

Find out how to build an address data model for different business needs.
Address modeling in a database can be tricky: what's the best way to split the data (street, city, state, etc.)? Is normalization more critical than performance? What ERD and data modeling tools do I use? When should I use domain acronyms and values ? Will the address structure meet all the business needs? Are these decisions the best for the project?
This article analyzes several ways to model an address database and explores some relevant best practices.
Understanding Address Databases
Within a database, what is an address? The street (and house or unit number), district, city, state, country, and zip code represent the address. Often, we immediately think of normalization (separate fields for the street, neighborhood, city, country, etc.). However, is it worth it, in practice, to demand such a level of detail in the representation? With the additional complexity while searching or updating data, how will the system perform when it contains so many addresses?
To answer these questions, this article presents an address database model that will facilitate both the modeling of the structure and the creation of features such as autocompletion.
Best Practices for an Address Data Model
Modeling an address database largely depends on your goal. For example, in large projects, it is tough to escape the format of one type of data per table (i.e. one table for city, one for state, etc.) because the volume of data will require that normal forms be respected to avoid duplication and inconsistencies.
But when we are talking about smaller projects or projects where the main factor is access speed, we can disregard the normalization in favor of performance (e.g. putting the full address in a field in the user table or separating only some more critical parts, such as country and state).
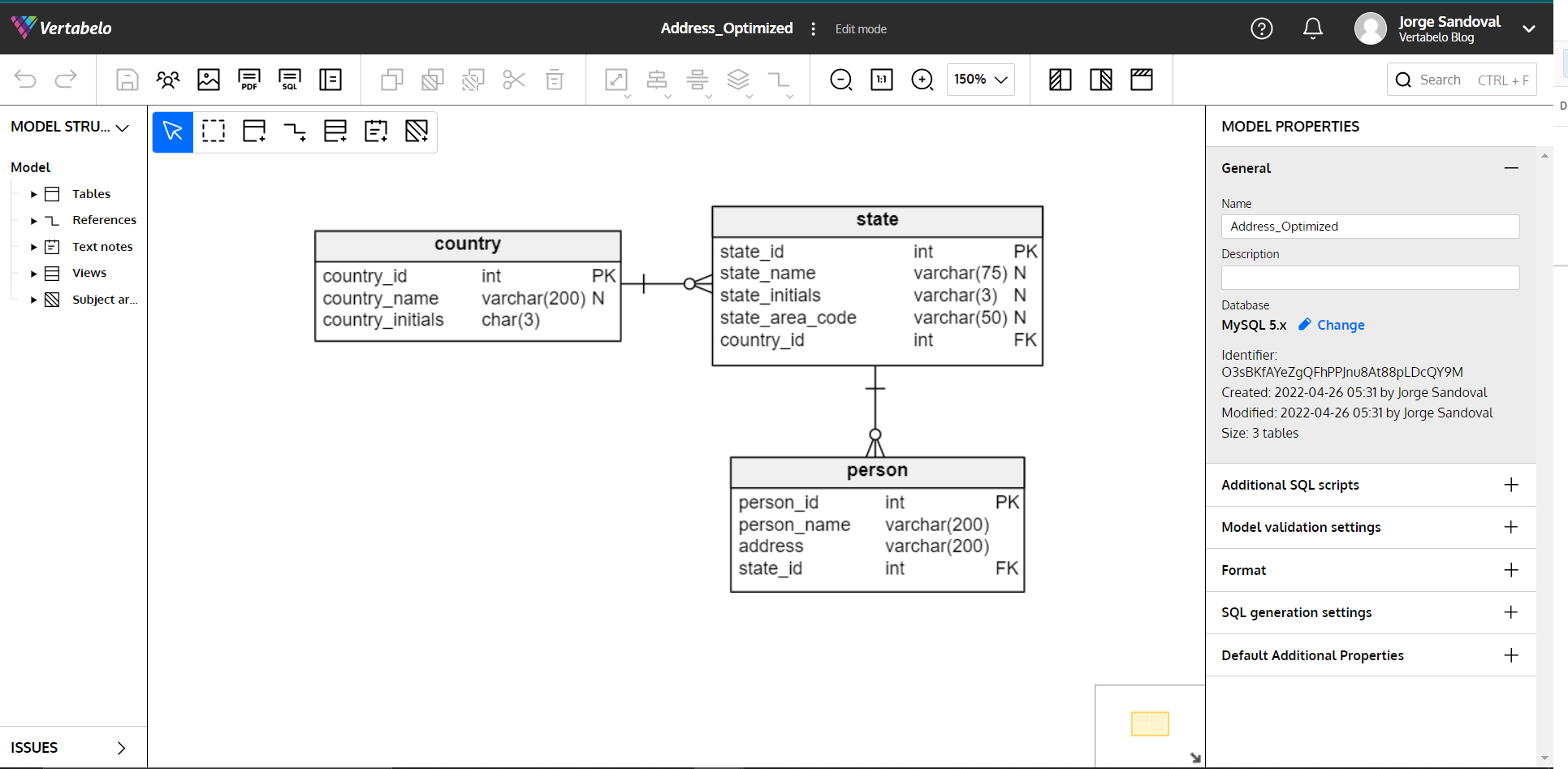
In the above model, we’ve suppressed various data in the address field, such as street, district, and city (so much so that a person is directly connected to the state where they live). While a model like this can bring up a person’s address faster, searches involving the suppressed fields become extremely difficult. This is precisely because that data was amalgamated in favor of system performance.
So, to summarize: Best practices are tied to your needs. However, the more you "synthesize" the address data into fewer tables to increase performance, the more difficult it becomes to look up that data, as it will be amalgamated and not categorized.
Structuring an Address Database
This section proposes a structure of relational tables for handling ZIP (postal) codes and registering addresses with a minimum of user intervention. It is also straightforward in producing commercial or statistical reports. Unlike the databases provided by the post office, where the focus is the query by address and ZIP code, this one is optimized for querying through ZIP code and for the extraction of data in a macro way (such as state initials or city name).
The idea is to allow you to implement self-completion using the best address database structure, modularizing your base. It's no use having a gigantic database (like the post office’s) available to our client if his business is limited to registering the customers of a neighborhood store.
We start with the country table:
CREATE TABLE `country` ( `country_id` int NOT NULL AUTO_INCREMENT COMMENT 'Country identification', `country_name` varchar(200) COMMENT 'Country name', `country_initials` char(3) NOT NULL COMMENT 'Country abbreviation', PRIMARY KEY (country_id) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='Countries and Nations';
The code above specifies the country table. This table contains three fields: the identifier (a non-repeatable numeric code), the country name, and its abbreviation (to optimize queries).
We can build the same structure for a table containing state or province data. Note that this design allows the use of three-character state abbreviations. In some countries, two-character abbreviations are used; with three spaces in the state_initials field, this database covers most of the representations of states in the world’s countries. Here’s the code:
CREATE TABLE `state` ( `state_id` int NOT NULL AUTO_INCREMENT COMMENT 'State identification', `state_name` varchar(75) DEFAULT NULL COMMENT 'Complete state name', `state_initials` varchar(3) DEFAULT NULL COMMENT 'State abbreviation', `state_area_code` varchar(50) DEFAULT NULL COMMENT 'Area code from that state', `country_id` int NOT NULL COMMENT 'Country identification', PRIMARY KEY (state_id), FOREIGN KEY (country_id) REFERENCES country (country_id) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='Federative Units (States) ';
In the code above, you can see that the state table has some differences from the country table. The identification, name, and abbreviation fields are the same and have the same functionality, but we also have the area code field and the country identifier. The area code is the telephone prefix for each state, while the country identifier is a foreign key to the country table. (Note that in some countries, most states and provinces have more than one area code.) This field is non-nullable, since every state must be part of a country.
Let’s see how the structure adapts to the city table:
CREATE TABLE `city` ( `city_id` int NOT NULL AUTO_INCREMENT COMMENT 'City identifier', `city_name` varchar(200) NOT NULL COMMENT 'City name', `state_id` int NOT NULL COMMENT 'state identifier, foreign key', PRIMARY KEY (city_id), FOREIGN KEY (state_id) REFERENCES state (state_id) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='Cities';
The city table follows a similar pattern. There’s a numeric identifier for each city, the city name, and a state identifier (non-null, since each city is part of a state). At this point, the structure follows a 3NF normalization pattern with the primary address data.
Getting deeper into address details, we now have the district table:
CREATE TABLE `district` ( `district_id` int NOT NULL AUTO_INCREMENT, `district_name` varchar(200) CHARACTER SET latin1 DEFAULT NULL, `city_id` int NOT NULL, PRIMARY KEY (district_id), FOREIGN KEY (city_id) REFERENCES city (city_id) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
Addresses follow a sequential structure. The district table is no different: a district belongs to a city, which belongs to a state, which belongs to a country. Therefore, an identifier field is created for each neighborhood in a city, followed by the neighborhood name. Districts do not usually have abbreviations or area codes, but they are part of a city, which leads to the creation of the city_id field as a foreign key to the city table. Some countries have a specific area code for each district in each state.
Now, the street table:
CREATE TABLE `street` ( `street_id` int NOT NULL AUTO_INCREMENT, `street_zip_code` varchar(9) NOT NULL, `street_type` varchar(20) DEFAULT NULL, `street_name` varchar(70) DEFAULT NULL, `district_id` int NOT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8-general-ci;
The street table is the last level of our normalized address system and describes the streets of each neighborhood. It has an identifier field, a type, and a postal area (streets in big cities usually have postal zones). A name field and a district identifier are also present. In this model, the house number is stored in the street field. In the case of multiple ZIP codes, values can be replicated (which depends a lot on the structure. If necessary, you can create a table for the ZIP codes.) The street_type field defines whether it is a street, an avenue, or an easement.
You can model address databases in several ways. However, this allows the data to be organized, and if there is a need for a report in an easy way, a view can combine them. On the other hand, there is also the possibility of putting all the data in a single table, disregarding the normalization and guaranteeing efficiency. The best choice always depends on the case.
A Sample Address Data Model
Below is the model in Vertabelo:
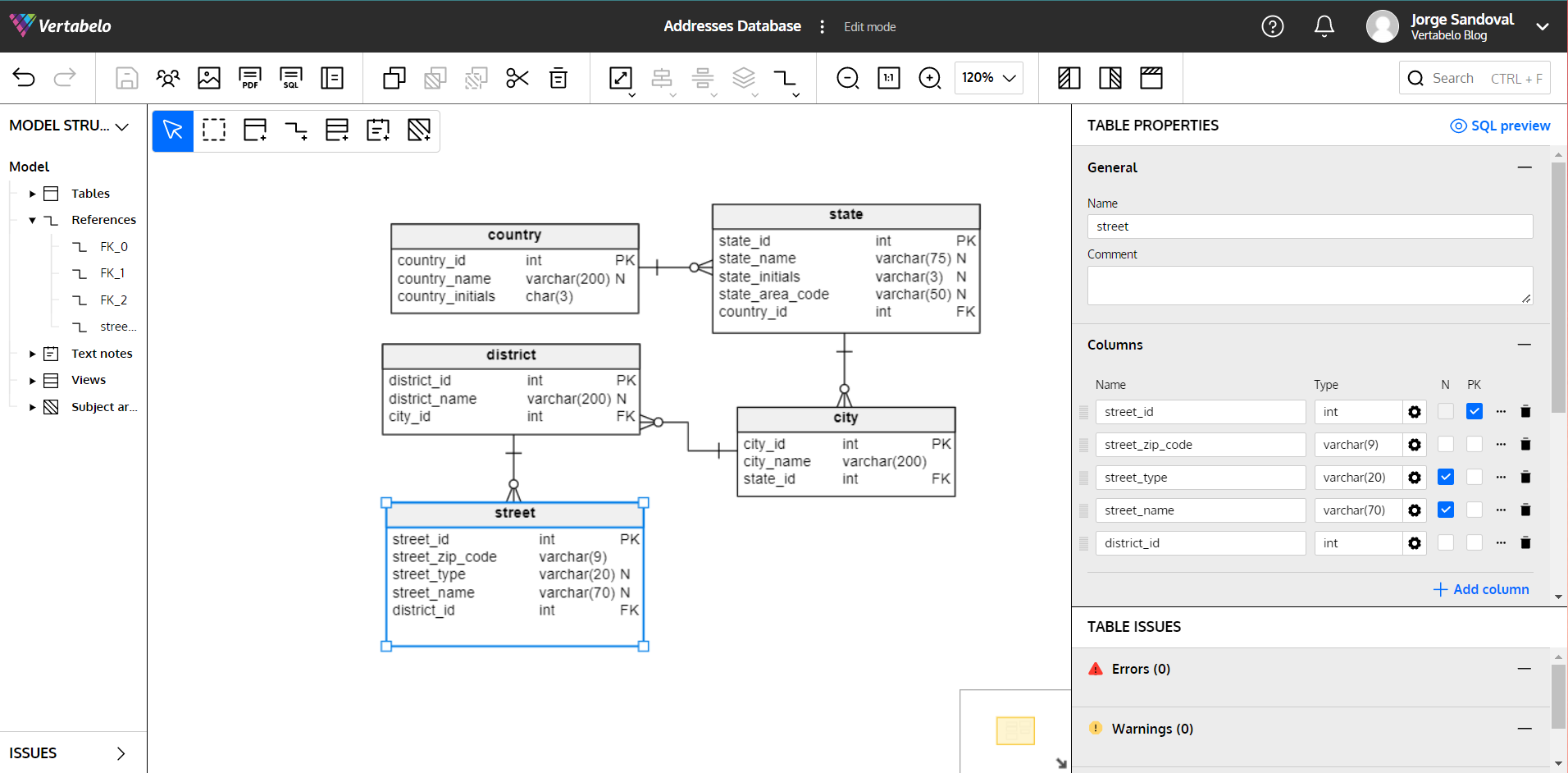
Here the model is presented via Vertabelo in its final implementation, complete with primary and foreign keys. With just five tables, we can assemble an extremely versatile address model that contains all the data in a normalized way and serves as the foundation for any system that needs an address structure.
