be table partitioning. You could define criteria for dividing large tables into smaller ones, and provide conditions accordingly.
- Another approach could be adding few more DWH-like tables to a model. We could group data weekly or monthly in order to reuse these records when querying history details. In this way we could significantly reduce the number of reads required in querying the
sessiontable. On the down side, this would require more disk space since we “repeat” the information we can generate from existing data. - We should create faster queries in order to return results as fast as possible. We can expect that we’ll need to query different date and time ranges, generating live reports, reports for the last 30 minutes, and daily, weekly or monthly reports.
- Last, we need a smart strategy regarding database replications. Perhaps we need a separate database instance per web page. This would allow us to avoid mixing different data together and significantly reduce the number of records in our largest table. Another approach might be separate databases for every two or few web pages in the site.
The model we have described today could be viewed as a simplification of the model behind Google Analytics. Needless to say, many possible improvements can be made on our example. We are eager to hear from you what would you add, remove or change in this model.
