

What data model would allow you to comfortably search for books and borrow them in your local library?
Have you ever gone to a library and borrowed a book? Maybe that seems old-fashioned in today's world of instant internet knowledge and e-books. But I'm sure there's still this analog part of you that still likes to smell, touch, and read books. Or maybe you were forced to use a library when you couldn't find something on the internet! Yup, not everything is online.
So, how would a data model organize library books and loans? Let’s dive right into this model and see how it works!
The Data Model
I had public libraries in mind when I created this data model. There is an assumption that every library in the public library network uses the same model/system. It’s centralized and allows members to browse the collection of every library in the network. Also, members can borrow books from any library in the network.
The library data model consists of thirteen tables divided into two subject areas. Those areas are:
Books & LibrariesMembers & Loans
We’ll go through each subject area separately and analyze all the details.
Books and Libraries
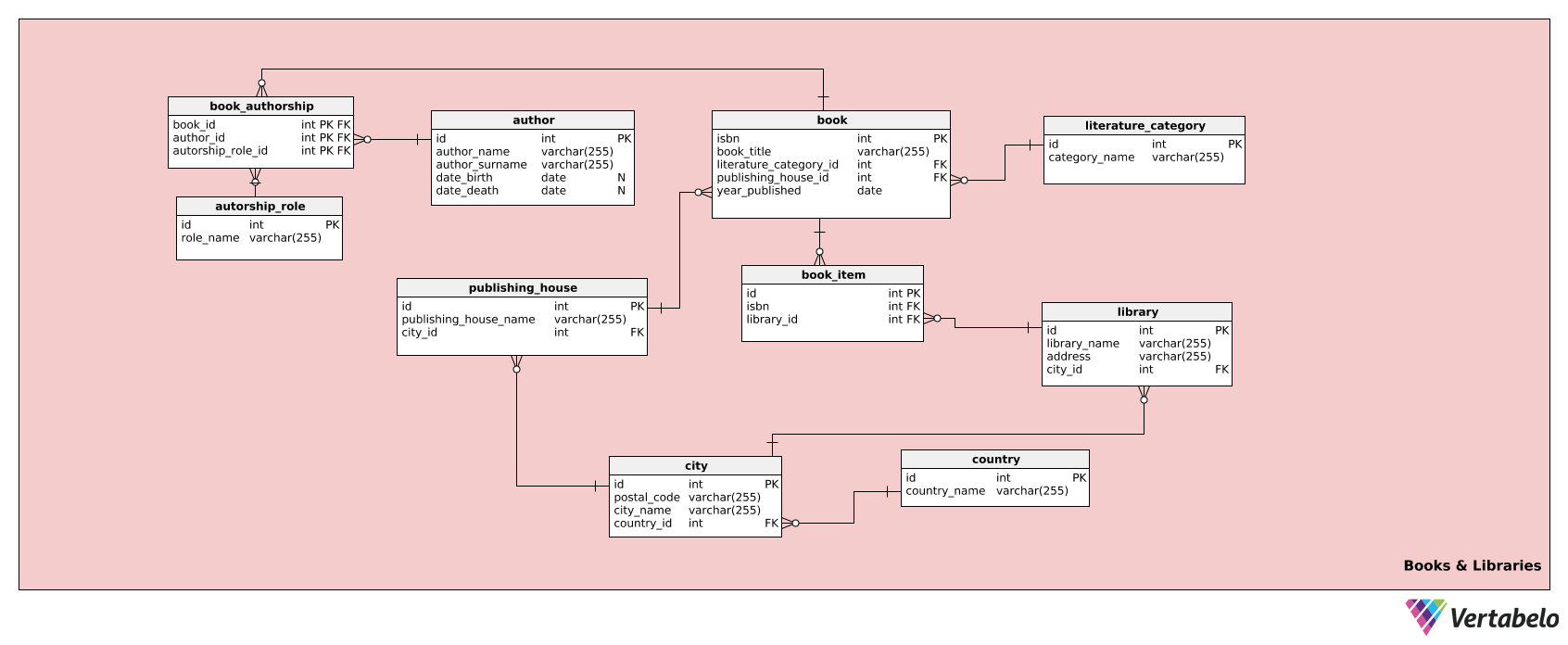
This subject area stores information about books and libraries. It consists of ten tables:
authorauthorship_roleliterature_categorybookbook_authorshipbook_itempublishing_houselibrarycitycountry
The first table is the author table. It lists all the authors (plus their relevant details) of the books that the library has in its collection. For each author, we’ll have:
id– A unique ID for that author.author_name– The first name of the author.author_surname– The last name of the author.date_birth– The author’s birth date.date_death– The date of the author's death.
The authorship_role table lists all the roles an author can have, e.g. author, co-author, etc. This table has the following attributes:
id– A unique ID for each role.role_name– The name of that role, e.g. “co-author”. This is the alternate key of the table.
The table literature_category lists all book categories, e.g. thriller, French literature, Russian realism, philosophy, etc. The table contains the following attributes:
id– A unique ID for that category.category_name– The name of the category, e.g. “mystery”. This is the alternate key of the table.
Next, we have the book table. This table stores all the relevant details of every title that the library has in its collection. Please note that this is not the table used for every book as an item. For that, we will use another table, namely the book_item table. The book table consists of the attributes:
isbn– A unique ID for each book title, which in the publishing industry is the International Standard Book Number (ISBN).book_title– The book's title.literature_category_id– References theliterature_categorytable.publishing_house_id– References thepublishing_housetable.year_published– The year when the book was published.
The next table in our model is the book_authorship table. It is an intersection table that will be connected to the book, author, and authorship_role tables. It contains the following attributes:
book_id– References thebooktable.author_id– References theauthortable.authorship_role_id– References theauthorship_roletable.
These three attributes together form the table’s composite primary key. A composite primary key means that any combination of all three attributes must be unique; each combination can occur only once.
Now let’s look at the book_item table, which we mentioned previously as storing info for each physical book in a library. It will contain the following information:
id– A unique ID for each book as an item.isbn– References thebooktable.library_id– References thelibrarytable.
The The publishing_house table is the next one in our model. It lists the publishers of all the books that the library has in its collection. The attributes in the table are as follows: table is the next one in our model. It lists the publishers of all the books that the library has in its collection. The attributes in the table are as follows:
id– A unique ID for each publishing house.publishing_house_name– The name of the publishing house (e.g. Penguin Books, McGraw-Hill, Simon & Schuster, etc.).city_id– References thecitytable. This connection will also allow us to determine both the city and the country of the publishing house. Thepublishing_house_name–city_idpair is the alternate key of this table.
Okay, let’s move on to the library table. This table is referenced in the book_item table, where it defines the library where each copy of a book is held. This is needed because the same book titles can be found in more than one library in a network (e.g. each library probably has at least one copy of The Lord of the Rings). Therefore, we have to know which book is in which library. To accomplish that, we’ll need the following attributes:
id– A unique ID for the library.library_name– The name of that library.address– The address of that library.city_id– References thecitytable. Thelibrary_name-city_idpair is the alternate key of this table.
The next table in this model is the city table. It’s a simple list of cities that we will use for information about publishers, libraries, and library members. The attributes are:
id– A unique ID for the city.postal_code– The postal code for that city.city_name– That city’s name.country_id– References thecountrytable.
After that, there is only one table left in this subject area: the country table. This is a list of all the countries where our libraries and/or book publishers are located. It consists of the following attributes:
id– A unique ID for each country.country_name– The country's name. This is the alternate key for the table.
Next, let’s examine the second subject area.
Members and Loans
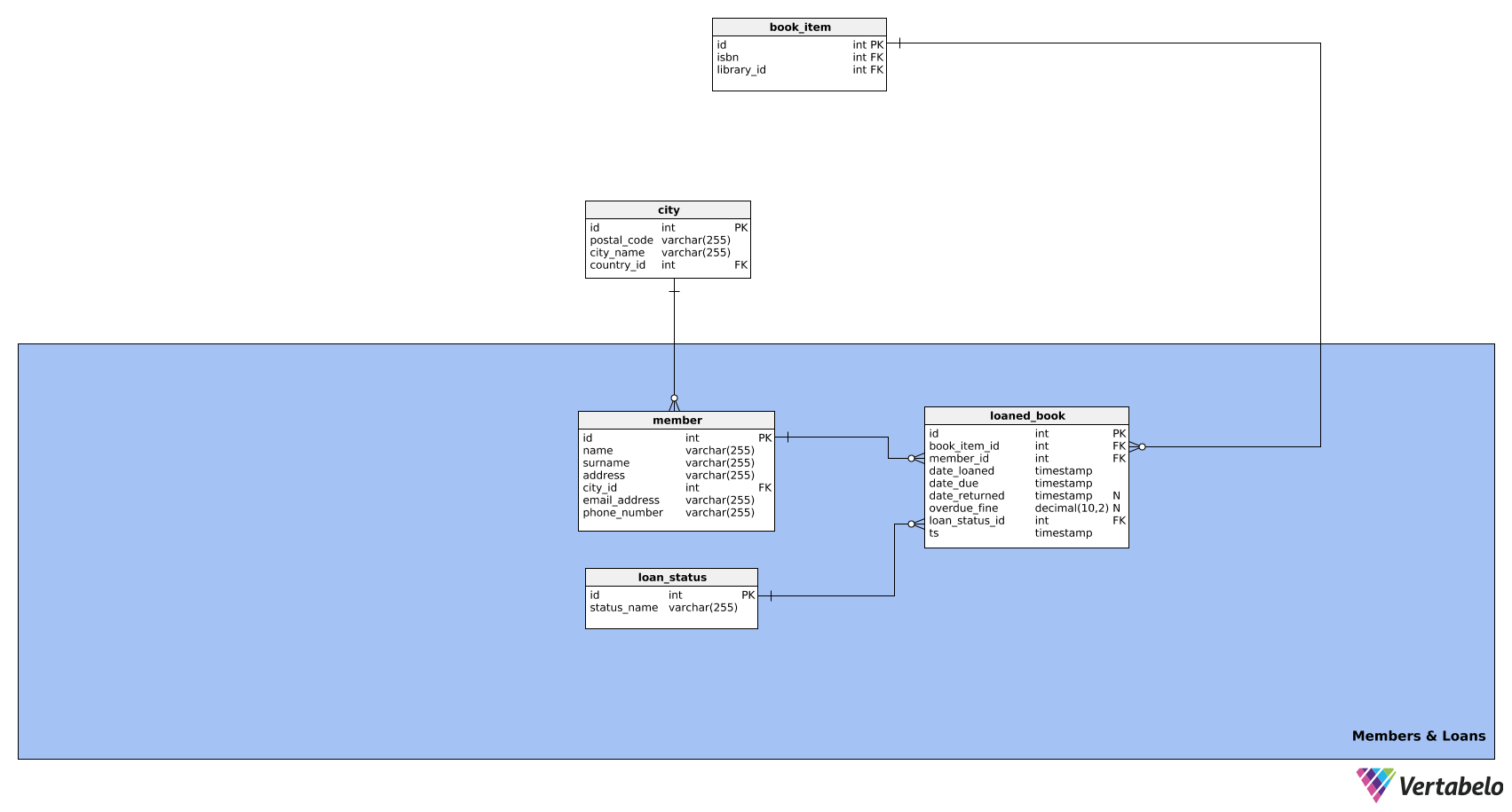
The purpose of this subject area is to manage information about library members and the books they borrow. It consists of three tables:
memberloaned_bookloan_status
Now let’s talk about the tables.
The first table in this area is the member table. It contains all the relevant info about library members. Its attributes are as follows:
id– A unique ID for each member.name– The member’s first name.surname– The member’s last name.address– The member’s address.city_id– References thecitytable.email_address– The member’s email address.phone_number– The member’s phone number.
The next table is the loaned_book table. It stores information about all the books that have ever been loaned. This way, we can keep track of the library inventory and the status of any loaned books. This table consists of the following attributes:
id– A unique ID for every loaned book.book_item_id– References thebook_itemtable.member_id– References themembertable.date_loaned– The date when this book was loaned.date_due– The date when this book should be returned.date_returned– The date when the book was actually returned to the library; this can be NULL because we will not know the date until the book is returned.overdue_fine– The late fee (if any) paid by the member, which is usually calculated based on the difference between thedate_returnedand thedate_due. This can be NULL because a book that’s returned on time has no fine.loan_status_id– References theloan_statustable.ts– The timestamp when that loan status was entered.
The loan_status table is the last one in our data model. It’s simply a list of all possible loan statuses, e.g. active, overdue, returned, etc. This table will consist of the following attributes:
id– A unique ID for every loan status.status_name– A name describing the loan status. This is the alternate key for the table.
That’s it – we’ve gone through all the details of our data model!
What Do You Think About the Library Data Model?
We’ve covered general principles in this model, so it should be (with a few tweaks) for every library. Do you know any library specifics that we missed? Or maybe you found the model useful and easily applicable? Have your say in the comments section.
