

A recurring event, by definition, is an event that recurs at an interval; it’s also called a periodic event. There are many applications which allow their users to setup recurring events. How does a database system manage recurring events? In this article, we’ll explore one way that they are handled.
Recurrence is not easy for applications to deal with. It can become a hurricane task, especially when it comes to covering every possible recurring scenario – including creating bi-weekly or quarterly events or allowing the rescheduling of all future event instances.
Two Ways to Manage Recurring Events
I can think of at least two ways to handle periodic tasks in a data model. Before we discuss them, let’s quickly go over the requirements of this task. In a nutshell, effective management means:
- Users are allowed to create regular and recurring events.
- Daily, weekly, bi-weekly, monthly, quarterly, bi-yearly and yearly events can be created with no end date restrictions.
- Users can reschedule or cancel an instance of an event or all future instances of an event.
Considering these parameters, two ways to manage recurring events in data model come to mind. We’ll call them the naive way and the expert way.
The Naive Way: Storing all possible recurring instances of an event as separate rows in a table. In this solution, we require only one table, namely event. This table has columns like event_title, start_date, end_date, is_full_day_event, etc. The start_date and end_date columns are timestamp data types; this way they can accommodate events that don’t last all day.
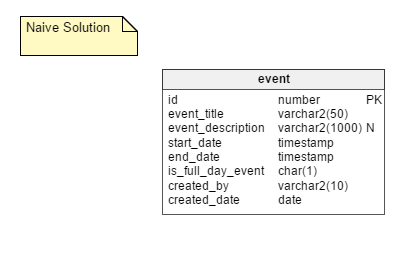
The Pros: This is quite a straightforward approach and the simplest to implement.
The Cons: The naive way has some significant downsides, including:
- The need to store all possible instances of an event. If you are taking the needs of a large user base into account then a large chunk of space is required. However, space is quite cheap, so this point has no major impact.
- A very messy updating process. Suppose an event is rescheduled. In that case, someone has to update all instances of it. Huge numbers of DML operations need to be performed when rescheduling, which creates a negative impact on application performance.
- Handling of exceptions. All exceptions must be handled gracefully, especially if you have to go back and edit the original appointment after making an exception. For example, suppose you move the third instance of a recurring event forward by one day. What if you subsequently edit the time of the original event? Do you re-insert another event on the original day and leave the one you brought forward? Unlink the exception? Try to change it appropriately?
Event_id– This column is referred from theeventtable, and it acts as the primary key in this table. It shows the identifying relationship betweeneventandrecurring_patterntables. This column will also ensure that there is a maximum of one recurring pattern extant for each event.Recurring_type_id– This column signifies the type of recurrence, whether it is daily, weekly, monthly or yearly.Max_num_of_occurrances– There are times when we do not know the exact end date for an event but we know how many occurrences (meetings) are needed to complete it. This column stores an arbitrary number that defines the logical end for an event.Separation_count– You might be wondering how a bi-weekly or bi-yearly event can be configured if there are only four possible recurrence-type values (daily, weekly, monthly, yearly). The answer is theseparation_countcolumn. This column signifies the interval (in days, weeks, or months) before the next event instance is allowed. For example, if an event needs to be configured for every other week, then separation_count = “1” to meet this requirement. The default value for this column is “0”.- The
recurring_type_idwould be “weekly”. - The
separation_countwould be “1”. - The
day_of_weekwould be “2”. Week_of_month– This column is for events that are scheduled for a certain week of the month – i.e. the first, second, last, second to last, etc. We can store these values as 1,2,3, 4,.. (counting from the beginning of the month) or -1,-2,-3,... (counting from the end of the month).Day_of_month– There are cases when an event is scheduled on a particular day of the month, say the 25th. This column meets this requirement. Likeweek_of_month, it can be populated with positive numbers ( “7” for the 7th day from the start of the month) or negative numbers ( “-7” for the seventh day from the end of the month).- The
recurring_type_idwould be “monthly”. - The
separation_countwould be “2”. - The
day_of_monthwould be “11”. - All remaining columns would be null.
- Events that occur on holidays. When a particular instance of an event occurs on a public holiday, should it be automatically moved to the working day immediately following the holiday? Or should it be automatically cancelled? In what circumstances would either of these apply?
- Conflicts between events. What if certain events (that are mutually exclusive) fall on the same day?
The Expert Way: Storing a recurring pattern and generating past and future event instances programmatically. This solution addresses the downsides of the naive solution. We’ll explain the expert solution in detail in this article.
The Proposed Model
Creating Events
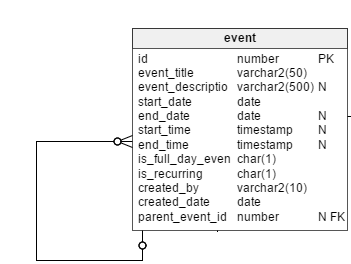
All scheduled events, irrespective of their regular or their recurring nature, are logged in the event table. Not all events are recurring events, so we’ll need a flag column, is_recurring, in this table to explicitly specify recurring events. The event_title and event_description columns store the subject and a brief summary of events. Event descriptions are optional, which is why this column is nullable.
As their names suggest, the start_date and end_date columns keep the start and end dates of events. In the case of regular events, these columns store actual start and end dates. However, they also store the dates of the first and last occurrences of periodic events. We’ll keep the end_date column as nullable, since users can configure recurring events with no end date. In this case, future occurrences up to a hypothetical end date (say for a year) would be shown in the UI.
The is_full_date_event column signifies if an event is a full-day event. In the case of a full-day event, the start_time and end_time columns would be null; that’s the reason to keep both of these columns nullable.
The created_by and created_date columns store which user created an event and the date that event was created.
Next there’s the parent_event_id column. This plays a major role in our data model. I will explain its significance later on.
Managing Recurrences
Now we come straight to the main problem statement: What if a recurring event is created in the event table – i.e. the is_recurring flag for the event is “Y”?
As explained earlier, we will store a recurring pattern for events so that we can construct all its future occurrences. Let’s start by creating the recurring_pattern table. This table has the following columns:
Let’s consider the significance of the remaining columns in terms of the different types of recurrences.
Daily Recurrence
Do we really need to capture a pattern for a daily recurring event? No, because all the details required to generate a daily recurrence pattern are already logged in the event table.
The only scenario that requires a pattern is when events are scheduled for alternate days or every X number of days. In this case, the separation_count column will help us understand the recurrence pattern and derive further instances.
Weekly Recurrence
We require only one additional column, day_of_week, to store which day of the week this event will take place. Assuming Monday is the first day of the week and Sunday is the last, possible values would be 1,2,3,4,5,6, and 7. Appropriate changes in the code that generates individual event occurrences should be made as needed. All remaining columns would be null for weekly events.
Let’s take a classic type of weekly event: the bi-weekly occurrence. In this case, we’ll say it happens every alternate week on a Tuesday, the second day of the week. So:

Monthly Recurrence
Besides day_of_week, we require two more columns to meet any monthly recurrence scenario. In brief, these columns are:
Let’s now consider a more complicated example – a quarterly event. Suppose a company schedules a quarterly result projection event for the 11th day of the first month in each quarter (usually January, April, July, and October). So in this case:
In the above example, we assume that the user is creating the quarterly result projection in January. Please note that this separation logic will start counting from the month, week, or day when the event is created.
On similar lines, half-yearly events can be logged as monthly events with a
Yearly recurrence is quite straightforward. We have columns for particular days of the week and the month, so we only require one additional column for the month of year. We’ve named this column
Now let’s come to the exceptions. What if a particular instance of a recurring event is cancelled or rescheduled? All such instances are logged separately in the Let’s take a look at two columns, Aside from these two columns, all remaining columns act the same as in the
There are applications which allow users to reschedule all future instances of a recurring event. In such cases, we have two options. We can store all future instances in With this solution, we can get all past occurrences of an event, even when its recurrence pattern has been changed. There are some more complex areas around recurring events that we haven’t discussed. Here are two: What changes do we need to make in order to build in these capabilities? Please tell us your views in the comments section.separation_count of “5”.
Yearly Recurrence
month_of_year.
Handling Exceptions of Recurring Events
event_instance_exception table. Is_rescheduled and is_cancelled. These columns signify whether this instance is rescheduled to some later date/ time or cancelled altogether. Why do I have two separate columns for this? Well, just think about events which were first rescheduled and then later completely cancelled. This happens, and we have a way of recording it with these columns. event table.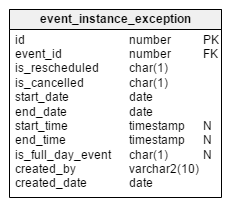
Why link two events by means of
parent_event_id?event_instance_exception (hint: not an acceptable solution). Or we can create a new event with new date/time parameters in the event table and link it with its earlier event (the parent event) by means of the id_parent_event column. How to Improve Recurring Event Handling?
