

Integrated transport is something we often hear about on the internet or in the news. While it’s not something new, it’s definitely an ongoing process, with constant changes being implemented. Today, we’ll take a look at a data model that could handle zone, passenger, and ticket info.
Let’s dig right into our integrated transport data model, starting with the idea behind it all.
Idea
Integrating transportation is necessary to maximize its efficiency and, for customers, its easy use. Integration is related to costs but also to time, accessibility, comfort, and safety. This applies to larger cities as well as smaller ones. The idea is to use the existing transportation infrastructure and optimize it for better results; this could mean coming up with new schedules, notifications, lines, or stations. Maybe just having some info is enough for you to decide to wait for the bus, rent a bicycle, or simply walk to your destination.
Let’s explain this using two examples.
In the case of a large city, there are usually many different means of transportation available: buses, taxis, trams, railways, the underground, etc. This may lead to many different private companies providing various transportation services. Combining even a few of these services would definitely benefit passengers and companies by lowering costs, raising efficiency, and providing more service per ticket.
There are also similar benefits for a smaller city. There may not be the same number of options to combine, but they could be organized to achieve maximum efficiency.
This article will mainly focus on integrated transport ticketing systems. We won’t focus on all the aspects of integration and the various types of transport; that would be too complex.
With this in mind, let’s move to our model.
Data Model
The model consists of two subject areas:
Cities & companiesTickets
We’ll describe them in the order they’re listed.
Cities and Companies
In the first subject area, we’ll store all the tables required to set up transportation zones in cities.
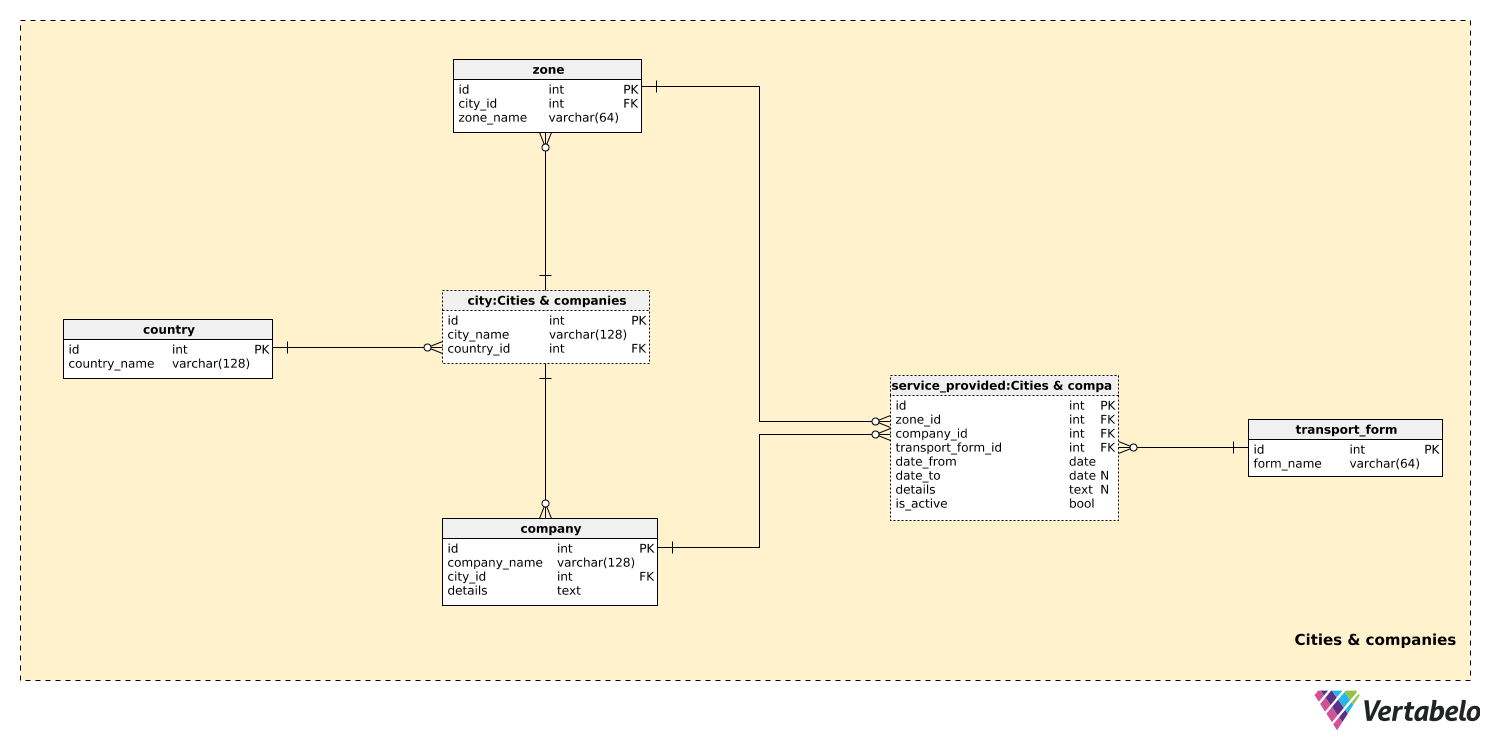
The country table contains a list of UNIQUE country_name values. This table is used only as a reference in the city table. While we can expect that our model will cover transportation in only one country, we want to have the option to include multiple countries. For each city, we’ll store the UNIQUE combination city_name – country_id.
Smaller cities will probably have only one zone, while larger cities will have multiple zones. A list of all possible zones is stored in the zone table. For each zone, we’ll store its zone_name and a reference to the relevant city. This pair forms the alternate key of this table.
We can expect that our system will store information on multiple transportation companies. Companies will issue their own tickets, but they will also be able to issue tickets jointly with other companies. For each company, we’ll store the UNIQUE combination of company_name and the city_id where it is located. Any needed additional information can be stored in the textual details field.
The last thing we need to define is the form of transportation each company provides. Some expected values are “bus”, “tram”, “underground”, and “railway”. For each value in the transport_form table, we’ll store the UNIQUE form_name.
zone_id– References thezonetable and denotes the area where this form of transportation is provided by this company.company_id– References thecompanyproviding this service in this zone.transport_form_id– References thetransport_formtable and denotes the type of service provided.date_fromanddate_to– The period during which this service was provided by this company. Note thatdate_tocan contain a NULL value if this service is still available and/or has no expected expiration date.details– All other details, in an unstructured textual format.is_active– If this service is active (ongoing) or not. This is a simple on/off switch that we can use in some cases instead of thedate_from–date_toservice activity interval. The best usage of this attribute would be to simplify queries, i.e. by testing this value instead of testing the date interval and “playing” with NULL values.
Tickets
The previous subject area was just preparation for the main thing: tickets. And that’s what this subject area will cover.
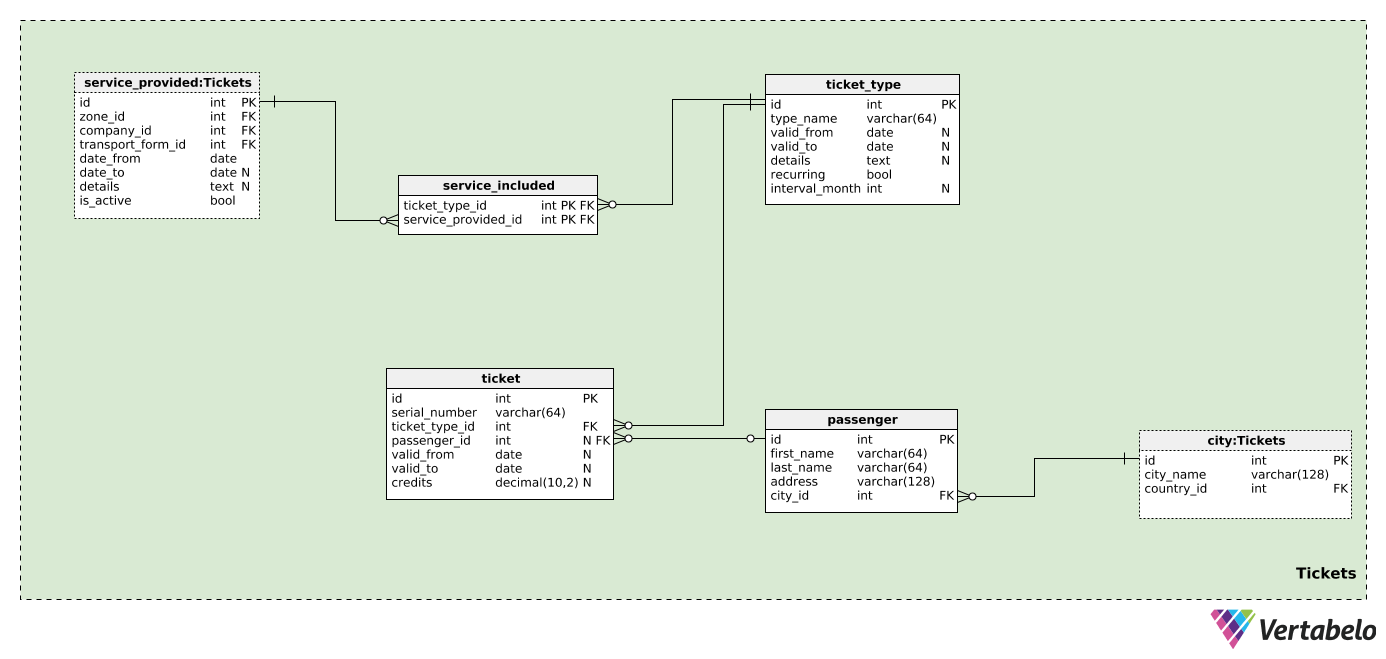
We’ve defined companies, zones, and transportation forms, but we don’t have any provision for passengers and tickets – the core of this model. We’ll assume that one ticket could be used for one or more zones covered by one or more companies.
Therefore, we first need to define each ticket_type. In this table, we’ll list all possible types of tickets being sold by the companies in our database. For each type, we’ll store the following values:
type_name– A name UNIQUELY denoting this type.valid_fromandvalid_to– The period when this ticket type is (or was) valid. Both fields are nullable; a NULL value means there is no starting (or ending) date for when this was valid.details– Any necessary details, in unstructured textual format.recurring– A flag denoting if this ticket type is recurring (e.g. yearly, monthly) or not.interval_month– If the ticket type is recurring, this attribute will contain the interval, in months, of when it recurs (e.g. “1” for a monthly ticket, “12” for a yearly ticket).
Now we’re ready to define the zones covered by each ticket type. In the service_included table, we’ll store only the UNIQUE pair ticket_type_id – service_available_id. The latter will also indicate the company and the zone where this ticket can be used. This table allows us to define multiple zones per ticket; zones could belong to different companies. Since these are predefined ticket types, each ticket type will have the zones defined here (not for each individual passenger).
We won’t store too many passenger details in this model. For each passenger, we’ll store only their first_name, last_name, address, and a reference to the city where they live. All this data will be displayed on the ticket.
The last table in our model is the ticket table. We won’t focus on single-use tickets here; rather, we’ll handle subscription and prepaid tickets. These tickets will have a balance, a validity date, or both. This could differ significantly, based on the company and its rules. If a few companies decide to issue a ticket, we could support that in this table – we’ll know all the important details. For each ticket, we’ll store:
serial_number– A UNIQUE designation for each ticket. This could be a combination of numbers and letters.ticket_type_id– References the type of that ticket.passenger_id– References the passenger, if any, who owns that ticket. In case of a prepaid ticket, there could be no owner.valid_fromandvalid_to– Denotes the period during which this ticket is valid. NULL values denote there is no lower or upper boundary.credits– The credits ( as a numerical value) currently available on that ticket. If it’s a prepaid ticket, we can assume that passengers will buy additional credits on the ticket. If the ticket is valid through the whole month (or some other time period) without any limits on use, this value could be NULL.
Improvements to the Integrated Transport Data Model
You can notice that this model has been greatly simplified. That’s because integrated transport is simply too big to be covered in one article. There are some things that I think could be changed in this model:
- Zones are too simplified; we should be able to define them more dynamically.
- We don’t cover lines (e.g. bus lines). What if they go from one zone to another, etc.?
- We don’t store ticket usage history.
- There’s no registration for companies and passengers.
All of these would lead to the fact that we’d lack important data and couldn’t make any deeper analysis. So what do you think? What does this model need? What would you add or remove? Share your ideas in the comments.
