

A payroll data model allows you to easily calculate your employees’ salary. How does this model work?
No matter whether you’re running a small or large company, you need some kind of payroll solution. That’s where a payroll application comes in handy. Plus, the bigger the company, the harder it gets to handle the employees' salary calculations; here, a payroll application becomes a necessity. To help you understand all the data required for such an application, we’ll walk you through a related data model.
Let’s see how our payroll data model works!
Data Model
With creating this data model, I tried to create a model that is generally applicable for every business. Of course, there will always be differences in regulations, company policies, etc. that will require the model to be customized to cover the needs of a specific payroll. However, the principles laid out in this model should be relevant for most organizations.
It has to be noted that this model was created with several assumptions:
- Salaries as agreed by employment contract are per year.
- Net salaries (i.e. with certain amounts deducted for taxes, etc.) are paid to employees.
- Salaries are paid monthly.
The data model consists of fourteen tables and is divided into two subject areas:
EmployeesSalaries
To better understand the model, it's necessary to go through each subject area thoroughly.
Employees
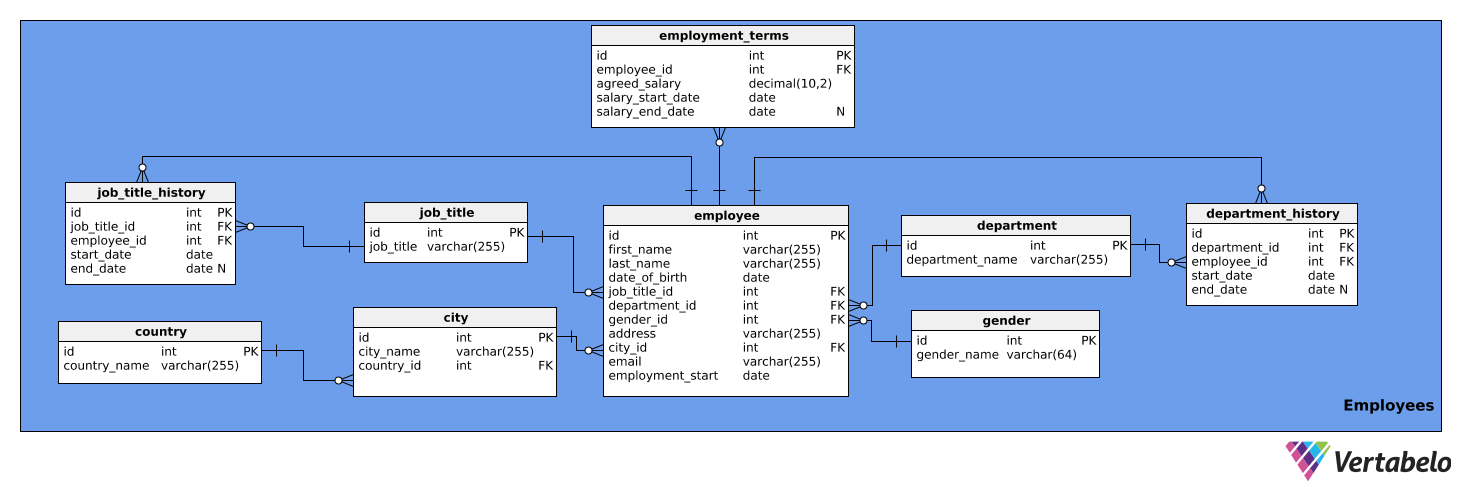
This subject area contains detailed information about employees. It consists of nine tables:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
The first table we’ll look at is the employee table. It contains a list of all employees and their relevant details. The table’s attributes are:
id– A unique ID for each employee.first_name– The first name of the employee.last_name– The last name of the employee.job_title_id– References thejob_titletable.department_id– References thedepartmenttable.gender_id– References thegendertable.address– The address of the employee.city_id– References thecitytable.email– The employee’s e-mail.employment_start– The date when this person’s employment started.
Notice that the columns job_title_id and department_id are redundant, as the information about current job titles and departments can be accessed from the job_title_history and department_history tables. However, we will keep these two columns in this table for quicker access to the info.
The following is the employment_terms table. It stores data about each employee’s salary, as agreed in the employment contract, and how it has changed over time. The table’s attributes are:
id– A unique ID for each set of employment terms.employee_id– References theemployeetable.agreed_salary– The salary stated in the employment contract.salary_start_date– The start date of the agreed salary.salary_end_date– The end date of the agreed salary. This can be NULL because a salary may have no planned change.
The job_title table is a list of the job titles that can be assigned to various company employees, e.g. analyst, driver, secretary, director, etc. The table has the following attributes:
id– A unique ID for each job title.job_title– The name of the job title. This is the alternate key.
We also need a table to store each employee’s job title history. We need this because employees can be promoted, demoted, or reassigned within the company. The job_title_history table will manage this info and will consist of the following attributes:
id– A unique ID for the job title historical entry.job_title_id– References thejob_titletable.employee_id– References theemployeetable.start_date– The date the employee first held that job title.end_date– When the employee stopped having that job title. This can be NULL because the employee may currently hold that job title.
The combination of job_title_id, employee_id, and start_date is the alternate key for the above table. An employee can have only one job title assigned at any given date.
The next table is the department table. This will simply list all the company’s departments, such as IT, Accounting, Legal, etc. It contains two attributes:
id– A unique ID for each department.department_name– The name of each department. This is the alternate key.
Employees can also change departments within the company. Therefore, we need to have a department_history table. This table will store the following:
id– A unique ID for that department historical entry.department_id– References thedepartmenttable.employee_id– References theemployeetable.start_date– The date an employee started working in a department.end_date- The date an employee stopped working in that department. This can be NULL because the employee may still work there.
The combination of department_id, employee_id, and start_date is the alternate key. An employee can work in only one department at a time.
The next table we will talk about is the city table. This is a list of all relevant cities. It has the following attributes:
id– A unique ID for each city.city_name– The name of the city.country_id– References thecountrytable.
The country table is next in our model. It's simply a list of countries and it contains the following information:
id– A unique ID for every country.country_name– The name of the country. This is the alternate key.
The last table in this subject area is the gender table. This table lists of all genders. It contains the following attributes:
id– A unique ID for every gender.gender_name– The name of gender.
Let’s now analyze the second subject area.
Salaries

This subject area consists of tables that contain all the data that directly influences salary calculations for every period as well as the amount to be paid out. It’s comprised of five tables:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Now let’s look at each table.
The first table is salary_payment. It contains all relevant details about the salary paid to each employee and has the following attributes:
id– A unique ID for each salary.employee_id– References theemployeetable.gross_salary– The gross salary, which will be the basis for further adjustments.net_salary– The net salary (i.e. the amount received by the employee after various deductions are made).salary_period– The period for which the salary is being calculated and paid.
Second is the working_hours_log table. It contains data on the number of hours worked by each employee, which can influence certain salary adjustments. This table has the following attributes:
id– A unique ID for every log entry.employee_id– References theemployeetable.start_time– The time when the employee logged in, i.e. started work for the day.end_time– When the employee logged out. It can be NULL because we will not know the exact time until the employee logs out.
The next table we will analyze is working_hours_adjustment. This table will only be used in the calculation of adjustments based on the hours worked, i.e. those that have a TRUE value in is_working_hours_adjustment in the adjustment table. The attributes are as follows:
id– A unique ID for every adjustment.working_hours_log_id– References theworking_hours_logtable.adjustment_id- References theadjustmenttable.salary_payment_id– References thesalary_paymenttable. This value can be NULL becausesalary_payment_idwill be used only once a month, when we initiate a salary calculation.adjustment_amount– The amount of the adjustment.adjustment_percentage– The percentage amount of the adjustment. This will be used for historical purposes, as the percentage can change over time.
The next table we will talk about is the adjustment table. It contains information about all the adjustments used for salary calculation, meaning all the taxes and contributions that have an impact on salary amount. Also, it will contain all the adjustments that depend on the hours worked and not worked, such as bonuses, overtime, sick leave, and maternity/paternity leave. For that, we need the following data:
id– A unique ID for each adjustment.adjustment_name– A name describing that adjustment.adjustment_percentage– The percentage amount of the particular adjustment.is_working_hours_adjustment– This is a flag marking if an adjustment directly depends on working hours, e.g. overtime, sick leave, etc.is_other_adjustment– This is a flag marking adjustments that do not directly depend on hours worked, such as tax deductions, social security contributions, employer contributions, etc.
After that, we need the adjustment_amount table. It will be used to calculate all salary adjustments except those already in the working_hours_adjustment, i.e. those that have a TRUE value in is_other_adjustment in the adjustment table. The table contains the following attributes:
id– A unique ID for each adjustment amount entry.salary_payment_id– References thesalary_paymenttable.adjustment_id– References theadjustmenttable.adjustment_amount– The amount of each calculated adjustment.adjustment_percentage- The percentage amount of the adjustment. It will be used for historical purposes, as the percentage can change over time.
Let me give you an example of how the tables working_hours_log, working_hours_adjustment, adjustment, and adjustment_amount work together to calculate a salary. Every day, the employee logs when he or she arrives at work and when he or she leaves. This data can be seen in the working_hours_log table. Let's say that our employee has worked 10 hours overtime for one month and, according to the company's policy, he or she will be paid 20% more per hour for every hour of overtime. By referencing the adjustment table, we will be able to find the required adjustment, i.e. overtime, which will have a certain percentage amount (20%). We’ll also have is_working_hours_adjustment set to TRUE. By using data from those two tables, we will be able to calculate the adjustment and store it in the working_hours_adjustment table.
Now we can calculate all other adjustments that don’t depend on the hours worked. This will be done in the adjustment_amount table. Just as we did above, we will reference the adjustment table and find the adjustments that we need – e.g. tax deduction, social security contribution, or employer contribution – and their relevant percentages. The is_other_adjustment flag in the adjustment table will be set to TRUE for these adjustments.
Based on those calculations, we can store gross salary and net salary data in the salary_payment table.
By going over this example, we’ve covered everything in our data model!
Did You Like the Payroll Data Model?
I tried to create a model that could be used in nearly all situations. However, it’s impossible to include all the specific parameters that influence the salary calculation in an article of this length. By covering general principles, I've tried to make this model useful as a solid basis for your payroll data model.
What do you think about the payroll data model? Is it applicable as a solution for your payroll needs? Have you come up with something different? Are there specific issues you’ve found that would significantly change the data model? Have your say in the comments section.
