

In the process of designing our entity relationship diagram for a database, we may find that attributes of two or more entities overlap, meaning that these entities seem very similar but still have a few differences. In this case, we may create a subtype of the parent entity that contains distinct attributes. A parent entity becomes a supertype that has a relationship with one or more subtypes.
First, let’s take a closer look at a simple class diagram.
The UML symbol for a subclass association is an open arrowhead that points to the parent class.
The subclass association line is labeled with specialization constraints. Constraints are described along two dimensions:
- incomplete/complete
- In an incomplete specialization only some instances of the parent class are specialized (have unique attributes). Other instances of the parent class have only the common attributes.
- In a complete specialization, every instance of the parent class has one or more unique attributes that are not common to the parent class.
- disjoint/overlapping
- In a disjoint specialization, an object could be a member of only one specialized subclass.
- In an overlapping specialization, an object could be a member of more than one specialized subclass.
The following diagram presents class Client.
In class Client we distinguish two subtypes: Individual and Company. This specialization is disjoint (client can be an individual or a company) and complete (these are all possible subtypes for supertype).
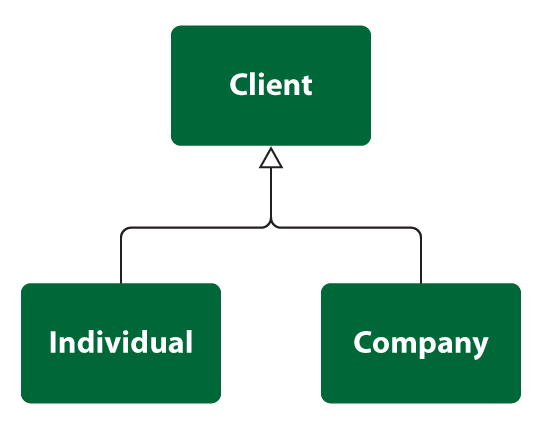
Let’s model this situation and discuss the results (I will use Vertabelo, our online database modeling tool).
One table implementation
In a one table implementation, table client has attributes of both types.
The diagram below shows the table client and two views: individual and company:
In this implementation:
- Access to supertype rows is optimal (it is simple to have a list of all clients, it’s not necessary to make costly joins)
- Effectiveness problem with access to subtype rows. Some rows have to be discarded, because one table contains rows for all (in this case two) subtypes.
- There has to be an additional attribute to specify the subtype (attribute ‘type’ may have value ‘i’ for ‘individual’ and ‘c’ for ‘company’ and no other value).
- It's easy to change the object’s subtype (we have to change ‘type’ from ‘i’ to ‘c’ or the other way around).
- Many attributes are subtype-specific, and these columns have null values on rows that apply to other subtype’s attributes.
CREATE VIEW individual AS select id, address, name, surname from client where status = 'i';
CREATE VIEW company AS select id, address, name, surname from client where status = 'c';
Two-table implementation
In a two-table implementation, we create a table for each of the subtypes. Each table gets a column for all attributes of the supertype and also a column for each attribute belonging to the subtype. Access to information in this situation is limited, that’s why it is important to create a view that is the union of the tables. We can add an additional attribute called ‘type’ that describes the subtype.
The diagram below presents two tables, individual and company, and a view (the blue one) called client.
The view’s script is as follows:
CREATE VIEW client (id, address, name, surname, company_name, industry) AS select id, address,name, surname,null, null, type from individual union all select id, address, null, null, company_name, industry, type from company;
However, the example above generates some problems:
- problem with implementation UID for supertype. There is no common ID.
- if we want to change object’s type, for example, company to client, we need to do many INSERT, DELETE operations
Three-table implementation
In a third solution we create a single table client_t for the parent table, containing common attributes for all subtypes, and tables for each subtype (individual_t and company_t) where the primary key in client_t (base table) determines foreign keys in dependent tables. There are three views: client, individual and company.
CREATE VIEW client AS select client_t.id, client_t.address, company_t.company_name, company_t.industry, individual_t.name, individual_t.surname from client_t, individual_t, company_t where client_t.id = individual_t.client_id and client_t.id = company_t.client_id;
CREATE VIEW individual AS select client_t.id, client_t.address, individual_t.name, individual_t.surname from client_t, individual_t where client_t.id = individual_t.client_id;
CREATE VIEW company AS select client_t.id, client_t.address, company_t.company_name, company_t.industry from client_t, company_t where client_t.id = company_t.client_id;
In this situation:
- it’s necessary to make (too) many (too) costly joins,
- changing the subtype is not effective,
- there is no problem with UIDs, because UIDs for subtypes are determined by the supertype’s UID.
- It’s very easy to search against all subtypes (dependent table’s foreign key is also a primary key)
