

Life insurance is something we all hope we won’t need, but as we know, life is unpredictable. In this article, we’ll focus on formulating a data model that a life insurance company may use to store its information.
Life Insurance as a Concept
Before we start discussing the actual data model for a life insurance company, we’ll briefly remind ourselves of what insurance is and how it works so we have a better idea of what we’re working with.
Insurance is quite an old concept that dates back even before the Middle Ages, when many guilds offered policies to protect their members in unexpected situations. Even the famous astronomer, mathematician, scientist, and inventor Edmund Halley dabbled in insurance, working on statistics and mortality rates that formed the backbone of modern insurance models.
Why should you have to pay for insurance? The idea’s quite simple – you pay a certain amount (the premium) in exchange for the insurance company’s guarantee that you or your family will be compensated financially if something unexpected happens to you or your property. In the case of a life insurance policy, you designate a beneficiary who will receive a sum of money (the benefit) in the event of your death. The idea is that this money will help them recover from their loss, especially if your death creates any financial problems.
Of course, insurance companies typically pay out much less in benefits than they earn from premiums and from investing your money in, say, the stock market. Otherwise, they’d go bankrupt, and the whole system would fall apart!
That’s pretty much the gist of it. Now that we’ve got that out of the way, let’s go ahead and take a look at the data model for a typical life insurance company.
The Data Model: Overview
The data model we’ll be working with consists of five subject areas:
- Employees
- Products
- Clients
- Offers
- Payments
We’ll cover each of these sections in greater detail, in the order they’re listed above.
Subject Area #1: Employees
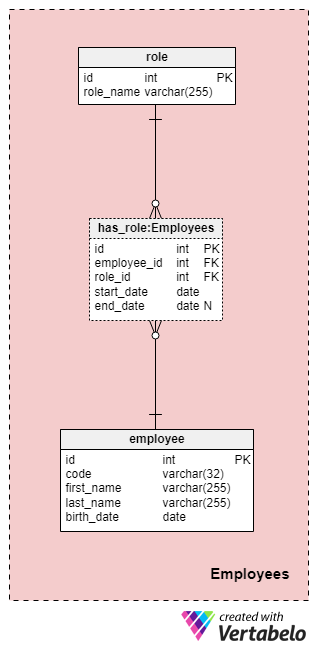
This area is not necessarily specific to this data model but is still very important because the tables contained herein will be referenced by other subject areas. For the purposes of our insurance company data model, we’ll of course need to know who performed what action (e.g., who represented our company when working with the customer/client, who signed the policy, and so on).
The list of all company employees is stored in the employee table. For each employee, we’ll store the following information:
code— a unique key that identifies a single employee. Since the code will be used as an attribute in other tables, it will serve as an alternate key in this table.first_nameandlast_name— the employee’s first and last names, respectively.birth_date— the employee’s date of birth.
Of course, we could certainly include many other employee-related attributes in this table, but these four are more than enough for now. We’ll follow this pattern throughout the article and try to keep things as simple as possible, but do note that you can definitely expand this data model to include additional information.
Since employees can change their roles in our company at any time, we’ll need a dictionary table to represent company roles and a table to store values. The list of all possible roles that employees can assume at our life insurance company is stored in the role dictionary. It has only one attribute named role_name that contains uniquely identifying values.
We’ll relate employees and roles using the has_role table. In addition to the foreign keys employee_id and role_id, we’ll store two values: start_date and end_date. These two values denote the range in which this company role was active for a particular employee. The end_date will contain a value of null until an end date for this employee’s role has been determined. The alternate key for this table is the combination of employee_id, role_id, and start_date. To avoid duplicating the same role for the same employee, we’ll need to check programmatically for any overlaps each time we add a new record to the table or update an existing one.
Subject Area #2: Products
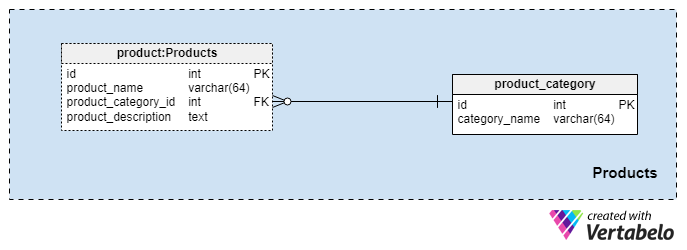
This subject area is quite small and only contains two tables. Values from these tables are prerequisites for our other subject areas, so we’ll discuss these briefly.
The product_category dictionary stores the most general categories of products that we plan to offer to our clients. The only value we’ll store in this table is the unique category_name to denote the type of insurance we offer, which could be personal life insurance, family life insurance, and so on.
We’ll categorize our products even further using the product table. This table represents the actual products we sell and not their categories. As you can imagine, we can group products by duration (e.g., 10 or 20 years, or even a lifetime). If we choose to do so, we’ll likely have products with the same product_category_id but different names and descriptions. For each product, we’ll store the following basic information:
product_name— the name of this product. It is used as an alternate key for this table in combination with theproduct_category_idattribute. It’s unlikely that we’ll have two products with the same name that belong to different categories, but it’s nonetheless a possibility.product_category_id— identifies the category to which this product belongs.product_description— textual description of this product.
Subject Area #3: Clients

We’re now getting much closer to the core of our data model, but we’re not quite there yet. Life insurance is unique because a policy can be transferred to a family member or someone else, whereas policies for other forms of insurance (such as health insurance or car insurance) belong to a single client and cannot be transferred. For this reason, we’ll need to store not only information about the client to whom the policy belongs but also information about any related people and their relationship to the client.
We’ll start with the client table. For each client, we’ll store the unique code generated or manually inserted for that client, as well as the foreign keys referencing the table with their personal data (person_id) and the table containing our internal categorization (client_category_id).
The client_category dictionary allows us to group clients based on their demographics and financial details. The client categories will then be used to determine the insurance policy we’re ready to offer to a particular client. Here, we’ll only store a list of unique values that we’ll then assign to clients.
Since we’re talking about life insurance, so we’ll assume that a client is a single individual. However, as we mentioned before, there may be other people related to the client to whom the policy may be transferred or who may receive the policy benefit upon the client’s death. For this reason, we’ve created a separate person table. For each record in this table, we’ll store the following information:
code— an automatically generated or manually inserted value used to uniquely identify the related person.first_nameandlast_name— the person’s first and last names, respectively.address,phone,mobileandemail— contact details for this person, all of which contain arbitrary values.
The remaining two tables in this subject area are needed for describing the nature of the relationship between clients and other people.
The list of all possible relation types is stored in the client_relation_type dictionary. As with other dictionaries, this will contain a list of unique names that we’ll later use when describing the relationship between a particular client and another person.
Actual relation data are stored in the client_related table. For each record in this table, we’ll store references to the client (client_id), the related person (person_id), the nature of that relation (client_relation_type_id), all addition details (details), if any, and a flag indicating whether the relation is currently active (is_active). The alternate key in this table is defined by the combination of client_id, person_id, and client_relation_type_id.
Subject Area #4: Offers
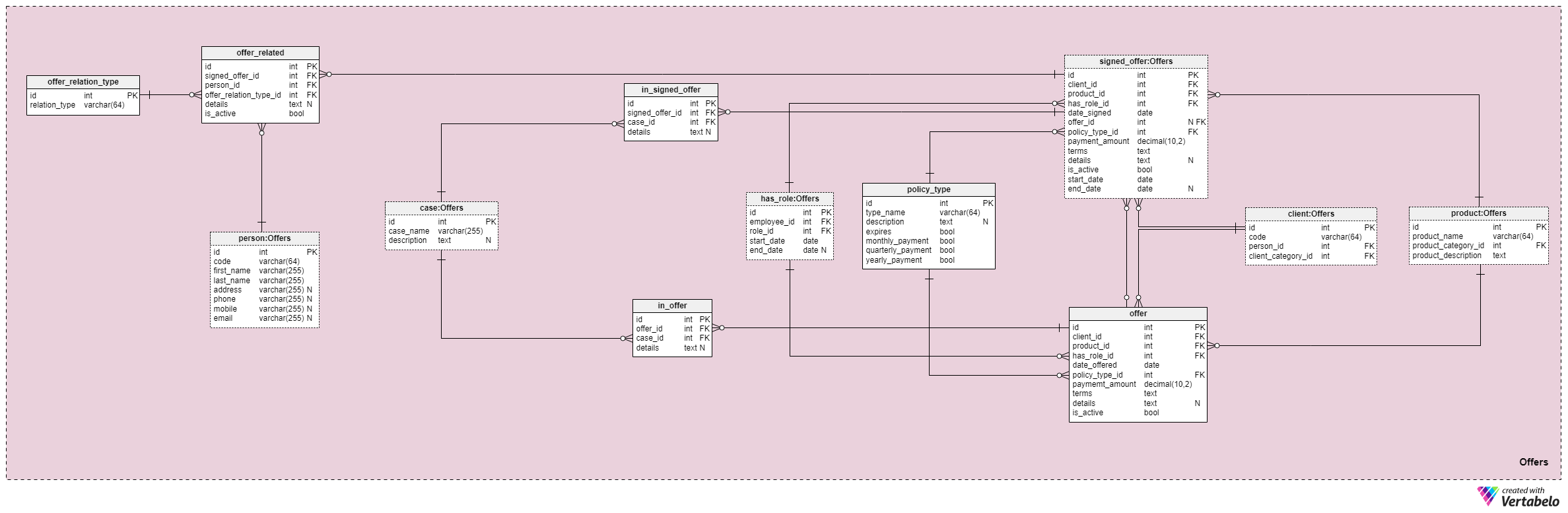
This subject area and the one that follows are at the heart of this data model. They cover offers and signed policies, as well payments related to offers. First, we’ll describe the Offers subject area. It may seem complex because it contains 12 tables. However, four of these 12 (has_role, product, client, and person) were described in previous subject areas, so we won’t repeat our discussion here.
The offer and signed_offer tables have similar structures because they will be used to store very similar data in our model. However, while offer will mainly be used to store any policies (and their details) that we have offered to our clients, the signed_offer table will be strictly used to store information about clients who have actually signed policies with our company. We’ll cover these tables together, noting any differences where they appear. The attributes in these two tables are as follows:
client_id— reference to the unique identifier for the client who signed a particular offer.product_id— reference to the unique identifier of the product that was included in the signed offer.has_role_id— reference to the id of the employee and the role they served at the time the offer was presented/signed.date_offeredanddate_signed— actual dates signifying when this offer was presented to the client and when it was signed, respectively.offer_id— a reference to the previous offer for this client. This can contain a value of null because the client could have signed a policy without having any previous offer from the company, such as if they approached us on their own. This attribute strictly belongs to thesigned_offertable.policy_type_id— reference to the policy type dictionary denoting the type of policy we offered to the client or had them sign.payment_amount— the amount the client must pay for the policy on a regular basis.terms— all terms of the agreement, in textual (XML) format. The idea is to store all important details concerning the financial part of the policy in this attribute. Examples of text we could store are the total policy amount, the number of payments the client must make, and so on.details— any additional details, in textual format.is_active— flag denoting whether the record is still active.start_dateandend_date— denote the time range in which this policy is/was active. If the policy was signed for a lifetime, then end_date will contain a value of null.
There’s also the policy_type dictionary that we briefly mentioned before. We need some degree of flexibility in how we offer the same product to different clients, based on factors such as age, health, marital status, credit risk, and so on. For each policy type, we’ll store a type_name identifier, an additional textual description, a flag named expires signifying whether the policy can expire, and another flag indicating whether this policy type’s premiums need to be paid monthly, quarterly, or yearly. Some expected policy types are: Term Life, Whole Life, Universal Life, Guaranteed Universal Life, Variable Life, Variable Universal Life, and Life Insurance After Retirement.
Moving on, we now need to define all cases and situations a particular policy can cover. We need to relate these cases to specific offers and signed offers.
The list of all possible cases our policies cover is stored in the case dictionary. Each record in this table can be uniquely identified by its case_name and has an additional description, if one is needed.
The in_offer and in_signed_offer tables share the same structure because they store the same data. The only difference between the two is that the first one stores cases covered in the policy that was merely offered to the client, whereas the second stores cases in the policy signed by the client. For each record in these two tables, we’ll store the unique pair of offer_id/signed_offer_id and case_id, the latter of which denotes the case or incident covered by the policy. All other details will be stored in a textual attribute, if needed.
As we mentioned before, life insurance policies are almost always related not only to clients but also to their family members or relatives. We need to store these relations in this area as well. They will be defined at the time a policy is signed, but they could also be changed throughout the duration of the policy.
The first thing we need to do is to create a dictionary containing all possible values that can be assigned to a relation. In our model, this is the offer_relation_type dictionary. Aside from the primary key, this table only contains one attribute—the relation_type – that can hold only unique values.
We’re almost there! The last table in this subject area is titled offer_related. It relates a signed offer to anyone who is related to the client. Therefore, we’ll need to store references to the signed policy (signed_offer_id) and the related person (person_id) and also specify the nature of that relation (offer_relation_type_id). Additionally, we’ll need to store details related to this record and create a flag to check if it is still valid in our system.
Subject Area #5: Payments

The last subject area in our model concerns payments. Here, we’re only introducing three new tables: payment, payout_reason, and payout.
All payments related to policies are stored in the payment table. We only included the most important attributes here:
signed_offer_id— reference to the unique identifier of the signed offer (policy).payment_date— the date when this payment was made.amount— the actual amount that was paid.description— an optional description of the payment, in textual format.person_id— reference to the unique identifier of the person who made the payment. Notice that the client who signed the offer is not necessarily the only person who can make a payment.client_id— reference to the unique identifier of the client who made the payment. This attribute will contain a value only if the client themselves made the payment.
The remaining two tables represent perhaps the most important reason why we pay for life insurance—that in the event something should happen to us, payouts will be made to our family members or life/business partners. How this happens all depends on your situation and the terms of the specific policy you signed. We’ll use two simple tables to cover these cases.
The first is a dictionary titled payout_reason and features a classic dictionary structure. Aside from the primary key attribute, we have only one attribute – the reason_name – that will store a list of unique values indicating why this payout was made.
The last table in the model is the payout table. It’s very similar to the payment table, but the most important differences are noted below:
payout_date— the date when the payout was made.case_id— reference to the unique identifier of the related case or incident that triggered the payment. This should match one of the ids included in the policy.payout_reason_id— reference to the dictionary that describes the reason for the payout in greater detail. While the payout case is shorter and more general, the payout reason will offer more specific details as to what happened.person_idandclient_id— references the person and the client related to the payout, respectively.
Summary
Awesome! We’ve successfully built our life insurance data model. Before we wrap up our discussion, it’s worth noting that there is a lot more that can be covered in this model. In this article, we mainly wanted to cover the basics of the model to give you an idea of how it looks and functions. Here are some more details that one could incorporate into such a data model:
- Additional policy upgrades are not covered in our current model (e.g., if you want to make yearly offers for existing policies, you won’t be able to do it with this structure). We should add a few more tables to store all policy changes for presented/signed offers.
- All paperwork is intentionally omitted. Of course, there will be quite a lot of paperwork associated with a particular life insurance policy, especially for the signing process and payouts. We could attach documents that describe the client status at the time the policy was signed and any changes along the way, as well as any documents related to payouts.
- This model doesn’t incorporate the structure needed for policy risk calculation. We should have all parameters that we need to test and any ranges that determine how a client’s value affects the overall calculation. The results of these calculations would need to be stored for each offer and signed policy.
- The invoice structure in reality is far more complex than what we covered in the payments subject area. We didn’t even mention financial accounts anywhere in our model.
Clearly, the insurance business is quite complex. We only discussed a data model for life insurance in this article — can you imagine how this data model would evolve if we were to run a company that offers a number of different insurance types? It would certainly take a lot of planning and thought to present an organized data model for such a company.
If you have any suggestions or ideas for improving our data model, feel free to let us know in the comments below!
