

In general, people do not like receiving unsolicited e-mails. Nevertheless, they sometimes subscribe to newsletters in order to get a discount or to keep up-to-date with new products. This article will present one approach to designing a newsletter database.
Why Worry About Newsletter Emails?
Newsletter subscribers represent an extremely valuable group of clients – they are interested in our products, they trust us, and they spend time reviewing our offers and promotions. What is more, sending emails to clients is one of the cheapest tools in online marketing. However, it needs to be done carefully – data must be updated daily (because people subscribe and unsubscribe) and be high-quality (we do not want to send unwanted emails, as it negatively impacts brand image).
So the question arises of how to manage this process of getting quality data and updating it daily. There are a lot of options ...
And the Winner Is...
Customer analytics! Nowadays, the most important factor in staying ahead of the competition is finding insights from data and making business decisions on that basis. Wouldn’t it be great to look through the history of newsletter send-outs and analyze their intensity and effectiveness? For each customer? And then join it with purchasing data, uncover the customer’s interests, prepare individual recommendations, and send these out using personalized e-mails?
Such an approach would surely increase our conversion rate (CR). The conversion rate is one of the most important online marketing key performance indicators; it shows how many people make a purchase after seeing some of our promotional material (ads, newsletters, etc). A high CR means increased business effectiveness.
Now that we understand some of the marketing involved, let’s get into the data model!
Let’s Start Modeling a Newsletter Database!
Digging right in, we see that the two main tables in the model are the client and newsletter tables.
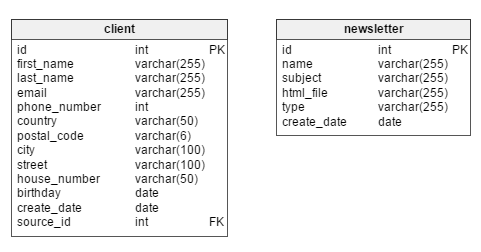
As we will be mostly interested in client analysis, the client table should stay at the center of the model. In this table, each client has their own unique id. We’ll also store such information as the client’s first_name and last_name, contact information (email, phone_number, street address), birthday, create_date (when the customer’s record was entered into the database) and their source_id – i.e. whether they registered on our site or some business partner provided us with their data.
The newsletter table stores data concerning every newsletter creation. Newsletters can be identified based on their unique id. Each is described by a name (e.g. “New women’s clothing collection – Autumn 2016”), email subject (“The most fashionable clothes for her – buy now!”), html_file (the file containing the HTML code for that particular newsletter), newsletter type (e.g. “new collection”, “birthday newsletter”) and the create_date.
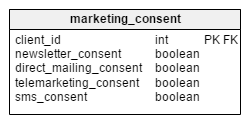
Marketing Consents
In order to send out marketing information (by post, telephone, email or SMS), a company needs to obtain consent from their customers. In our model, consents are stored in a separate table named marketing_consent. It keeps information about the current set of marketing consents for all our customers. Consents are coded as boolean variables – TRUE (agrees to marketing communication) or FALSE (does not agree).
It is very important to store information regarding when a customer agreed to receive advertisements via each communication channel. It is also beneficial to record when they withdrew their consent for each channel. For such purposes, the consent_change table was designed.
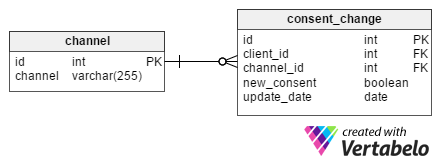
Each change has a unique id and is assigned to a particular client by their client_id. When a client requests to be removed from newsletter emails, the newsletter id from the channel table will also be stored in the consent_change table’s channel_id attribute. The new_consent attribute is a boolean value (TRUE or FALSE) and represents new marketing consents.
The update_date column holds the date when a customer requested a change. This structure allows us to extract a set of consents for all clients on a given day. It is extremely useful if a client complains about receiving an e-mail after they’d already unsubscribed from our newsletter. With this information on file, we can check when the unsubscribe took place and hopefully confirm this was done after the email newsletter had been sent.
Keeping Send-Outs In Order
Designing a perfect database model for newsletter send-outs is not a piece of cake. Why? Well, obviously we need to be able to identify any single newsletter creation (meaning layout, graphics, products, links, etc). We also know that one creation can be sent multiple times: managers may decide that one bucket of e-mails will be sent in the morning to half the clients and in the evening to the other half. So it is crucial to record which clients received which newsletter and when. This is why this part of the model consists of three tables:
- The
newslettertable – which we described earlier. - The
newsletter_sendouttable – which identifies a single send-out. For example, the Christmas newsletter (id=“2512”) was emailed out on the 10th of December at 6 p.m. This record-keeping allows marketers to send the same newsletter to separate groups of customers at different times. - The
sendout_receiverstable – which collects data about the recipients of each send-out. There will be one record for each email from each send-out. Each row has three columns:id(identifying the event of sending an email to a client),client_id(identifying clients from our database) andnl_sendout_id(identifying a newsletter send-out).
Here Is the Complete Newsletter Model:
Any ideas on how to improve this model?
One possible way is to add a response table. This would store customers’ reactions – whether they opened the e-mail, clicked on the advertisement, or never saw the message because it was marked as spam. Where should we add the response table to our model and which relation should be applied? Share your thoughts in the comment section below.
