

NoSQL databases promise flexibility and performance benefits for certain use cases. But is it worth leaving behind the relational database comfort zone that guarantees consistency and organization? Read on and find the answers to the NoSQL vs. SQL database debate.
We probably all agree on the most basic definition of what a database is: a repository of information organized in such a way as to make it easy to update, search, and read.
The habit of working with relational databases instinctively leads us to think of databases as sets of interrelated tables composed of rows and columns. But the definition of a database does not talk about tables, rows, or columns.
When we put those concepts aside, we open up a range of possibilities for working with databases of unconventional design that are more suited to the modern world of Cloud computing, IoT, Big Data, real-time web applications, and unstructured information.
Welcome, NoSQL
The heterogeneous set of data models that don’t fit the traditional definition of a database is collectively known as NoSQL. This is because they don’t support standard Structured Query Language (SQL) – although many interpret NoSQL as “not only SQL”, indicating that other methods of data manipulation can be employed in addition to SQL.
The success that some NoSQL database models have achieved in recent times is due to their goal of providing more flexibility, more performance, more scalability, and more versatility than the good old relational model.
You should also note that, since it was coined in 2009, the term NoSQL has become a buzzword that has proliferated in books, blogs, courses and CVs – to the point that many IT departments have allocated resources to the adoption of NoSQL technologies without knowing precisely what goal they were pursuing.
NoSQL models offer many advantages, but it is important to understand the:
- Differences between SQL and NoSQL databases.
- Situations in which NoSQL benefits can be reaped.
In this article, I will give you clues to decide properly between NoSQL and SQL databases.
Relational Databases and the Relational Model
To begin our analysis, let’s briefly examine relational databases and the relational model.
Relational databases organize information in tables consisting of rows and columns. All rows in a table have the same columns; each row is identified by a key consisting of one or more columns. The same key value cannot be repeated in different rows.
In relational databases, you can establish relationships between pairs of tables. These relationships are implemented as constraints that force the values of one or more columns of a table to be equal to the values of the key fields for some row of a related table.
Unlike other database models, the relational model ensures that logical structures are separate from physical storage structures. While not all database engines maintain this independence, a relational database should – in theory – be able to keep its logical structure intact even if its storage architecture is replaced. MySQL, for example, uses an architecture of pluggable storage engines that adapt to different forms of storage: clustered storage, replicated storage, in-memory storage, etc.
The separation between logical and physical structures allows application developers to access information without worrying about how that information is physically stored.
If you want to learn more about relational terminology, you can read its theory and history and find out why relational databases are called “relational''.
ERDs and SQL in Relational Databases
The relational standard was adopted by the most popular database management systems (DBMSs). These also use the SQL query language to write data retrieval and manipulation scripts in declarative form. Declarative form uses statements that describe the whole operation to be performed; this is instead of stating procedures that indicate, step by step, what to do with each individual piece of data.
Entity-relationship diagrams (ERDs) are the preferred tools for relational database design. ERDs allow us to visually define all the elements that form the structure of a database; they can be used to generate physical and operational databases. For more info, check out this 10-minute read on the basics of data modeling.
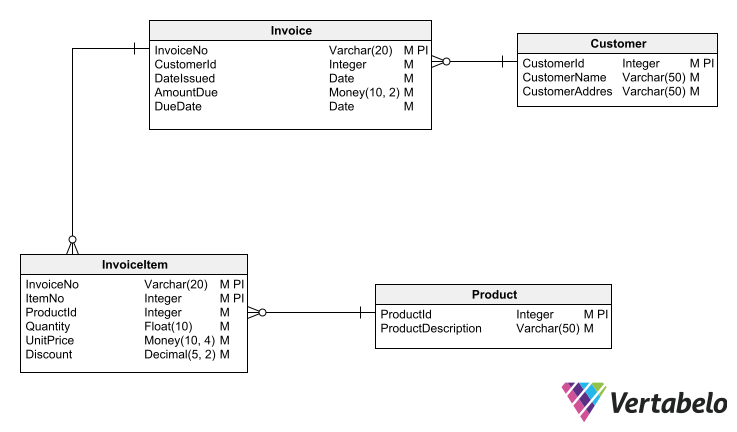
Entity-relationship diagrams allow to visually define all the elements that form the structure of a database.
Another important aspect of relational databases is that they impose a separation between data and metadata. Metadata is a separate repository from the actual data in which table definitions, views, constraints, indexes, etc. are stored. The database engine needs to query the metadata repository first to know how to access and manipulate the data itself.
The Shortcomings of the Relational Model
The drawback of relational databases is that the table structures do not allow for exceptions. If you want to insert a row with an attribute that the other rows in the table do not have, the relational model forces you to add that attribute to the table structure so that all rows then have it – even if they do not need it.
Similarly, it is impossible for an attribute to have values of different types in different rows of the same table. If a table has a field of type varchar(50), you will get an error if you try to store a 51-character string in it. You will have to extend the capacity of that field in the table structure if you want to store even one larger string. This extension will affect all the rows of the table, even if no other row needs more than 50 characters.
This rigidity of the relational model makes it unsuitable for the creation of repositories where the information lacks predefined structure. And today, many use cases require the handling of large volumes of unstructured information, such as information from massive web applications or real-time information collected by sensors or IoT devices.
Another shortcoming of the relational model is its difficult scalability. Relational databases use a scale-up architecture: to scale up, you need to add more storage, more memory, and more processing power to the database server. This form of growth is often expensive and sometimes simply not feasible.
Make Way for NoSQL
One of the differences between relational and NoSQL databases is that NoSQL was born alongside Cloud computing; it is perfectly suited to scale-out scalability architectures, where growth in capacity is achieved by spreading storage and data processing across large clusters of servers. When you need more capacity, you just add new servers to the cluster. So scalability is one of the main factors to consider when weighing NoSQL vs. SQL databases.
In addition to the advantages of scalability, the lack of predefined structures provides the flexibility to easily adapt to changes in information format or content. The fact that they allow handling unstructured information makes the term database less fitting forNoSQL repositories; many refer to them simply as data stores.
In most NoSQL data stores, schemas are flexible. Developers can define them as needed, which allows the data store to easily adapt to new types of information. This makes data stores suitable for Agile development methodologies, since changes in data definitions do not require a schema redesign.
However, it is not advisable to rely too much on the ease of working without designing schemas, thinking that it makes development more agile. What I like about database modeling is the benefits it brings to keeping data organization under control.
Types of NoSQL Data Stores
Although NoSQL has a great diversity of database models, four types are the most popular:
- Document: Data is stored as documents with variable type information, usually encoded as JSON (although other encodings, such as XML, can also be used).
- Key-value: Data is stored in the form of key-value pairs, where a key is a unique identifier and has a single value associated with it.
- Graph: Data is stored in a graph structure, using nodes to contain information entities and vertices to define the relationships between nodes.
- Wide-table and columnar: Data is stored in flexible columns. When grouped, the information can be viewed as tables, but – unlike the relational model – the names and format of the columns can vary from row to row.
Some of the NoSQL data store models are ideal for very specific use cases but are not suitable for generality. For example, graph databases are the most suitable model where the relationships between data points are more relevant than the data itself. This situation applies in cases like fraud detection, identity management, or access control.
Likewise, wide-table and columnar databases are the preferred choice when large data sets need to be managed and distributed across multiple database nodes, and where the columns are not the same for each row. Log information, IoT sensor information, and real-time analytics are application examples for this type of database.
For these particular niches where NoSQL database models stand out for their effectiveness, comparisons with relational databases become unnecessary. However, document and key-value database models can be said to “invade” the terrain traditionally dominated by relational databases; in these cases, it makes sense to balance the advantages and disadvantages and compare relational SQL to NoSQL data models.
Modeling for SQL vs. NoSQL Databases
We have seen that the ideal way to model a relational database is using ERDs. This is a universally accepted fact. In the NoSQL world, however, there is no universal consensus on modeling techniques. It is even said that these databases are “schema-less”, suggesting that there is no need to design a schema prior to manipulating the data. This may be true when it comes to prototyping or exploratory development. However, the absence of data models becomes a problem when information repositories grow in complexity or in the number of data entities or relationships between them; in such cases, working with data models is inevitable.
In NoSQL data stores, the modeling technique depends on the type of database used. Moreover, as these technologies are still evolving, there are currently no universally accepted procedures for creating models that can then be automatically derived in operational NoSQL data stores.
For the time being, conceptual and logical ERDs are the tools of choice for creating document or key-value NoSQL databases, which you can model using an intelligent database design platform such as Vertabelo.
We will see below how to use ERDs with these two NoSQL models.
ERDs for Document Stores
Document NoSQL data stores are the most easily assimilated to ERD modeling because we can define an equivalence between relational and document database concepts. This is shown in the following table:
| Relational | NoSQL (Document Store) |
|---|---|
| Database | Bucket |
| Schema | Scope |
| Table | Collection |
| Row | Document |
| Primary Key | Document Key |
Equivalence between relational and NoSQL document model concepts.
Based on these equivalences, it is relatively easy to use a logical ERD to create a NoSQL data store of JSON documents. Let’s see how to adapt the simple invoicing model from above to a document store model. This logical schema can be automatically converted into a relational physical model. You can also see that it is normalized to avoid data redundancies.
Using the equivalences of relational objects and document objects, we could derive this JSON document store with just one document for each entity:
{"customer": {
"customerId": "123",
"customerName": "DOE, JOHN",
"customerAddress": "123 Parkway Ave"
}
}
{"product": {
"productId": "ABC321",
"productDescription": "PAPER SCISSOR"
}
}
{"invoice": {
"invoiceNo": "45678",
"customerId": "123",
"dateIssued": "2022-04-20",
"amountDue": "200",
"dueDate": "2022-05-20"
}
}
{"invoiceItem": {
"invoiceNo": "45678",
"itemNo": "1",
"productId": "ABC321",
"quantity": "100",
"unitPrice": "2",
"discount": "0"
}
}
JSON Nested Documents
Unlike tables in the relational model, JSON documents support object nesting. There are cases where one entity is subordinate to another (as in the previous example, where InvoiceItem is subordinate to Invoice). When you want to derive a JSON document store from the logical model in these cases, it is best to denormalize the model to take advantage of the nesting feature.
Thus, the InvoiceItem entity can be contained within the Invoice entity, which in a document store simplifies data manipulation. For this, you should denormalize the logical diagram in all those cases in which you can take advantage of the JSON document nesting feature.
There are specific design tools for document stores that extend the entity-relationship diagram with the possibility of nesting entities, allowing to directly derive the models in JSON databases. But if you use a standard ERD design tool, you can also design nested entities using a notation that allows you to define nested objects. For example, you can prefix the attributes of the nested object with the object name:
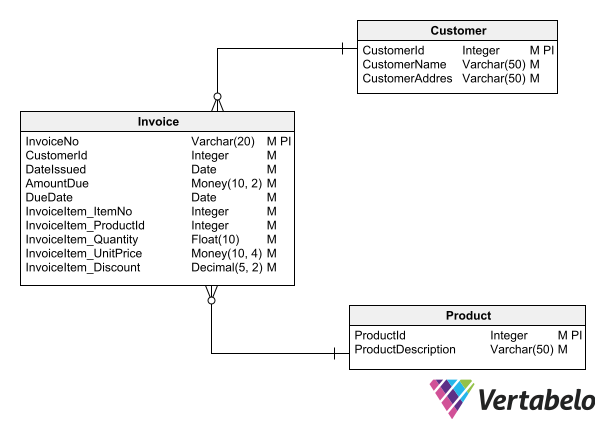
To allow an ERD to model nested objects, you need to adopt some kind of notation, such as prefixing the attribute names of nested objects with the entity name.
Since the subordinate entity is contained within its parent entity, there is no necessity to include the foreign key (InvoiceNo). Translating this diagram to a JSON document store, it would look like this:
{"invoice": {
"invoiceNo": "45678",
"customerId": "123",
"dateIssued": "2022-04-20",
"amountDue": "200",
"dueDate": "2022-05-20"
"invoiceItem": {
"itemNo": "1",
"productId": "ABC321",
"quantity": "100",
"unitPrice": "2",
"discount": "0"
}
}
}
ERDs for Key-Value Data Stores
Key-value data stores excel in applications that require very high volumes of read/write operations, support for large numbers of users, high scalability, and redundancy to provide fault tolerance. On top of that, these data stores provide optimal performance. Some examples of applications that take advantage of key-value stores include:
- Applications that require fast scalability to adapt to seasonal usage peaks (such as e-commerce sites at Christmas time).
- Delivery of personalized digital ads on web pages or apps.
- E-commerce platform product recommendations.
- Multiplayer online games’ management of user sessions.
- Big Data research.
Key-value stores can be thought of as a single large table with only two fields: a key and a value. That large table can be sorted by the key field for optimized searching and data retrieval.
In general, key-value stores do not have a query language to facilitate data retrieval. They only support basic operations such as put, get, and delete. This implies that queries and transactions must be entirely handled at the application level.
Modeling Entities for a Key-Value Data Store
To model a key-value store with multiple entities, a logical ERD can be used without having to take into account the denormalization issues for document databases. The trick to handle multiple entities in a key-value data store is to establish a unique mechanism for translating the data elements of a relational table into key-value pairs.
To identify each data element in a relational model, we need at least a table name, a primary key value, an attribute name, and a value for the attribute. Any relational database can be translated to a list of these four elements – if you don’t mind leaving aside all the metadata, such as column type definitions. Then, if you can transform these four elements into key-value pairs with unique keys, we can (theoretically) turn any relational data model into a key-value store.
The most obvious way to do this is to concatenate the first three elements – entity name, primary key value, and attribute name – to form the key. The very definition of the relational model means we know this combination does not admit repetitions. The fourth element simply becomes the value corresponding to the composite key.
To concatenate the elements that form the key, we will need a separator element. This must necessarily be a character that cannot be part of any of the other elements, e.g. a pipe character (|). Following this criterion, we can represent a schema for customer information with an email addresses table as follows:
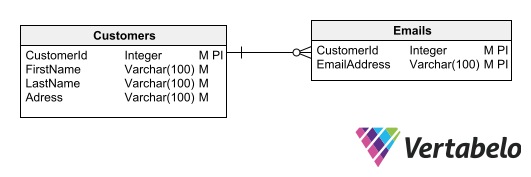
Relational model for our Customers info schema.
| Customers | |||
|---|---|---|---|
| CustomerId | FirstName | LastName | Address |
| 123 | John | Doe | 456 Parkway Ave. |
| 234 | Jane | Doe | 567 Oak Rd. |
| Emails | |
|---|---|
| CustomerId | EmailAddress |
| 123 | john.doe@something.com |
| 234 | jane.doe@something.com |
Sample customer data.
| Key | Value |
|---|---|
| Customers|123|CustomerId | 123 |
| Customers|123|FirstName | John |
| Customers|123|LastName | Doe |
| Customers|123|Address | 456 Parkway Ave. |
| Customers|123|CustomerId | 234 |
| Customers|234|FirstName | Jane |
| Customers|234|LastName | Doe |
| Customers|234|Address | 567 Oak Rd. |
| Emails|123|john.doe@something.com|EmailAddress | john.doe@something.com |
| Emails|234|jane.doe@something.com|EmailAddress | jane.doe@something.com |
The customer schema translated to a key-value data store.
With this way of translating relational schemas to key-value stores we can map – in theory – any relational model to a key-value store. The main reason to do so would be to take advantage of the great performance and scalability of key-value data stores. However, the actual exploitation of that performance will depend on how you implement the mapping between the two models, which undoubtedly requires a very large programming effort. Depending on how this programming work is done, the performance of the key-value data store can be either very well or very poorly exploited.
NoSQL or SQL: Which Database Should You Choose?
When comparing NoSQL vs. SQL databases, we have seen that each NoSQL database model has a set of needs for which it is more suitable and effective. The relational model, on the other hand, aims to provide databases for any need, although with possibly less flexibility, scalability, or performance. But for highly complex data models with a large number of entities, the relational model is the most suitable to keep the data organized and its structures under control.
So, before jumping into the NoSQL wagon, take into account that there are still no universally accepted standards for query or data manipulation languages in that wagon, nor for the documentation or model presentation. For this reason, whoever chooses to work with NoSQL databases must be very sure to do so for a truly relevant reason. Is the greater scalability, flexibility, performance, or un-structuring critical to an application? Are those needs decidedly outside of what a relational database can provide? Unless you can answer yes to both questions, the good old relational model will undoubtedly be the safest choice.
